自適性查詢執行
自適性查詢執行(AQE)是在查詢執行期間進行的查詢再優化。
運行時間重新優化的動機是,Azure Databricks 在洗牌和廣播交換結束時擁有最 up-to日期準確的統計數據(稱為 AQE 中的查詢階段)。 因此,Azure Databricks 可以選擇更好的實體策略,挑選最佳的重新洗牌後的分割大小和數量,或執行原本需要提示才能進行的優化,例如偏斜聯接處理。
當統計數據集合未開啟或統計數據過時時,這非常有用。 在靜態衍生統計數據不正確的地方也很有用,例如在複雜的查詢中間,或在發生數據扭曲之後。
能力
預設會啟用 AQE。 它有 4 個主要功能:
- 動態變更將合併聯結排序為廣播哈希聯結。
- 隨機交換后,動態合併分割區(將小型分割區合併成合理大小的分割區)。 非常小型的任務具有較差的 I/O 輸送量,並且往往因排程開銷和任務設置開銷而受到更多影響。 結合小型工作可節省資源並改善叢集輸送量。
- 動態處理排序合併聯接和洗牌哈希聯接中的偏斜,方法是將具有偏斜的任務分割成大致均等大小的任務(必要時亦可複製)。
- 動態偵測並傳播空的關聯項。
應用
AQE 適用於下列所有查詢:
- 非串流
- 包含至少一個交換(通常在有聯結、匯總或視窗的情況下),或者包含一個子查詢,或兩者皆有。
並非所有 AQE 套用的查詢都必須重新優化。 重新優化可能會或可能不會生成與靜態編譯不同的查詢計劃。 若要判斷 AQE 是否已變更查詢的計劃,請參閱下一節,查詢計劃。
查詢計劃
本節討論如何以不同方式檢查查詢計劃。
在本節中:
Spark UI
AdaptiveSparkPlan 節點
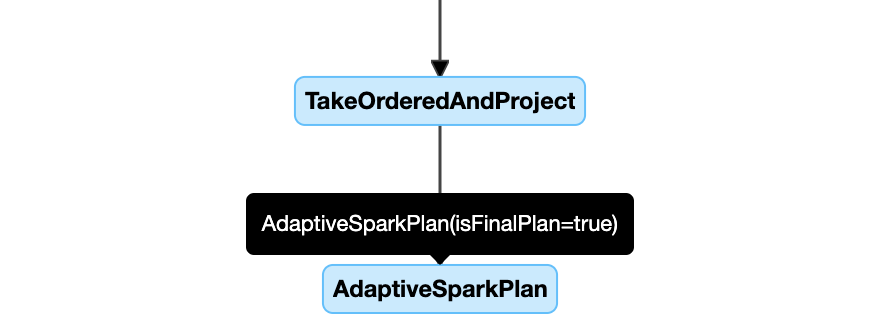
AQE 套用的查詢包含一或多個 AdaptiveSparkPlan 節點,通常是每個主要查詢或子查詢的根節點。
在查詢執行或執行之前,對應的 AdaptiveSparkPlan 節點 isFinalPlan 旗標會顯示為 false;查詢執行完成之後,isFinalPlan 旗標會變更為 true.
不斷演進的計劃
查詢計劃圖表會隨著執行進度而演進,並反映正在執行的最新計劃。 已經執行的節點(其中可用的計量)不會變化,但未執行的節點可能會隨著時間因重新優化而改變。
以下是查詢計劃圖表範例:
DataFrame.explain()
AdaptiveSparkPlan 節點
AQE 套用的查詢包含一或多個 AdaptiveSparkPlan 節點,通常是每個主要查詢或子查詢的根節點。 在查詢執行或執行之前,對應的 AdaptiveSparkPlan 節點 isFinalPlan 旗標會顯示為 false;查詢執行完成之後,isFinalPlan 旗標會變更為 true。
目前和初始計劃
在每個 AdaptiveSparkPlan 節點下,將會有初始計劃(套用任何 AQE 優化之前的計劃)和目前或最終計劃,視執行是否已完成而定。 目前的計劃會隨著執行進度而發展。
運行時間統計數據
每個洗牌和廣播階段都包含數據統計。
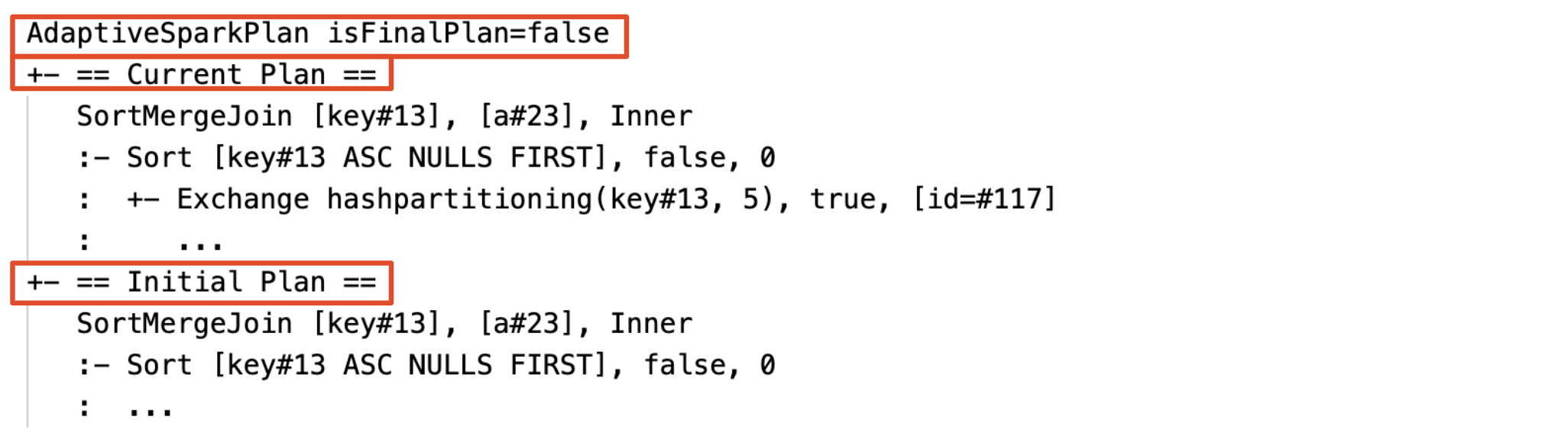
在階段執行之前或執行期間,統計數據是編譯時間估計值,而標記 isRuntime 是 false,例如:Statistics(sizeInBytes=1024.0 KiB, rowCount=4, isRuntime=false);
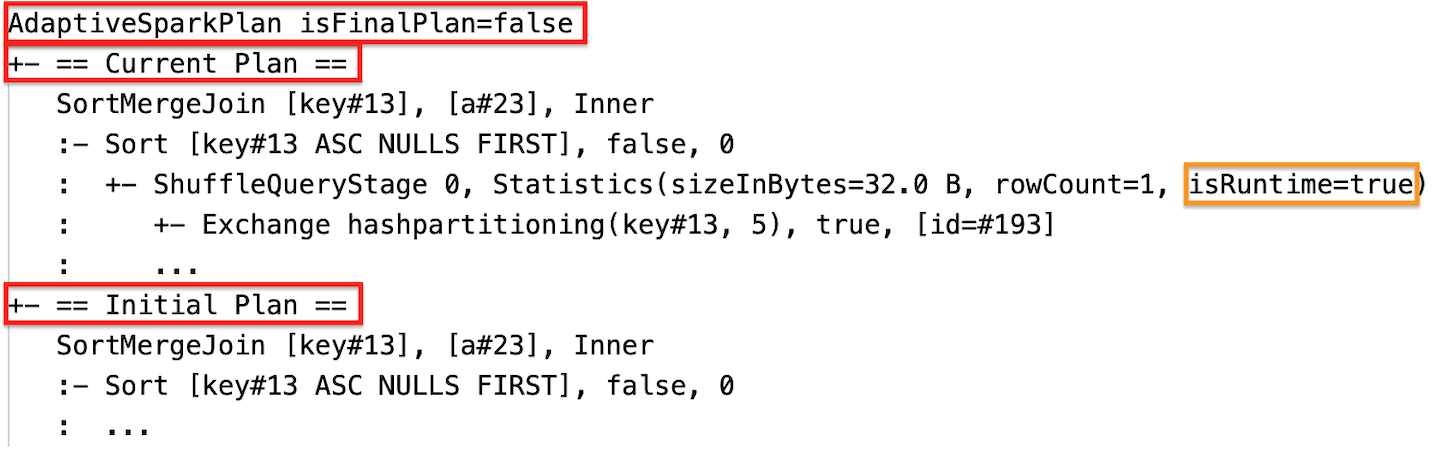
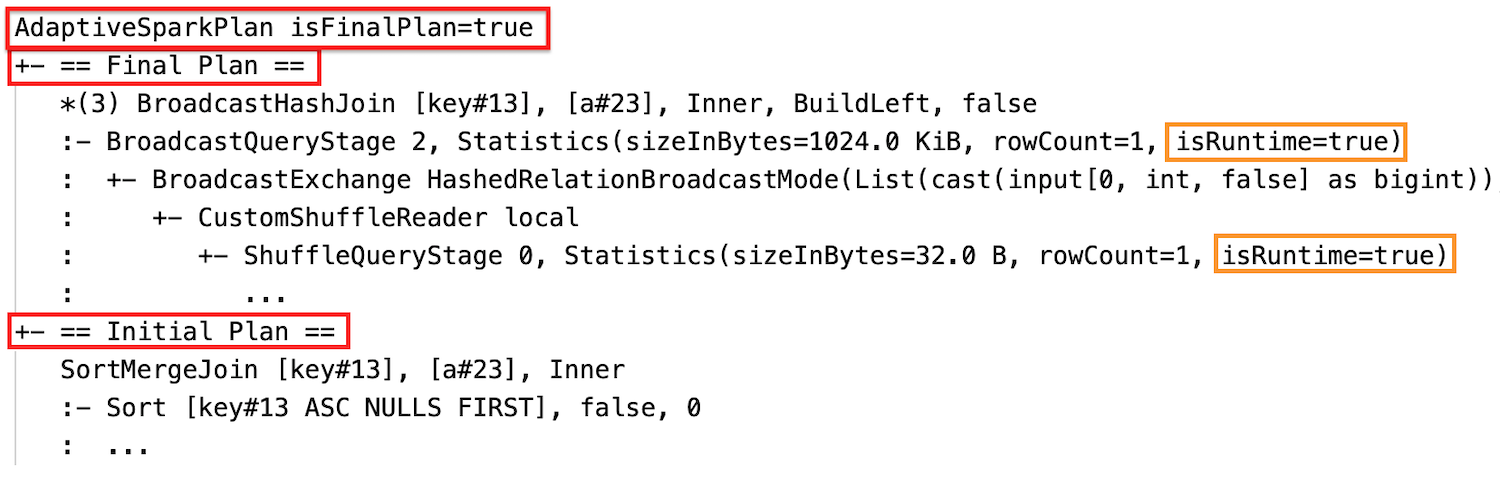
階段執行完成之後,統計數據會在運行時間收集,而旗標 isRuntime 會變成 true,例如:Statistics(sizeInBytes=658.1 KiB, rowCount=2.81E+4, isRuntime=true)
以下是 DataFrame.explain 範例:
執行之前
執行前
執行期間
執行期間
執行之後
執行後
SQL EXPLAIN
AdaptiveSparkPlan 節點
AQE 套用的查詢包含一或多個 AdaptiveSparkPlan 節點,通常是每個主要查詢或子查詢的根節點。
沒有目前的方案
由於 SQL EXPLAIN 不會執行查詢,目前的計劃一律與初始計劃相同,而且不會反映 AQE 最終會執行的專案。
以下是 SQL 說明範例:

有效性
如果一或多個 AQE 優化生效,查詢計劃將會變更。 這些 AQE 優化的效果會以目前和最終計劃與初始計劃與目前和最終方案中的特定計劃節點之間的差異來示範。
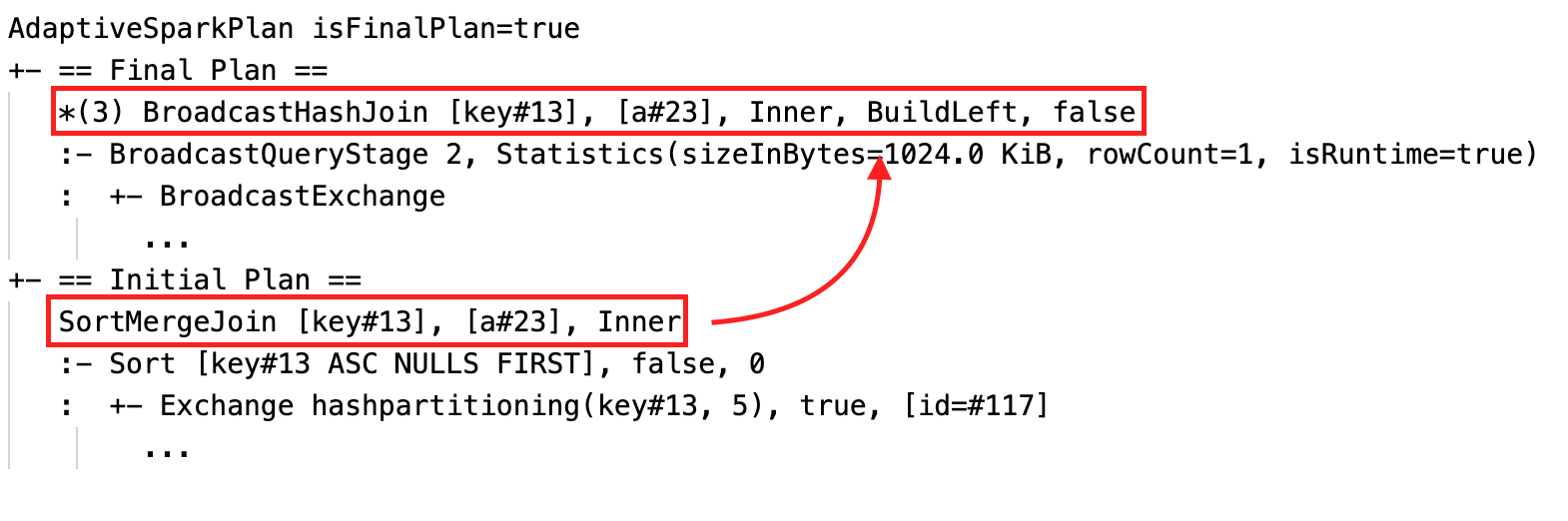
動態變更排序合併聯結成廣播哈希聯結:目前/最終計劃與初始計劃之間的不同實體聯結節點
具有屬性
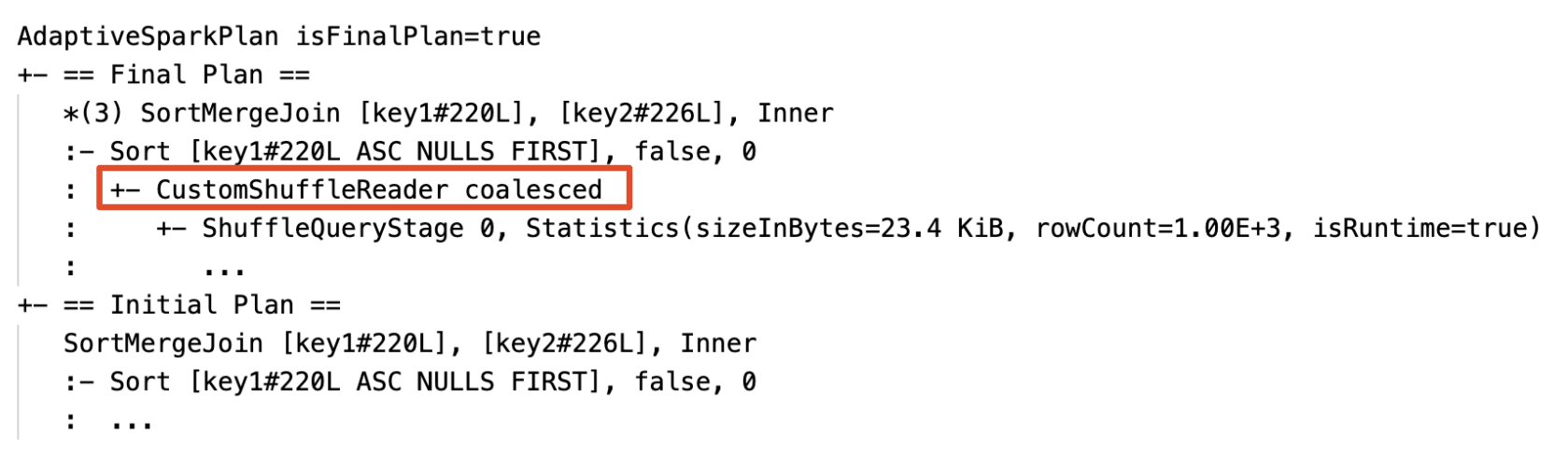
Coalesced的節點CustomShuffleReader:動態合併分區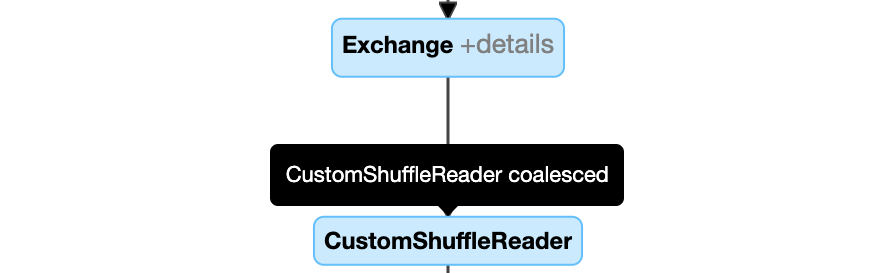
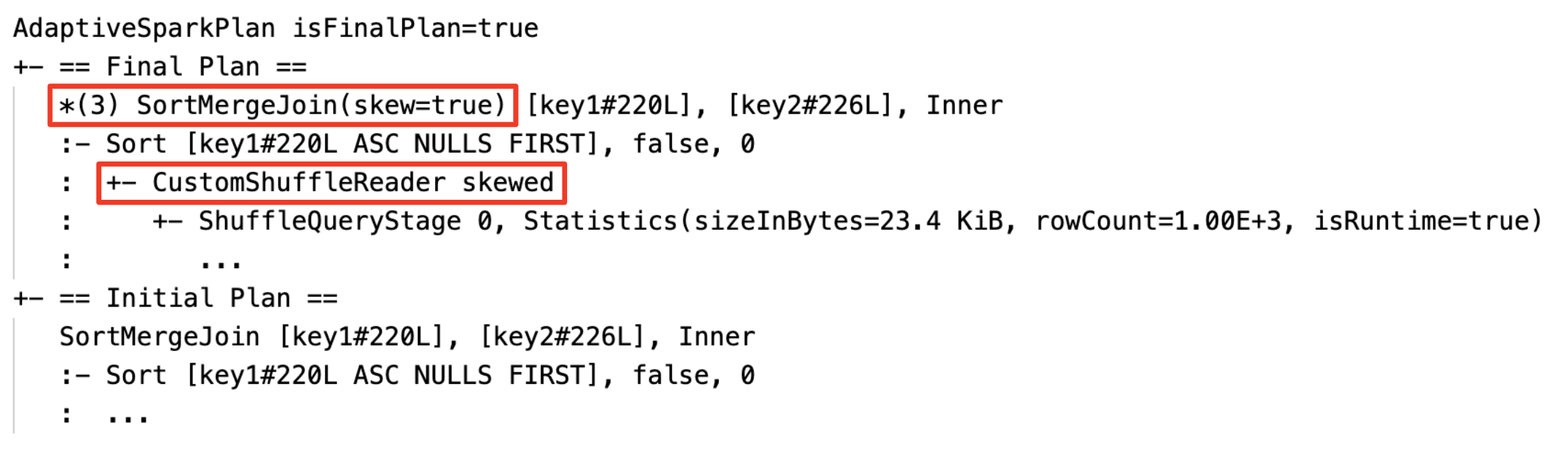
動態處理扭曲聯結:節點
SortMergeJoin,字段isSkew為 true。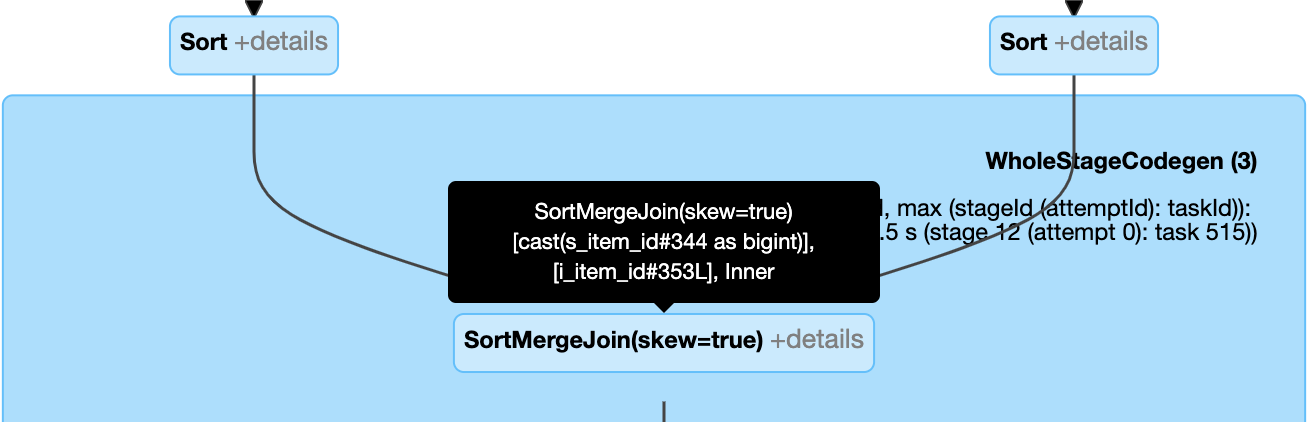
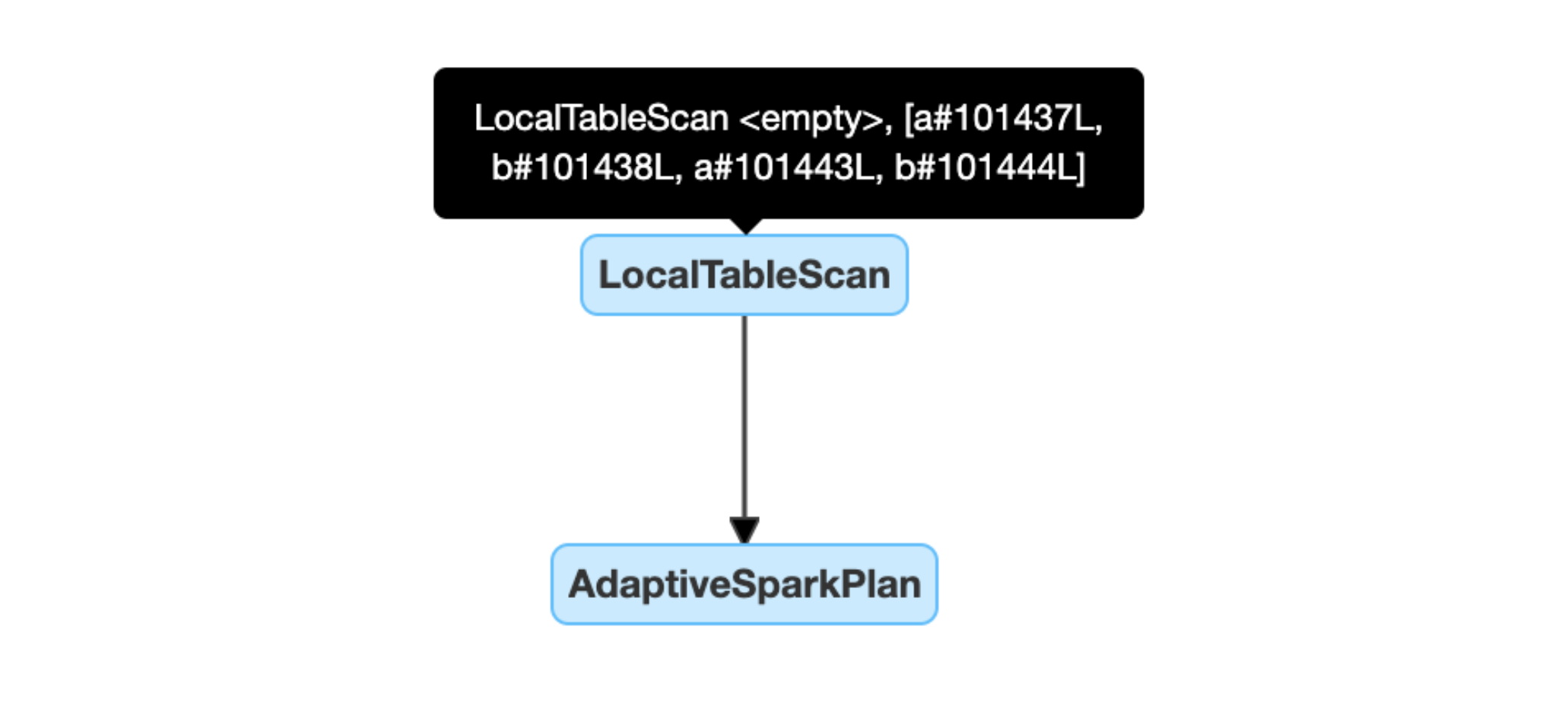
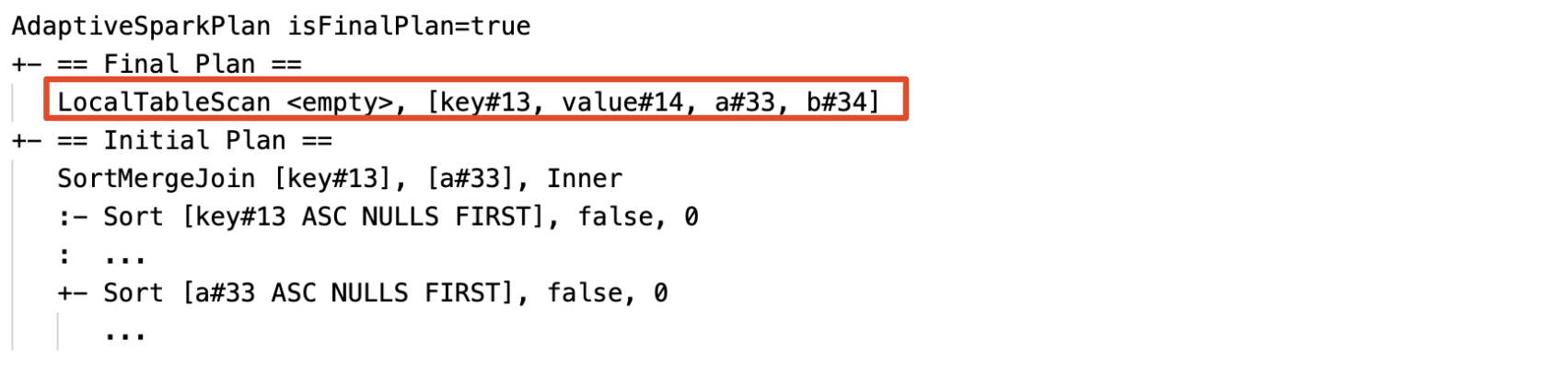
動態偵測和傳播空關聯:計劃的部分或全部將由節點 LocalTableScan 取代,且其關聯欄位為空。
配置
在本節中:
啟用和停用調適型查詢執行
| 財產 |
|---|
|
spark.databricks.optimizer.adaptive.enabled 類型: Boolean是否要啟用或停用調適型查詢執行。 默認值: true |
啟用自動優化的隨機排序
| 財產 |
|---|
|
spark.sql.shuffle.partitions 類型: Integer在重新分配用於數據聯結或聚合的資料時使用的預設分區數目。 設定值 auto 啟用自動優化的隨機排序,系統會根據查詢計劃和查詢輸入數據的大小自動決定這個數值。注意:針對結構化串流,此設定無法在查詢從相同檢查點位置重新啟動之間變更。 默認值:200 |
將排序合併聯結動態變更為廣播哈希聯結
| 財產 |
|---|
|
spark.databricks.adaptive.autoBroadcastJoinThreshold 類型: Byte String觸發切換至運行時間廣播聯結的臨界值。 默認值: 30MB |
動態合併分區
| 財產 |
|---|
|
spark.sql.adaptive.coalescePartitions.enabled 類型: Boolean是否啟用或停用分區合併。 默認值: true |
|
spark.sql.adaptive.advisoryPartitionSizeInBytes 類型: Byte String合併之後的目標大小。 合併後的分割大小將會接近目標大小,但不會超過。 默認值: 64MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionSize 類型: Byte String合併后的分割區大小下限。 合併的分區大小不會小於這個大小。 默認值: 1MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionNum 類型: Integer合併後的分區數目下限。 不建議這麼做,因為這樣會使設定被明確覆寫。 spark.sql.adaptive.coalescePartitions.minPartitionSize。預設值:2 倍於叢集核心數的數量 |
動態處理偏斜聯結
| 財產 |
|---|
|
spark.sql.adaptive.skewJoin.enabled 類型: Boolean是否啟用或停用扭曲聯結處理。 默認值: true |
|
spark.sql.adaptive.skewJoin.skewedPartitionFactor 類型: Integer乘以中位數分區大小的因素,有助於判斷分區是否偏斜。 默認值: 5 |
|
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 類型: Byte String用於判斷分割區是否失衡的臨界值。 默認值: 256MB |
當 (partition size > skewedPartitionFactor * median partition size) 和 (partition size > skewedPartitionThresholdInBytes) 都 true時,分割區會被視為扭曲。
動態偵測和傳播空白關聯
| 財產 |
|---|
|
spark.databricks.adaptive.emptyRelationPropagation.enabled 類型: Boolean是否啟用或停用動態空白關聯傳播。 默認值: true |
常見問題 (FAQ)
在本節中:
- 為什麼 AQE 不會廣播小型聯結數據表?
- 在啟用 AQE 的情況下,我是否仍應該使用廣播連接策略提示?
- 扭曲聯結提示與 AQE 扭曲聯結優化有何差異? 我應該使用哪一個?
- 為什麼 AQE 不會自動調整我的加入順序?
- 為什麼 AQE 偵測到我的數據扭曲?
為什麼 AQE 不會廣播小型聯結數據表?
如果預期要廣播的關聯大小低於此臨界值,但仍不會廣播:
- 檢查聯結類型。 某些聯結類型不支援廣播,例如,
LEFT OUTER JOIN的左關係無法廣播。 - 也可能是關係包含許多空分區,在這種情況下,大部分工作可以透過排序合併聯結快速完成,或者可能會使用傾斜聯結處理進行優化。 如果非空白分割區的百分比低於
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin,AQE 可避免將這類排序合併聯結變更為廣播哈希聯結。
在啟用 AQE 的情況下,我應該繼續使用廣播聯結策略提示嗎?
是的。 靜態規劃的廣播聯結通常比 AQE 的動態規劃更具效能,這是因為 AQE 可能會在聯結的兩側執行洗牌之後,才切換為廣播聯結(這是因為那時才會獲得實際的關聯尺寸)。 因此,如果您非常瞭解您的查詢,使用廣播提示仍然可以是不錯的選擇。 AQE 會採用與靜態優化相同的查詢提示,但仍可以套用不受提示影響的動態優化。
扭曲聯結提示與 AQE 扭曲聯結優化有何差異? 我應該使用哪一個?
建議依賴 AQE 扭曲聯結處理,而不是使用扭曲聯結提示,因為 AQE 扭曲聯結是完全自動的,而且一般執行效能優於提示對應專案。
為什麼 AQE 不會自動調整我的聯結順序?
動態聯結重新排序不是 AQE 的一部分。
為什麼 AQE 沒有偵測到我的數據偏斜?
AQE 必須滿足兩個大小條件,才能將分割區偵測為偏斜分區:
- 分割區大小大於
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes(預設值 256MB) - 此分割區大小大於所有分割區的中位數大小乘以偏斜分割因數
spark.sql.adaptive.skewJoin.skewedPartitionFactor(預設值為 5)
此外,某些聯結類型的扭曲處理支援受到限制,例如,在 LEFT OUTER JOIN中,只能優化左側的扭曲。
遺產
自 Spark 1.6 以來,已有「自適性執行」一詞存在,但 Spark 3.0 中的新 AQE 基本上不同。 就功能而言,Spark 1.6 只會執行「動態聯合分割區」部分。 就技術架構而言,新的AQE是以運行時間統計數據為基礎的動態規劃和重新規劃查詢架構,可支援各種優化,例如本文所述的優化,並可擴充以啟用更多潛在的優化。