記錄、載入和註冊 MLflow 模型
MLflow 模型是封裝機器學習模型的標準格式,可用於各種下游工具,例如 Apache Spark 上的批次推斷,或透過 REST API 提供即時服務。 此格式會定義一個慣例,可讓你將模型儲存在不同的變體中(python-function、pytorch、sklearn 等等),不同的模型服務和推論平台皆可理解。
如果要瞭解如何記錄和評分串流模型,請參閱如何儲存和載入串流模型。
記錄和載入模型
當你記錄模型時,MLflow 會自動記錄 requirements.txt 和 conda.yaml 檔案。 你可以使用這些檔案重新建立模型開發環境,並使用 virtualenv(建議)或 conda 重新安裝相依性。
重要
Anaconda Inc. 已更新其 anaconda.org 頻道的服務條款。 根據新服務條款,如果你依賴 Anaconda 的套件和散發,你可能需要商業授權。 如需詳細資訊,請參閱 Anaconda 商業版本常見問題集。 你使用任何 Anaconda 通道都會受到其服務條款的規範。
在 v1.18 之前記錄的 MLflow 模型(Databricks 執行階段 8.3 ML 或更早版本)預設會以 conda defaults 頻道(https://repo.anaconda.com/pkgs/)記錄為相依性。 由於此授權變更,針對使用 MLflow v1.18 與更高本記錄的模型 Databricks 已停止使用 defaults 頻道。 預設記錄頻道現為 conda-forge,指向社群管理的 https://conda-forge.org/。
如果你在 MLflow v1.18 之前記錄模型,但未從模型的 conda 環境排除 defaults 頻道,則該模型可能在 defaults 頻道具有你或未預期的相依性。
如果要手動確認模型是否具有此相依性,你可以針對以記錄模型封裝的 channel 檔案檢查其 conda.yaml 值。 例如,具有 conda.yaml 頻道相依性的 defaults 模型可能如下所示:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
由於 Databricks 無法判斷你與 Anaconda 的關係是否允許使用 Anaconda 存放庫來與模型互動,因此 Databricks 不會強制客戶進行任何變更。 如果 Anaconda 條款允許你透過 Databricks 使用 Anaconda.com 存放庫,則你無需採取任何動作。
如果你想要變更模型環境所用的頻道,你可以使用新 conda.yaml 重新註冊模型至模型登錄。 你可以藉由在 conda_env 的參數 log_model() 指定頻道來執行此動作。
如需 log_model() API 的詳細資訊,請參閱你正在使用模型類別的 MLflow 文件,例如 scikit-learn 的 log_model。
如需 conda.yaml 檔案的詳細資訊,請參閱 MLflow 文件。
API 命令
如果要將模型記錄至 MLflow 追蹤伺服器,請使用 mlflow.<model-type>.log_model(model, ...)。
若要載入先前記錄的模型以進行推斷或進一步開發,請使用 mlflow.<model-type>.load_model(modelpath),其中 modelpath 為下列其中一項:
- 執行相對路徑(例如
runs:/{run_id}/{model-path}) - Unity Catalog 的目錄磁碟區路徑(例如
dbfs:/Volumes/catalog_name/schema_name/volume_name/{path_to_artifact_root}/{model_path}) - 開頭為 MLflow 管理的成品記憶體路徑
dbfs:/databricks/mlflow-tracking/ -
已註冊的模型路徑(例如
models:/{model_name}/{model_stage})。
如需載入 MLflow 模型的完整選項清單,請參閱 MLflow 文件中的 參考工件。
Python MLflow 模型可透過另一個選項來使用 mlflow.pyfunc.load_model() 將模型以泛型 Python 函式的形式載入。
你可以使用下列程式碼片段來載入模型並為資料點評分。
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
或者,你可以將模型以 Apache Spark UDF 匯出,以用於在 Spark 叢集上評分,以作為批次作業或即時 Spark 串流作業。
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = input_data.withColumn("prediction", model_udf())
記錄模型相依性
如果要正確載入模型,你應該確定模型相依性已使用正確的版本載入筆記本環境。 在 Databricks Runtime 10.5 ML 和更新版本中,若 MLflow 在目前環境與模型相依性之間偵測到不相符,便會警告你。
Databricks Runtime 11.0 ML 和更新版本包含可簡化還原模型相依性的其他功能。 在 Databricks Runtime 11.0 ML 和更新版本中,針對 pyfunc 變體模型,你可以呼叫 mlflow.pyfunc.get_model_dependencies 來擷取和下載模型相依性。 此函式會傳回相依性檔案的路徑,然後你可以使用 %pip install <file-path> 進行安裝。 當你將模型以 PySpark UDF 的形式載入時,請在 env_manager="virtualenv" 呼叫中指定 mlflow.pyfunc.spark_udf。 這會還原 PySpark UDF 內容中的模型相依性,而且不會影響外部環境。
你也可以手動安裝 MLflow 1.25.0 版或更新版本,在 Databricks Runtime 10.5 或更新版本中使用此功能:
%pip install "mlflow>=1.25.0"
如需有關如何記錄模型相依性(Python 和非 Python)和成品的其他資訊,請參閱記錄模型相依性。
瞭解如何記錄模型相依性,以及模型服務的自訂成品:
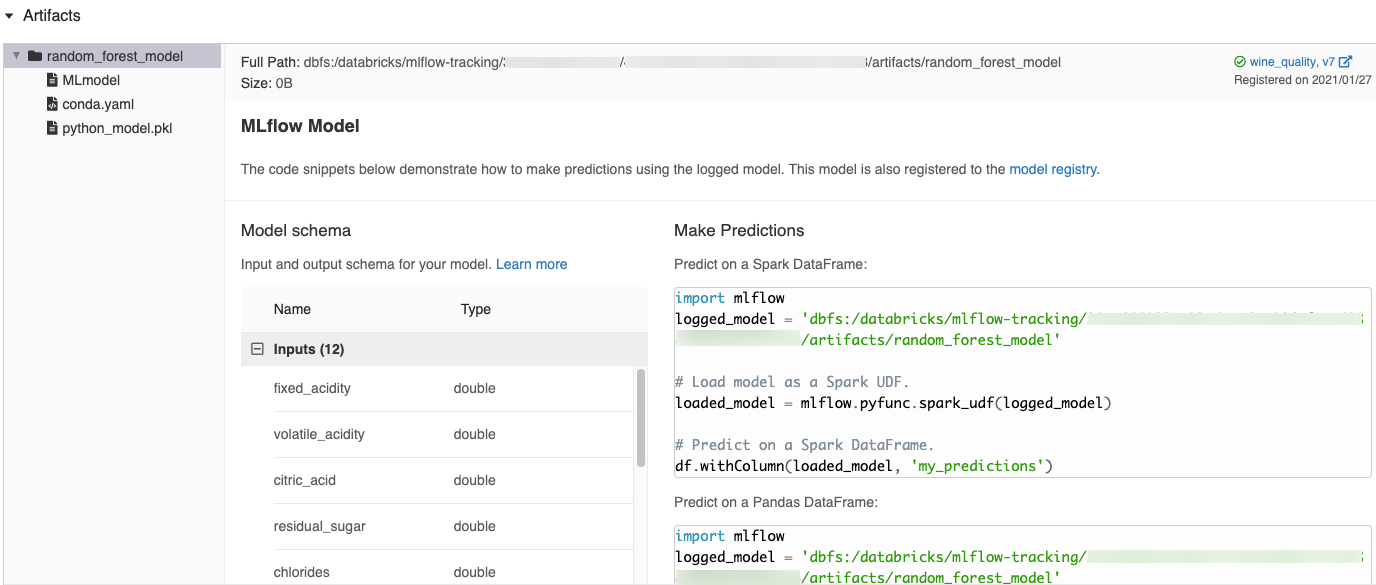
MLflow UI 中自動產生的程式碼片段
當你在 Azure Databricks 筆記本中記錄模型時,Azure Databricks 會自動產生程式碼片段,以便複製及用來載入和執行模型。 如果要檢視這些程式碼片段:
- 瀏覽至 [執行] 畫面,以取得產生模型的執行。 (請參閱檢視筆記本實驗,瞭解如何顯示 [執行] 畫面。)
- 捲動至 [成品] 區段。
- 按下記錄的模型名稱。 右側面板將隨即開啟,其中顯示可用來載入記錄模型的程式碼,並在 Spark 或 pandas DataFrame 上做出預測。
範例
如需記錄模型的範例,請參閱追蹤機器學習訓練回合範例中的範例。
在模型登錄中註冊模型
您可以在 MLflow 模型登錄中註冊模型,這是一個集中式模型存放區,可提供 UI 和一組 API 來管理 MLflow 模型的完整生命週期。 如需如何使用模型登錄來管理 Databricks Unity 目錄中模型的指示,請參閱在 Unity 目錄中管理模型生命週期
要使用 API 註冊模型,請使用 mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}")。
將模型儲存至 Unity 目錄磁碟區
如果要在本機儲存模型,請使用 mlflow.<model-type>.save_model(model, modelpath)。
modelpath 必須是 Unity Catalog 磁碟區的 路徑。 例如,如果您使用 Unity 目錄磁碟區位置 dbfs:/Volumes/catalog_name/schema_name/volume_name/my_project_models 來儲存專案工作,則必須使用模型路徑 /dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models:
modelpath = "/dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
針對 MLlib 模型,請使用 ML 管線。
下載模型成品。
你可以使用各種 API 下載已註冊模型的記錄模型成品(例如模型檔案、繪圖和計量)。
Python API 範例:
from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
model_uri = MlflowClient.get_model_version_download_uri(model_name, model_version)
ModelsArtifactRepository(model_uri).download_artifacts(artifact_path="")
Java API 範例:
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
CLI 命令範例:
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
部署線上服務的模型
注意
在部署模型之前,驗證模型是否能夠提供服務是有説明的。 請參閱 MLflow 檔,以瞭解如何在部署 之前,使用 mlflow.models.predict 來驗證模型。
使用 馬賽克 AI 模型服務,將 Unity 目錄模型登錄中註冊的機器學習模型裝載為 REST 端點。 這些端點會根據模型版本的可用性自動更新。