教學課程:部署和查詢自訂模型
本文提供使用 Mosaic AI 模型服務來部署和查詢自訂模型 (為傳統 ML 模型) 的基本步驟。 模型必須在 Unity 目錄或工作區模型登錄中註冊。
若要改為瞭解服務及部署產生式 AI 模型,請參閱下列文章:
步驟 1:記錄模型
記錄模型以用於模型服務有幾種不同的方式:
| 記錄技術 | 描述 |
|---|---|
| 自動記錄 | 當您使用 Databricks Runtime 進行機器學習時,系統會自動開啟此功能。 這是最簡單的方式,但會讓您減少控制。 |
| 使用 MLflow 的內建變體進行記錄 | 您可以使用 MLflow 的內建模型變體手動記錄模型。 |
使用 pyfunc 的自訂記錄 |
如果您有自訂模型,或在推斷前後需要額外的步驟,請使用此方式。 |
下列範例示範如何使用 transformer 類別來記錄 MLflow 模型,並指定模型所需的參數。
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=text_generation_pipeline,
artifact_path="my_sentence_generator",
inference_config=inference_config,
registered_model_name='gpt2',
input_example=input_example,
signature=signature
)
記錄模型之後,請務必檢查您的模型是否已在 Unity 目錄 或 MLflow Model Registry中註冊。
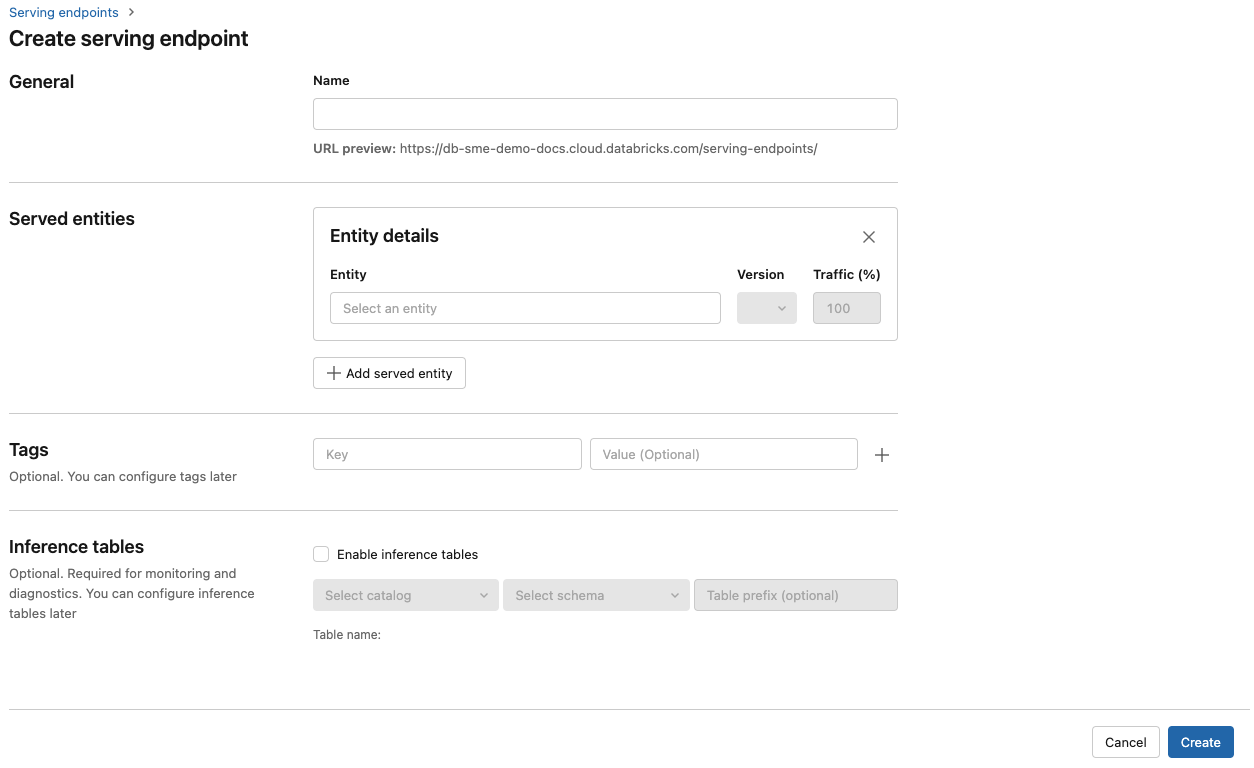
步驟 2:使用 Serving UI 建立端點
記錄已註冊的模型並準備好提供服務之後,您可以使用 [服務] UI 建立模型服務端點。
按下側邊欄的 [服務] 可顯示 [服務] UI。
按下 [建立服務端點]。
![Databricks UI 中的 [模型服務] 窗格](../../_static/images/machine-learning/serving-pane.png)
在 [名稱] 欄位中,提供端點的名稱。
在 [服務的實體] 區段中
- 點擊 [實體] 字段以開啟 [選取服務實體] 窗體。
- 選取您想要提供服務的模型類型。 表單會根據您的選擇動態更新。
- 選擇您想要提供服務的模型及其版本。
- 選取要路由傳送至您服務模型的流量百分比。
- 選取要使用的計算大小。
- 在 [計算擴展] 項目下,選擇能與此服務模型可同時處理的請求數量相匹配的計算擴展大小。 這個數字應該大致等於 QPS x 模型執行時間。
- 可用大小包括適用於 0-4 個要求的 [小型]、適用於 8-16 個要求的 [中型],以及適用於16-64 個要求的 [大型]。
- 指定端點在不使用時是否應該調整為零。
按一下 [建立]。 [服務端點] 頁面隨即出現,[服務端點狀態] 顯示為 [未就緒]。
如果您想要使用 Databricks 服務 API 以程式設計方式建立端點,請參閱建立自訂模型服務端點。
步驟 3:查詢端點
若要測試及傳送評分要求至服務模型,最簡單且最快捷的方式就是使用 Serving UI。
從 [
服務端點 ] 頁面中,選取 [查詢端點]。 以 JSON 格式插入模型輸入資料,然後按下 [傳送要求] 。 如果已透過輸入範例記錄模型,請按一下 [顯示範例] 以載入輸入範例。
{ "inputs" : ["Hello, I'm a language model,"], "params" : {"max_new_tokens": 10, "temperature": 1} }
若要傳送評分要求,請使用其中一個支援的索引鍵和對應至輸入格式的 JSON 對象來建構 JSON。 如需支援的格式和如何使用 API 傳送評分要求的指導,請參閱查詢自訂模型的服務端點。
如果您打算在 Azure Databricks Serving UI 外部存取服務端點,您需要 DATABRICKS_API_TOKEN。
重要
作為生產案例的安全最佳做法,Databricks 建議您在生產期間使用機器對機器 OAuth 權杖進行驗證。
對於測試和開發,Databricks 建議使用屬於服務主體而不是工作區使用者的個人存取權杖。 若要建立服務主體的權杖,請參閱管理服務主體的權杖。
筆記本範例
請參閱下列筆記本,以使用模型服務來服務 MLflow transformers 模型。
部署 Hugging Face transformers 模型筆記本
請參閱下列筆記本,以使用模型服務來服務 MLflow pyfunc 模型。 如需自訂模型部署的更多詳細資訊,請參閱使用模型服務部署 Python 程式碼。