模型部署模式
本文說明了兩種常見模式,用於將 ML 成品移動通過預備環境,進入生產環境。 模型和程序碼變更的異步本質表示 ML 開發程序可能會遵循多個可能的模式。
模型由程式碼所建立,但產生的模型成品和建立模型的程式碼可異步操作。 這就是說,新的模型版本和程式碼變更可能不會同時發生。 例如,想一想下列案例:
- 若要偵測詐騙交易,可開發 ML 管線,每週重新訓練模型。 程式碼可能不會經常變更,但模型可能會每週重新訓練以納入新的資料。
- 您可建立大型深度神經網路來分類文件。 在此案例中,訓練模型計算成本高昂且耗時,而且可能會不常重新訓練模型。 不過,可以在不重新訓練模型的情況下更新部署、服務及監視此模型的程式碼。
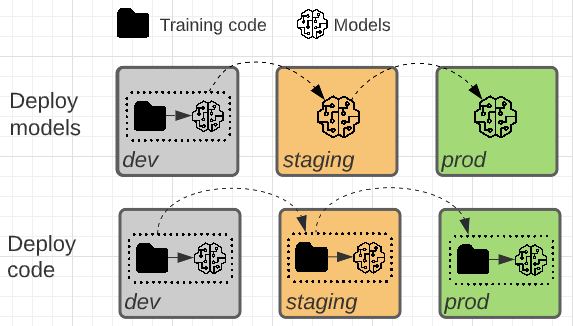
這兩種模式的差異在於模型成品或產生模型成品的訓練程式碼是否會朝生產環境升階。
部署程式碼 (建議)
在大部分情況下,Databricks 建議使用「部署程式碼」方法。 此方法會併入建議的 MLOps 工作流程。
在此模式中,開發環境中會開發要訓練模型的程式碼。 相同的程式碼會移至預備環境,然後移至生產環境。 模型會在每個環境中訓練:一開始在開發環境中作為模型開發的一部分,然後進入預備階段 (在有限的資料子集上) 作為整合測試的一部分,最後在生產環境中 (在完整生產資料上) 產生最終模型。
優點:
- 在限制生產資料存取的組織中,此模式可讓模型在生產環境中訓練生產資料。
- 自動化的模型重新訓練更安全,因為訓練程式碼已經過檢閱、測試並及核准以用於生產環境。
- 支援程式碼遵循與模型訓練程式碼相同的模式。 兩者都會在預備環境中進行整合測試。
缺點:
- 讓資料科學家將程式碼交給共同作業者的學習曲線可能很陡峭。 預先定義的專案範本和工作流程很有說明。
此外,在此模式中,資料科學家必須能夠檢閱來自生產環境的訓練結果,因為他們具備識別和修正 ML 特定問題的知識。
如果您的情況要求在完整生產資料集的預備環境中訓練模型,您可將程式碼部署至預備環境,訓練模型,然後將模型部署至生產環境,以使用混合式方法。 這種方法可節省生產環境中的訓練成本,但會在預備環境中增加額外的作業成本。
部署模型
在此模式中,模型成品是開發環境中的訓練程式碼所產生。 然後,在預備環境中測試成品,再部署到生產環境。
如果適用下列一或多個選項,則考慮此選項:
- 模型訓練非常昂貴或難以重現。
- 所有工作都在單一 Azure Databricks 工作區中完成。
- 您無法使用外部存放庫或 CI/CD 程序。
優點:
- 資料科學家提供更簡單的交接
- 如果模型訓練很昂貴,只需要將模型訓練一次。
缺點:
- 如果無法從開發環境存取生產資料 (基於安全性考慮,這可能是真的),此架構可能無法運作。
- 在此模式中,自動化的模型重新訓練很是棘手。 您可在開發環境中自動執行重新訓練,但負責在生產環境中部署模型的團隊可能無法接受產生的模型為生產就緒。
- 支援程式碼,例如用於特徵工程、推斷和監視的管線,必須單獨部署到生產環境。
一般而言,環境 (開發、預備或生產環境) 會對應至 Unity 目錄中的目錄。 如需如何實作此模式的詳細資訊,請參閱升級指南。
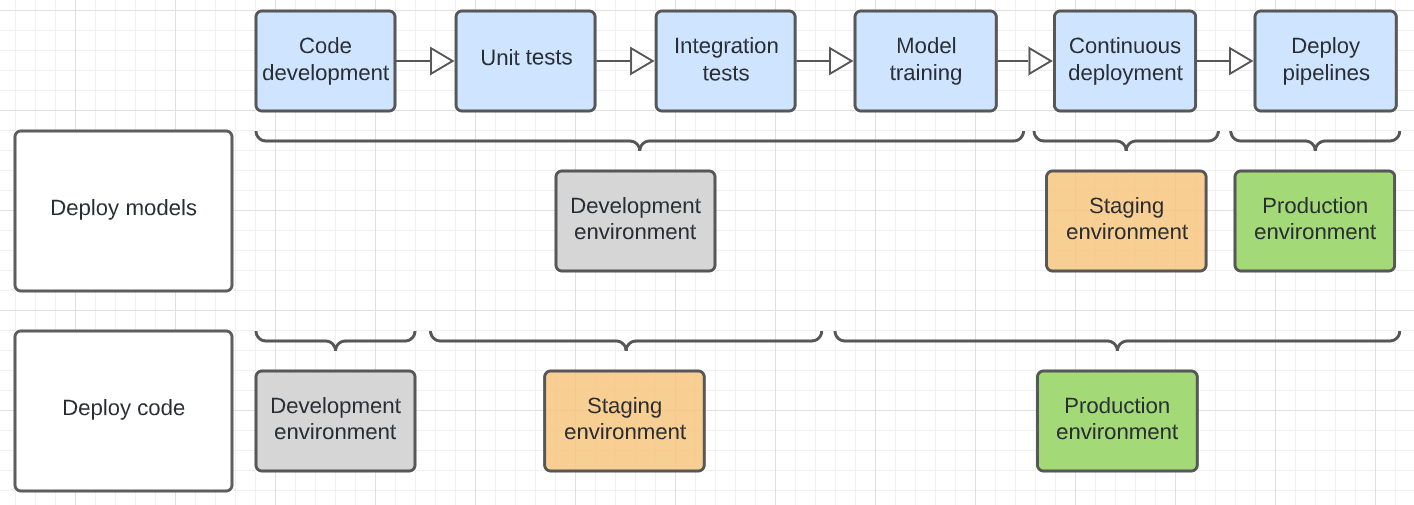
下圖對比了上述部署模式在不同執行環境下的程式碼生命週期。
圖表所示的環境是執行步驟的最終環境。 例如,在部署模型模式中,最終的單元和整合測試會在開發環境中執行。 在部署程式碼模式中,單元測試和整合測試會在開發環境中執行,最終的單元和整合測試會在預備環境中執行。