Databricks 如何支援機器學習的 CI/CD?
CI/CD(持續整合和持續傳遞)是指開發、部署、監視和維護應用程式的自動化程式。 藉由自動化建置、測試和部署程式代碼,開發小組可以比許多數據工程和數據科學小組中仍然普遍的手動程式更頻繁且可靠地提供版本。 適用於機器學習的 CI/CD 將 MLOps、DataOps、ModelOps 和 DevOps 的技術結合在一起。
本文說明 Databricks 如何針對機器學習解決方案支援 CI/CD。 在機器學習應用程式中,CI/CD 不僅對程式代碼資產很重要,而且會套用至數據管線,包括輸入數據和模型所產生的結果。
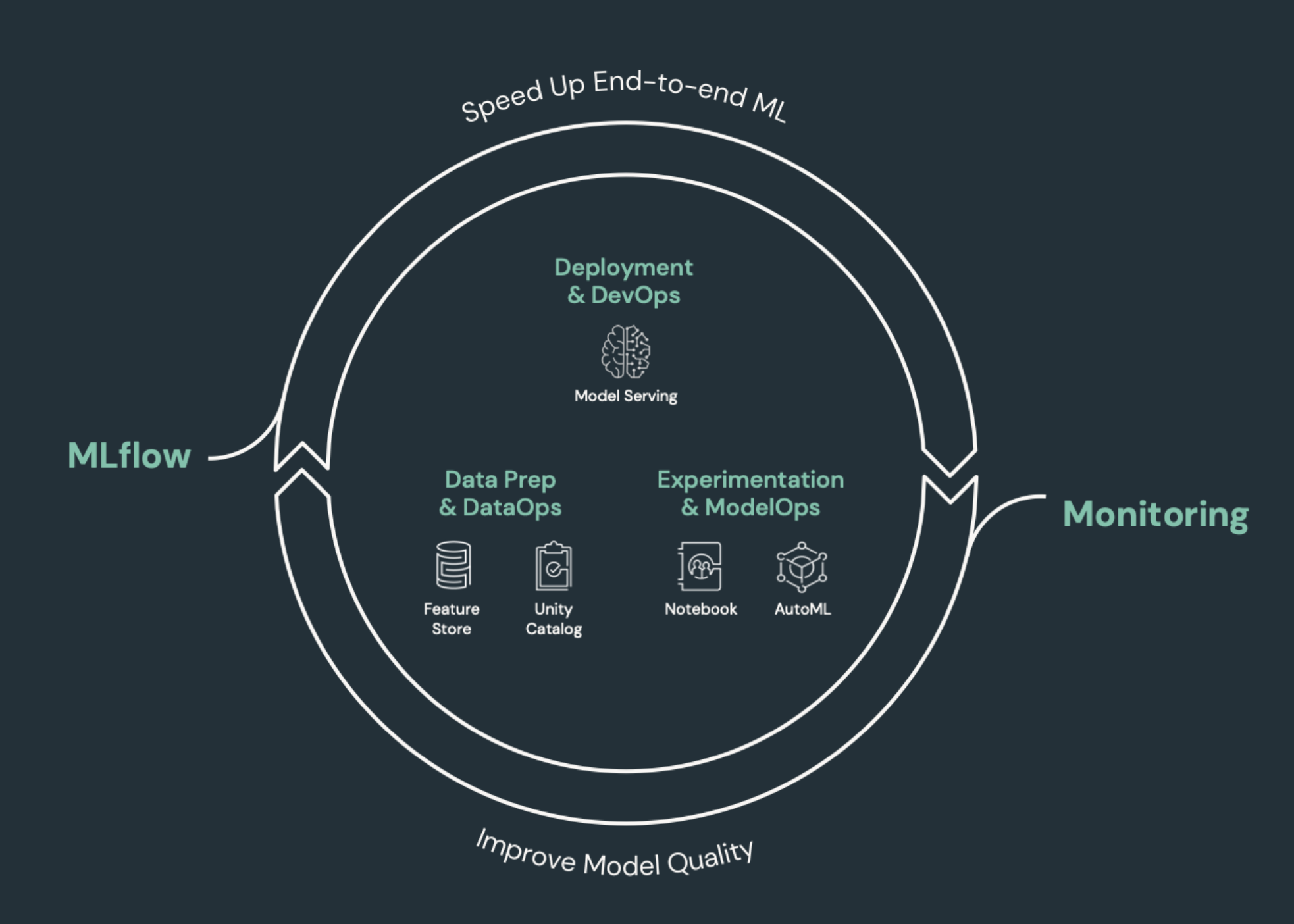
需要 CI/CD 的機器學習元素
ML 開發的挑戰之一是不同的小組擁有程式的不同部分。 Teams 可能依賴不同的工具,並有不同的發行排程。 Azure Databricks 提供單一整合的數據和 ML 平臺,其中包含整合的工具,以改善小組的效率,並確保數據和 ML 管線的一致性和重複性。
一般而言,機器學習工作應該在自動化 CI/CD 工作流程中追蹤下列專案:
- 訓練數據,包括數據品質、結構變更和分佈變更。
- 輸入數據管線。
- 定型、驗證及提供模型的程序代碼。
- 模型預測和效能。
將 Databricks 整合到 CI/CD 程式中
MLOps、DataOps、ModelOps 和 DevOps 是指開發程式與「作業」的整合,讓流程和基礎結構可預測且可靠。 這組文章說明如何將作業(“ops”) 原則整合到 Databricks 平臺上的 ML 工作流程。
Databricks 包含 ML 生命週期所需的所有元件,包括建置「設定即程式代碼」的工具,以確保重現性和「基礎結構即程式碼」,以自動化雲端服務的佈建。 它也包含記錄和警示服務,可協助您偵測並疑難解答發生問題。
DataOps:可靠且安全的數據
良好的 ML 模型取決於可靠的數據管線和基礎結構。 使用 Databricks Data Intelligence Platform 時,從內嵌數據到服務模型輸出的整個數據管線位於單一平臺上,並使用相同的工具組,有助於生產力、重現性、共用和疑難解答。

Databricks 中的 DataOps 工作和工具
下表列出 Databricks 中的一般 DataOps 工作和工具:
| DataOps 工作 | Databricks 中的工具 |
|---|---|
| 內嵌及轉換資料 | 自動載入器和 Apache Spark |
| 追蹤數據的變更,包括版本設定和譜系 | Delta 表 |
| 建置、管理及監視數據處理管線 | Delta Live Tables |
| 確保數據安全性和控管 | Unity 目錄 |
| 探勘數據分析和儀錶板 | Databricks SQL、 儀錶板和 Databricks 筆記本 |
| 一般編碼 | Databricks SQL 和 Databricks 筆記本 |
| 排程資料管線 | Databricks 工作 |
| 自動化一般工作流程 | Databricks 工作 |
| 建立、儲存、管理和探索模型定型的功能 | Databricks 功能存放區 |
| 數據監視 | Lakehouse 監視 |
ModelOps:模型開發和生命週期
開發模型需要一系列實驗,以及追蹤和比較這些實驗的條件和結果的方法。 Databricks Data Intelligence Platform 包含用於模型開發追蹤的 MLflow 和 MLflow 模型登錄,以管理模型生命週期,包括預備、服務及儲存模型成品。
將模型發行至生產環境之後,可能會變更可能會影響其效能。 除了監視模型的預測效能之外,您也應該監視輸入數據,以取得可能需要重新定型模型的品質或統計特性變更。
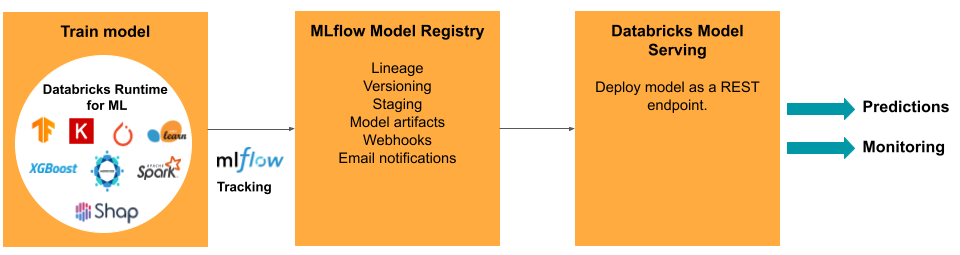
Databricks 中的 ModelOps 工作和工具
下表列出 Databricks 所提供的常見 ModelOps 工作和工具:
| ModelOps 工作 | Databricks 中的工具 |
|---|---|
| 追蹤模型開發 | MLflow 模型追蹤 |
| 管理模型生命週期 | Unity 目錄中的 模型 |
| 模型程式代碼版本控制和共用 | Databricks Git 資料夾 |
| 無程式代碼模型開發 | AutoML |
| 模型監視 | Lakehouse 監視 |
DevOps:生產與自動化
Databricks 平台支持生產環境中具有下列功能的 ML 模型:
- 端對端數據和模型譜系:從生產環境的模型回到相同平臺上的原始數據源。
- 生產層級模型服務:根據您的業務需求自動相應增加或減少。
- 作業:自動化作業並建立排程的機器學習工作流程。
- Git 資料夾:從工作區進行程式碼版本設定和共用,也可協助小組遵循軟體工程最佳做法。
- Databricks Terraform 提供者:針對 ML 推斷作業、服務端點和特徵化作業,將跨雲端的部署基礎結構自動化。
模型服務
若要將模型部署至生產環境,MLflow 可大幅簡化此程式,為大量數據或自動調整叢集上的 REST 端點提供單鍵部署作為批次作業。 Databricks 功能存放區與 MLflow 整合也可確保定型和服務的一致性:此外,MLflow 模型也可以從功能存放區自動查閱功能,即使是低延遲的在線服務也一樣。
Databricks 平台支持許多模型部署選項:
- 程序代碼和容器。
- 批次服務。
- 低延遲的在線服務。
- 裝置或邊緣服務。
- 例如,多雲端在一個雲端上定型模型,並使用另一個雲端進行部署。
如需詳細資訊,請參閱 馬賽克 AI 模型服務。
工作
Databricks 作業 可讓您自動化並排程任何類型的工作負載,從 ETL 到 ML。 Databricks 也支援與熱門的第三方 協調器整合,例如 Airflow。
Git 資料夾
Databricks 平臺包含工作區中的 Git 支援,可協助小組透過 UI 執行 Git 作業,以遵循軟體工程最佳做法。 系統管理員和 DevOps 工程師可以使用 API,透過慣用的 CI/CD 工具來設定自動化。 Databricks 支援任何類型的 Git 部署,包括專用網。
如需使用 Databricks Git 資料夾進行程式代碼開發最佳做法的詳細資訊,請參閱 使用 Git 整合和 Databricks Git 資料夾 的 CI/CD 工作流程和使用 CI/CD。 這些技術與 Databricks REST API 一起,可讓您使用 GitHub Actions、Azure DevOps 管線或 Jenkins 作業來建置自動化部署程式。
用於治理和安全性的「Unity Catalog」目錄
Databricks 平臺包含 Unity 目錄,可讓系統管理員針對 Databricks 中的所有數據和 AI 資產設定更細緻的訪問控制、安全策略和控管。