執行您自己的 LLM 端點基準評定
本文提供了 Databricks 建議的筆記本範例,用於對 LLM 端點執行基準評定。 其還簡短介紹了 Databricks 如何執行 LLM 推斷,並計算延遲和輸送量作為端點效能計量。
Databricks 上的 LLM 推斷會測量基礎模型 API 的佈建輸送量模式的每秒權杖。 請參閱佈建輸送量中的每秒權杖範圍有何含義?。
基準評定範例筆記本
您可以將下列筆記本匯入 Databricks 環境,並指定要執行負載測試的 LLM 端點的名稱。
基準評定 LLM 端點
LLM 推斷簡介
LLM 會在一個兩步驟程序中執行推斷:
- 預先填入,其中會平行處理輸入提示中的權杖。
- 解碼,其中文字會以自動迴歸的方式一次產生一個權杖。 每個產生的權杖都會附加至輸入,並會送回模型以產生下一個權杖。 當 LLM 輸出特殊停止權杖或符合使用者定義條件時,就會停止產生。
大多數的生產應用程式都有延遲預算,而 Databricks 建議您在延遲預算的情況下將輸送量最大化。
- 輸入權杖數目會對處理要求所需的記憶體產生重大影響。
- 輸出權杖的數目會主導整體回應延遲。
Databricks 會將 LLM 推斷分成下列子計量:
- 第一個權杖的時間(TTFT):這是使用者在輸入其查詢之後開始看到模型輸出的速度。 在即時互動中,回應的等候時間較短,但對於離線工作負載,則較不重要。 此計量由處理提示所需的時間驅動,然後會產生第一個輸出權杖。
- 每個輸出權杖的時間 (TPOT):為查詢系統的每個使用者產生輸出權杖的時間。 此計量會對應每位使用者如何感知模型的「速度」。 例如,每個權杖 100 毫秒的 TPOT 是每秒 10 個權杖,或每分鐘約 450 個字,讀取速度要快於一般人員。
根據這些計量,可以定義延遲總計和輸送量,如下所示:
- 延遲 = TTFT + (TPOT) * (要產生的權杖數目)
- 輸送量 = 所有並行要求中每秒輸出權杖的數目
在 Databricks 上,LLM 服務端點能夠進行調整,以讓用戶端傳送的負載可與多個並行要求相符。 延遲和輸送量之間會有所折衷。 這是因為,在 LLM 服務端點上,並行要求可以同時處理。 在低並行要求負載下,延遲是可能最低的。 不過,如果您增加要求負載,延遲可能會增加,但輸送量也可能會上升。 這是因為可以在不到兩倍的時間內處理兩個相當於每秒權杖的要求。
因此,控制系統中的平行要求數目,是平衡延遲與輸送量的核心。 如果您有低延遲使用案例,您想要將較少的並行要求傳送至端點,以保持低延遲。 如果您有高輸送量使用案例,您想要用大量並行要求讓端點飽和,因為即使要以延遲為代價,更高的輸送量也是值得的。
Databricks 基準評定工具
先前共用的基準評定範例筆記本是 Databricks 的基準評定工具。 筆記本會顯示延遲和輸送量計量,並繪製跨不同平行要求數目的輸送量與延遲曲線。 Databricks 端點自動調整是以延遲與輸送量之間的「平衡」策略為基礎。 在筆記本中,您觀測到,隨著更多並行使用者同時查詢端點,延遲和輸送量都會有所增加。
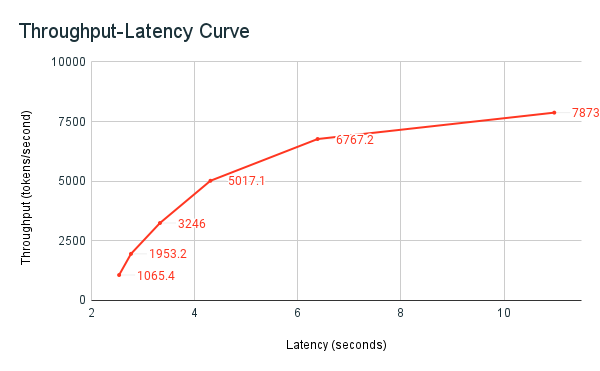
有關 LLM 效能基準評定的 Databricks 理念的詳細資料,請參閱 LLM 推斷效能工程:最佳做法部落格。