使用 Python 使用者定義的函數隨需計算特徵
本文說明如何在 Azure Databricks 中建立和使用隨需特徵。
若要使用隨需特徵,必須為 Unity Catalog 啟用您的工作區,而且您必須使用 Databricks Runtime 13.3 LTS ML 或更新版本。
什麼是隨需特徵?
「隨需」是指預先不知道其值但是在推斷時計算的特徵。 在 Azure Databricks 中,您會使用 Python 使用者定義的函數 (UDF) 來指定如何計算隨需特徵。 這些函數由 Unity Catalog 控管,可透過目錄總管探索。
需求
- 若要利用使用者定義的函數 (UDF) 來建立訓練集,或建立特徵服務端點,您必須擁有 Unity Catalog 中
USE CATALOG目錄的system權限。
工作流程
若要隨需計算特徵,您可以指定 Python 使用者定義的函數 (UDF),它描述如何計算特徵值。
- 在訓練期間,您會在
feature_lookupsAPI 的create_training_set參數中提供此函數及其輸入繫結。 - 必須使用特徵存放區方法
log_model來記錄已訓練的模型。 這可確保模型在用於推斷時,會自動評估隨需特徵。 - 針對批次評分,
score_batchAPI 會自動計算並傳回所有特徵值,包括隨需特徵。 - 當您使用 Mosaic AI Model Serving 為模型提供服務時,模型會自動使用 Python UDF 來計算每個評分要求的隨需特徵。
建立 Python UDF
您可以在筆記本或 Databricks SQL 中建立 Python UDF。
例如,在筆記本資料格中執行下列程式碼會在目錄 example_feature 和結構描述 main 中建立 Python UDF default。
%sql
CREATE FUNCTION main.default.example_feature(x INT, y INT)
RETURNS INT
LANGUAGE PYTHON
COMMENT 'add two numbers'
AS $$
def add_numbers(n1: int, n2: int) -> int:
return n1 + n2
return add_numbers(x, y)
$$
執行程式碼之後,您可以在目錄總管中瀏覽三層命名空間,以檢視函數定義:
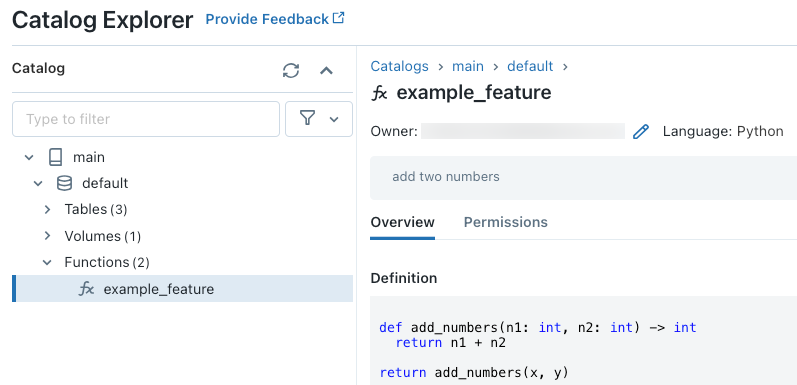
如需有關建立 Python UDF 的詳細資訊,請參閱向 Unity Catalog 註冊 Python UDF 和 SQL 語言手冊。
如何處理遺漏的特徵值
當 Python UDF 依賴於 FeatureLookup 的結果時,如果找不到要求的查閱索引鍵,則傳回的值取決於環境。 使用 score_batch 時,傳回的值為 None。 使用線上服務時,傳回的值為 float("nan")。
下列程式碼是如何處理這兩種情況的範例。
%sql
CREATE OR REPLACE FUNCTION square(x INT)
RETURNS INT
LANGUAGE PYTHON AS
$$
import numpy as np
if x is None or np.isnan(x):
return 0
return x * x
$$
使用隨需特徵訓練模型
若要訓練模型,您可以使用 FeatureFunction,它會在 create_training_set 參數中傳遞至 feature_lookups API。
下列範例程式碼會使用上一節中定義的 Python UDF main.default.example_feature。
# Install databricks-feature-engineering first with:
# %pip install databricks-feature-engineering
# dbutils.library.restartPython()
from databricks.feature_engineering import FeatureEngineeringClient
from databricks.feature_engineering import FeatureFunction, FeatureLookup
from sklearn import linear_model
fe = FeatureEngineeringClient()
features = [
# The feature 'on_demand_feature' is computed as the sum of the the input value 'new_source_input'
# and the pre-materialized feature 'materialized_feature_value'.
# - 'new_source_input' must be included in base_df and also provided at inference time.
# - For batch inference, it must be included in the DataFrame passed to 'FeatureEngineeringClient.score_batch'.
# - For real-time inference, it must be included in the request.
# - 'materialized_feature_value' is looked up from a feature table.
FeatureFunction(
udf_name="main.default.example_feature", # UDF must be in Unity Catalog so uses a three-level namespace
input_bindings={
"x": "new_source_input",
"y": "materialized_feature_value"
},
output_name="on_demand_feature",
),
# retrieve the prematerialized feature
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id'
)
]
# base_df includes the columns 'id', 'new_source_input', and 'label'
training_set = fe.create_training_set(
df=base_df,
feature_lookups=features,
label='label',
exclude_columns=['id', 'new_source_input', 'materialized_feature_value'] # drop the columns not used for training
)
# The training set contains the columns 'on_demand_feature' and 'label'.
training_df = training_set.load_df().toPandas()
# training_df columns ['materialized_feature_value', 'label']
X_train = training_df.drop(['label'], axis=1)
y_train = training_df.label
model = linear_model.LinearRegression().fit(X_train, y_train)
記錄模型並將其註冊至 Unity Catalog
封裝有特徵中繼資料的模型可註冊至 Unity Catalog。 用來建立模型的特徵資料表必須儲存在 Unity Catalog 中。
若要確保模型在用於推斷時自動評估隨需特徵,您必須設定登錄 URI,然後記錄模型,如下所示:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="main.default.model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model"
)
如果定義隨需特徵的 Python UDF 會匯入任何 Python 套件,您必須使用引數 extra_pip_requirements 來指定這些套件。 例如:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model",
extra_pip_requirements=["scikit-learn==1.20.3"]
)
限制
隨需特徵可以輸出特徵存放區支援的所有資料類型,但 MapType 和 ArrayType 除外。
筆記本範例:隨需特徵
下列筆記本示範如何訓練及評分使用隨需特徵的模型範例。
基本隨需特徵示範筆記本
下列筆記本顯示餐廳建議模型的範例。 從 Databricks 線上資料表中查閱餐廳位置。 使用者的目前位置會作為評分要求的一部分傳送。 此模型會使用隨需特徵來計算從使用者到餐廳的實時距離。 然後,該距離會用作模型的輸入。