什麼是 Medallion Lakehouse 架構?
獎章架構描述一系列數據層,代表儲存在 Lakehouse 中的數據品質。 Azure Databricks 建議採用多層式方法來建置企業數據產品的單一事實來源。
此架構保證原子性、一致性、隔離性和持久性,因為數據會先經過多層驗證和轉換,再儲存在經過優化以進行有效分析的結構中。 青銅(原始)、銀(經驗證的)、黃金(豐富的)描述每個層次的數據品質。
作為數據設計模式的 Medallion 架構
獎章架構是用來以邏輯方式組織數據的數據設計模式。 其目標是透過逐步且持續地改善數據的結構與質量,隨著數據流經整個架構的各層(從青銅層、銀層到金層的數據表)。 獎章架構有時也稱為 多躍點架構。
藉由在這些層級中推進數據,組織可以逐步提升數據的品質和可靠性,使其更適合用於商業智能和機器學習應用。
遵循獎章架構是建議的最佳做法,但並非需求。
| 問題 | 青銅 | 銀色 | 金 |
|---|---|---|---|
| 此層會發生什麼事? | 原始數據攝取 | 數據清理和驗證 | 維度模型化和匯總 |
| 誰是預定的使用者? |
|
|
|
範例獎章架構
此徽章架構範例顯示商業營運小組使用的銅層、銀層和金層。 每一層都會儲存在作業目錄的不同架構中。
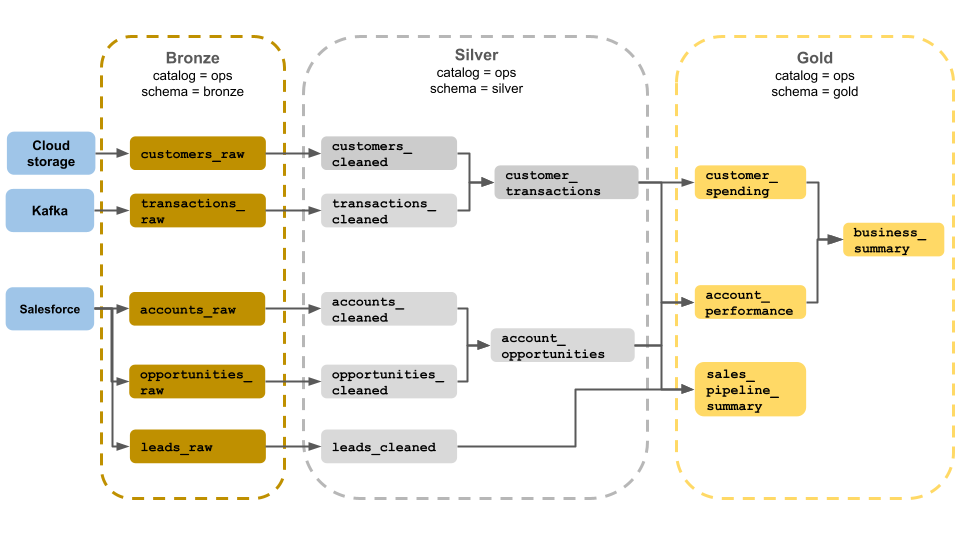
-
銅層 (
ops.bronze):從雲端記憶體、Kafka 和 Salesforce 擷取原始數據。 此處不會執行任何資料清除或驗證。 -
銀層 (
ops.silver): 資料清除和驗證會在這一層中執行。- 客戶和交易的相關資料會藉由移除空值並隔離無效的記錄來進行清理。 這些數據集會聯結至名為
customer_transactions的新數據集。 數據科學家可以使用此數據集進行預測性分析。 - 同樣地,Salesforce 中的帳戶和商機數據集會聯結以建立
account_opportunities,並進一步用帳戶資訊加以增強。 - 數據
leads_raw在名為leads_cleaned的數據集中被清理。
- 客戶和交易的相關資料會藉由移除空值並隔離無效的記錄來進行清理。 這些數據集會聯結至名為
-
金層 (
ops.gold):是專為商務用戶所設計。 它包含的數據集比銀級和金級少。-
customer_spending:每位客戶的平均和總支出。 -
account_performance:每個帳戶的每日表現。 -
sales_pipeline_summary:端對端銷售流程的相關資訊。 -
business_summary:提供給主管人員的高度匯總資訊。
-
擷取原始數據至銅層
銅層包含未經評估的原始數據。 在銅層中擷取的數據通常具有下列特性:
- 以原始格式包含並維護數據源的原始狀態。
- 會以累加方式附加,並隨著時間成長。
- 適用於擴充銀表數據的工作負載取用,而不是供分析師和數據科學家存取。
- 做為單一事實來源,保留數據的精確度。
- 藉由保留所有歷史數據來實現重新處理和稽核。
- 可以是來自來源的串流和批次交易的任何組合,包括雲端物件儲存區(例如 S3、GCS、ADLS)、訊息總線(例如 Kafka、Kinesis 等),以及同盟系統(例如 Lakehouse 同盟)。
限制數據清除或驗證
在銅層中執行最少量的資料驗證。 為了防止數據遺失,Azure Databricks 建議將大多數欄位儲存為字串、VARIANT 或二進位,以預防非預期的架構變更。 可能會新增元數據行,例如數據的來源或數據源(例如,_metadata.file_name )。
驗證和去重銀層中的數據
數據清除和驗證會在銀層中執行。
從青銅層製作銀桌子
若要建置銀層,請讀取一個或多個銅層或銀層的資料表,並將資料寫入銀層的資料表。
Azure Databricks 不建議在資料引入階段直接寫入銀表。 如果您直接從匯入過程寫入,可能會引發因資料來源中的架構變更或損毀的記錄而導致的失敗。 假設所有來源皆為僅附加的,在配置讀取銅級(Bronze)資料時,大部分應設為串流讀取。 批次讀取應該保留給小型數據集(例如小型維度數據表)。
銀層代表已驗證、清除和擴充的數據版本。 銀層:
- 應該一律至少為每個記錄包含一個經過驗證的非匯總表示。 如果匯總表示法驅動許多下游工作負載,這些表示法可能位於銀層中,但通常是在金層中。
- 這是您執行資料清理、重複資料刪除和正規化的位置。
- 藉由更正錯誤和不一致來增強數據品質。
- 將數據結構為更消耗性的格式以供下游處理。
確保數據品質
以下操作會在銀色表格中執行:
- 架構強制執行
- 處理空值和缺失值
- 重複資料刪除
- 解決無序和延遲到達的數據問題
- 數據品質檢查和強制執行
- 架構演進
- 類型轉換
- 連結
開始模型化數據
在銀層中開始執行數據模型很常見,包括選擇如何代表高度巢狀或半結構化的數據:
- 使用
VARIANT數據類型。 - 使用
JSON字串。 - 建立結構、地圖和陣列。
- 扁平化架構或將數據正規化為多個數據表。
使用金層進行電源分析
黃金層代表資料的高度精煉視圖,這些視圖可驅動下游分析、儀錶板、機器學習和應用程式。 黃金層數據通常會高度匯總,並篩選特定時段或地理區域。 其中包含對應至商務功能和需求的語意有意義的數據集。
金層:
- 由針對分析和報告量身打造的匯總數據所組成。
- 符合商業規則和需求。
- 已優化效能,以便在查詢及儀錶板中使用。
符合商業規則和需求
金層是您將數據建模的地方,使用維度模型來建立關係和定義指標,以便用於報告和分析。 具有黃金數據存取權的分析師應該能夠找到領域特定數據並回答問題。
由於金層會建立商務領域模型,因此有些客戶會建立多個金層,以滿足不同的業務需求,例如 HR、財務和 IT。
建立針對分析和報告量身打造的匯總
組織通常需要為平均值、計數、最大值和最小值等量值建立聚合函數。 例如,如果您的企業需要回答有關每周總銷售額的問題,您可以建立稱為 weekly_sales 具體化檢視,以預先匯總此數據,讓分析師和其他人員不需要重新建立常用的具體化檢視。
CREATE OR REPLACE MATERIALIZED VIEW weekly_sales AS
SELECT week,
prod_id,
region,
SUM(units) AS total_units,
SUM(units * rate) AS total_sales
FROM orders
GROUP BY week, prod_id, region
優化查詢與儀表板的效能
優化金層數據表以提高最佳效能是一個最佳作法,因為這些數據集經常被查詢。 大量的歷史數據通常會在斜體層中存取,而不會在金層中具體化。
藉由調整數據擷取的頻率來控制成本
藉由判斷擷取數據的頻率來控制成本。
| 數據擷取頻率 | 成本 | 延遲 | 宣告式範例 | 程式範例 |
|---|---|---|---|---|
| 持續漸進式導入 | 較高 | 下 |
|
|
| 已觸發的增量擷取 | 降低 | 較高 |
|
|
| 批次匯入與手動增量匯入 | 降低 | 因為執行次數極少,所以等級最高。 |
|