AI 開發中的 RAG 簡介
本文介紹擷取擴增產生 (RAG):其本質、運作方式和關鍵概念。
什麼是「擷取擴增產生」?
RAG 是一種技術,可以讓大型語言模型(LLM)藉由從外部資訊來源擷取的支援數據來豐富使用者的提示,從而產生更加充實的回應。 藉由納入此擷取的資訊,RAG 可讓 LLM 產生更精確、更高品質的回應,而不是使用其他內容來增強提示。
例如,假設您正在建置問答聊天機器人,以協助員工回答有關公司專屬文件的問題。 如果沒有專門訓練,獨立 LLM 將無法準確回答有關這些文件內容的問題。 LLM 可能會因為缺乏資訊而拒絕回答,或者更糟的是,它可能會產生不正確的回應。
RAG 會先根據使用者的查詢從公司文件擷取相關資訊,然後將擷取的資訊提供給 LLM 作為其他內容,來解決此問題。 這可以讓 LLM 從相關文件中找到的特定細節中提取信息,以生成更精確的回應。 從本質上講,RAG 可讓 LLM「諮詢」擷取的資訊來制定答案。
RAG 應用程式的核心元件
RAG 應用程式是複合式 AI 系統的範例:其與其他工具和程序結合來擴充模型本身的語言功能。
使用獨立 LLM 時,使用者將要求 (如問題) 提交給 LLM,而 LLM 僅根據訓練資料回應答案。
在最基本的形式中,下列步驟在 RAG 應用程式中執行:
- 擷取:使用者的要求可用於查詢某些外部資訊來源。 這可能表示查詢向量存放區、對某些文字執行關鍵字搜尋,或查詢 SQL 資料庫。 擷取步驟的目標是取得支援資料,以協助 LLM 提供有用的回應。
- 擴增:擷取步驟中的支援資料與使用者的要求結合,通常使用具有其他格式和 LLM 指示的範本來建立提示。
- 產生:產生的提示將傳遞至 LLM,而 LLM 將產生對使用者要求的回應。
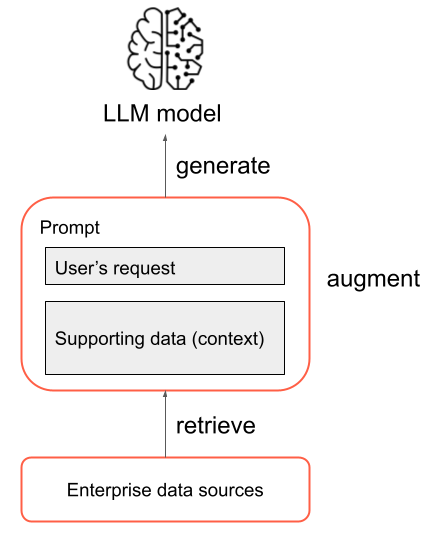
這是 RAG 程序的簡化概觀,但請務必注意,實作 RAG 應用程式涉及許多複雜的工作。 預先處理來源資料使其適用於 RAG、有效擷取資料、格式化擴增提示以及評估產生的回應,這些都需要仔細考慮和精力。 本指南稍後章節將更詳細地討論這些主題。
為何要使用 RAG?
下表概述使用RAG與獨立 LLM 的優點:
| 僅使用 LLM | 將 LLM 與 RAG 搭配使用 |
|---|---|
| 沒有專屬知識:LLM 通常使用公開可用的資料進行訓練,因此它們無法準確回答有關公司內部或專屬資料的問題。 | RAG 應用程式可以納入專屬資料:RAG 應用程式可以將專屬文件 (如備忘、電子郵件和設計文件) 提供給 LLM,使其能夠回答有關這些文件的問題。 |
| 知識不會即時更新:LLM 無法存取有關訓練後所發生事件的資訊。 例如,獨立 LLM 無法告訴您有關今天股票走勢的任何資訊。 | RAG 應用程式可以存取即時資料:RAG 應用程式可以從更新的資料來源為 LLM 提供即時資訊,讓其對超過訓練截止日期的事件提供有用的答案。 |
| 缺乏引文:LLM 在回應時無法引用特定資訊來源,讓使用者無法驗證回應是實際正確還是幻覺。 | RAG 可以引用來源:用作 RAG 應用程式的一部分時,可以要求 LLM 引用來源。 |
| 缺乏資料存取控制 (ACL):僅 LLM 無法根據特定的使用者權限可靠地為不同使用者提供不同的答案。 | RAG 允許資料安全性/ACL: 擷取步驟的設計目的是只尋找使用者具有存取認證的資訊,讓RAG應用程式選擇性地擷取個人或專屬資訊。 |
RAG 類型
RAG 架構可以使用兩種類型的支援資料:
| 結構化資料 | 非結構化資料 | |
|---|---|---|
| 定義 | 表格式數據會以具有特定架構的數據列和數據行排列,例如資料庫中的數據表。 | 沒有特定結構或組織的資料,例如包含文字和影像的文件,或者音訊或視訊等多媒體內容。 |
| 範例資料來源 | - BI 或資料倉儲系統中的客戶記錄 - 來自 SQL 資料庫的交易資料 - 來自應用程式 API 的資料 (例如 SAP、Salesforce 等) |
- BI 或資料倉儲系統中的客戶記錄 - 來自 SQL 資料庫的交易資料 - 來自應用程式 API 的資料 (例如 SAP、Salesforce 等) - Google 或 Microsoft Office 文件 - Wiki - 影像 - 視訊 |
RAG 的資料選擇取決於您的使用案例。 本教學課程的其餘部分著重於非結構化數據的RAG。