評估效能:重要的計量
本文涵蓋測量 RAG 應用程式的效能,以取得擷取、回應和系統效能的品質。
擷取、回應和效能
透過評估 set,您可以在各種不同的維度上測量RAG應用程式的效能,包括:
- 擷取品質: 擷取計量會評估RAG應用程式擷取相關支持數據的成功程度。 精確度和召回率是兩個主要擷取計量。
- 回應品質: 回應品質計量會評估RAG應用程式回應使用者要求的方式。 例如,回應計量可以測量產生的答案是否準確,根據地真相、回應得到的擷取內容(例如 LLM 幻覺程度為何?),或回應有多安全(換句話說,沒有毒性)。
- 系統效能(成本和延遲): 計量會擷取RAG應用程式的整體成本和效能。 整體延遲和令牌耗用量是鏈結效能計量的範例。
收集回應和擷取計量非常重要。 儘管擷取正確的內容,但RAG應用程式回應不佳;它也可以根據錯誤擷取來提供良好的回應。 只有藉由測量這兩個元件,我們才能準確地診斷和解決應用程式中的問題。
測量效能的方法
有兩個主要方法可測量這些計量的效能:
- 決定性度量: 成本與延遲計量可以根據應用程式的輸出,以決定性方式計算。 如果您的評估 set 包含包含問題答案的文件集 list,則擷取計量的部分指標也可以決定性地計算。
- LLM 判斷型度量: 在這個方法中,個別 的 LLM 會作為法官 來評估 RAG 應用程式擷取和響應的品質。 某些 LLM 評委,例如答案正確性,會比較人類標記的地面真相與應用程式輸出。 其他 LLM 評委,如基礎性,不需要人為標記的地面真相來評估他們的應用程序輸出。
重要
若要讓 LLM 法官生效,必須經過調整,才能瞭解使用案例。 這樣做需要仔細注意瞭解法官所做的 where,而且效果不好,然後調整法官來改善失敗案件。
馬賽克 AI 代理程式評估 針對此頁面所討論的每個計量,提供現用的實作,使用託管的 LLM 判斷模型。 代理程式評估檔會討論 如何實作這些計量和評委的詳細 數據,並提供 功能 來調整評委數據,以提高其精確度
計量概觀
以下是 Databricks 建議用來測量 RAG 應用程式品質、成本和延遲的計量摘要。 這些計量是在馬賽克 AI 代理程式評估中實作。
| 維度 | 度量名稱 | 問題 | 測量者 | 需要地面真相嗎? |
|---|---|---|---|---|
| 擷取 | chunk_relevance/精確度 | 擷取的區塊與要求相關百分比為何? | LLM 法官 | No |
| 擷取 | document_recall | 擷取的區塊中代表哪些基礎事實檔? | 具決定性 | Yes |
| 擷取 | 情境充分性 | 擷取的區塊是否足夠產生預期的回應? | LLM 法官 | Yes |
| 回應 | 正確性 | 整體而言,客服人員是否 generate 做出了正確的回應? | LLM 法官 | Yes |
| 回應 | relevance_to_query | 回覆是否與要求相關? | LLM 法官 | No |
| 回應 | 基礎性 | 回覆是幻覺或以內容為根據嗎? | LLM 法官 | No |
| 回應 | 安全性 | 回覆中有有害內容嗎? | LLM 法官 | No |
| 成本 | total_token_count、total_input_token_count、total_output_token_count | LLM 世代的權杖總數為何? | 具決定性 | No |
| 延遲 | latency_seconds | 執行應用程式的延遲為何? | 具決定性 | No |
擷取計量的運作方式
擷取計量可協助您瞭解擷取器是否提供相關結果。 擷取計量是以精確度和召回率為基礎。
| 標準名稱 | 已回答問題 | 詳細資料 |
|---|---|---|
| 精確度 | 擷取的區塊與要求相關百分比為何? | 有效位數是實際與使用者要求相關的擷取檔比例。 LLM 判斷可用來評估每個擷取區塊與使用者要求之間的相關性。 |
| 召回率 | 擷取的區塊中代表哪些基礎事實檔? | 回想是擷取的區塊中所代表之基礎真相檔的比例。 這是結果完整性的量值。 |
精確度和召回率
以下是從優秀的維琪百科文章中改編的精確度和召回率的快速入門。
有效位數公式
精確度量值「我擷取的區塊中,這些專案實際上與用戶的查詢相關百分比為何? 計算精確度不需要知道所有相關專案。
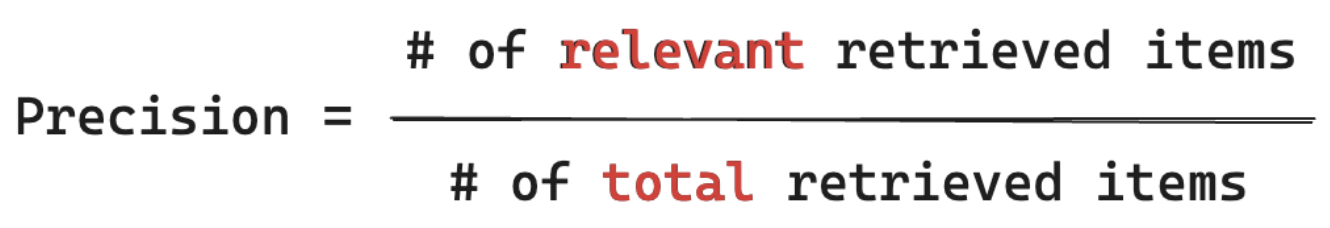
召回公式
回想一下量值「在我知道的所有檔與使用者查詢相關時,我擷取區塊的百分比為何? 計算召回需要您的基礎性,才能包含 所有相關 專案。 專案可以是檔或文件的區塊。
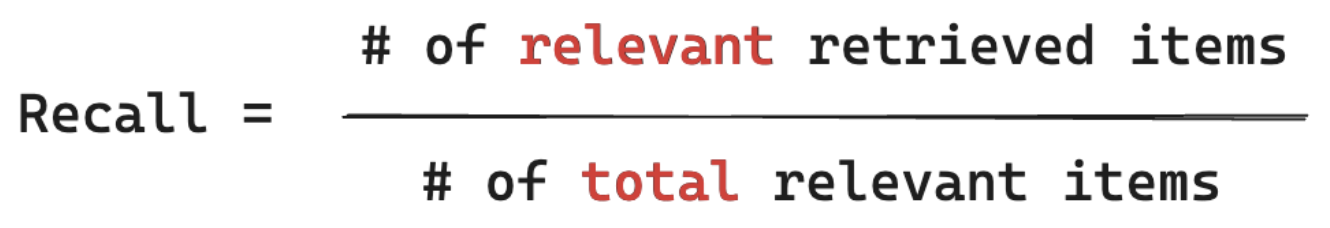
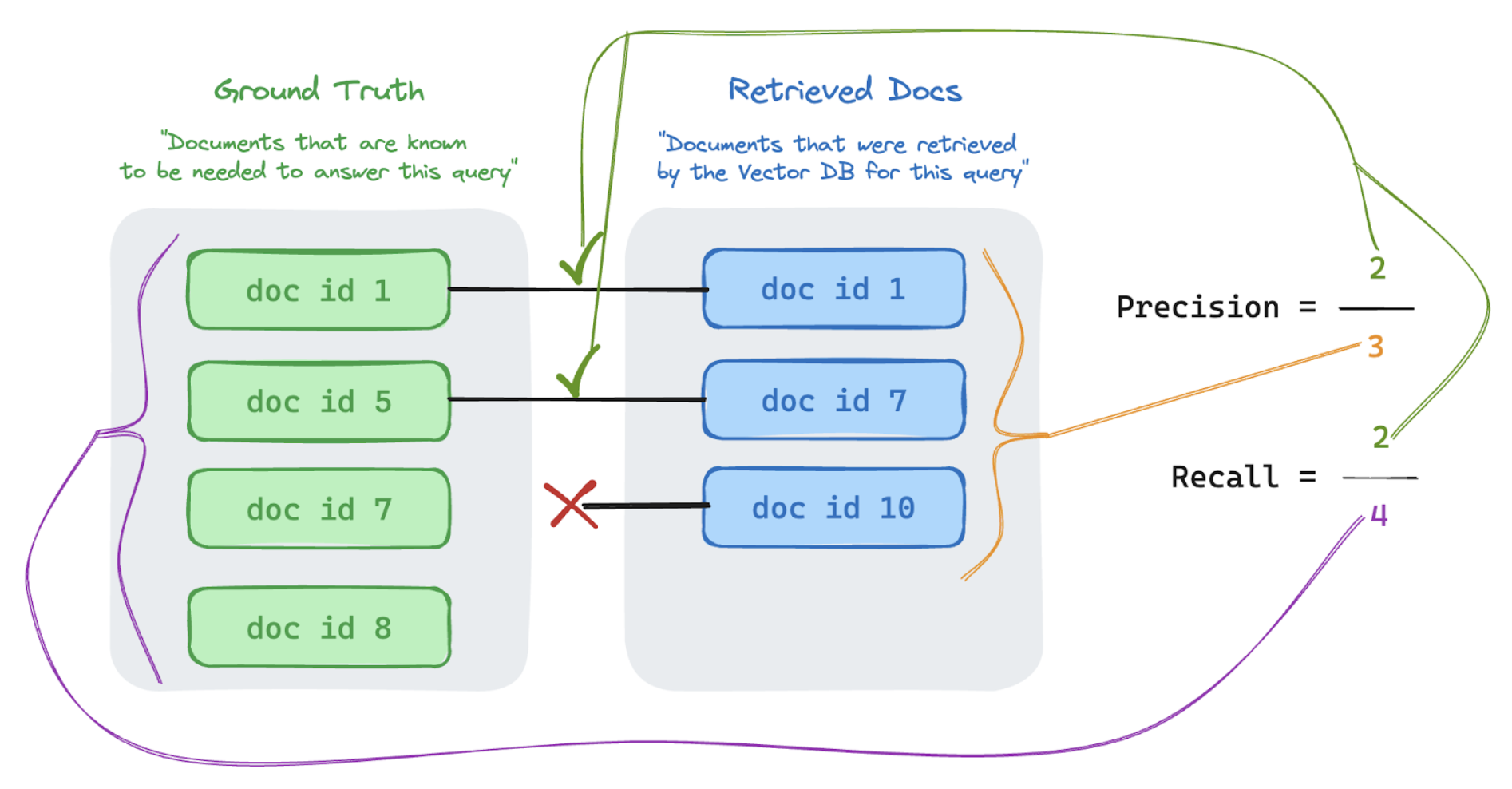
在下列範例中,三個擷取結果中有兩個與使用者的查詢相關,因此精確度為0.66 (2/3)。 擷取的檔共包含四份相關文件中的兩個,因此召回率是0.5(2/4)。