使用 Unity 目錄擷取和檢視數據譜系
本文說明如何使用目錄總管、數據譜系系統數據表和 REST API 來擷取和可視化數據譜系。
您可以使用 Unity 目錄,在 Azure Databricks 上執行的查詢之間擷取運行時間數據譜系。 所有語言都支援數據譜系,並紀錄到欄位層級。 譜系資料包含與查詢相關的筆記本、工作和儀表板。 譜系可以在目錄總管中以近乎即時的方式可視化,並使用譜系系統數據表和 Databricks REST API 以程式設計方式擷取。
譜系會匯總至連結到 Unity Catalog 中繼資料庫的所有工作區。 這表示在一個工作區中擷取的譜系會顯示在共用該中繼存放區的任何其他工作區中。 具體而言,註冊在中繼存放區中的資料表和其他資料物件,在附加到中繼存放區的所有工作區中,對於擁有至少 BROWSE 許可權的使用者來說是可見的。 不過,來自其他工作區的筆記本和儀錶板等工作區層級對象的詳細資訊已被隱藏(請參閱 限制 和 譜系許可權)。
歷程數據會保留一年。
下圖是範例譜系圖。 本文稍後會說明特定的資料譜系功能和範例。
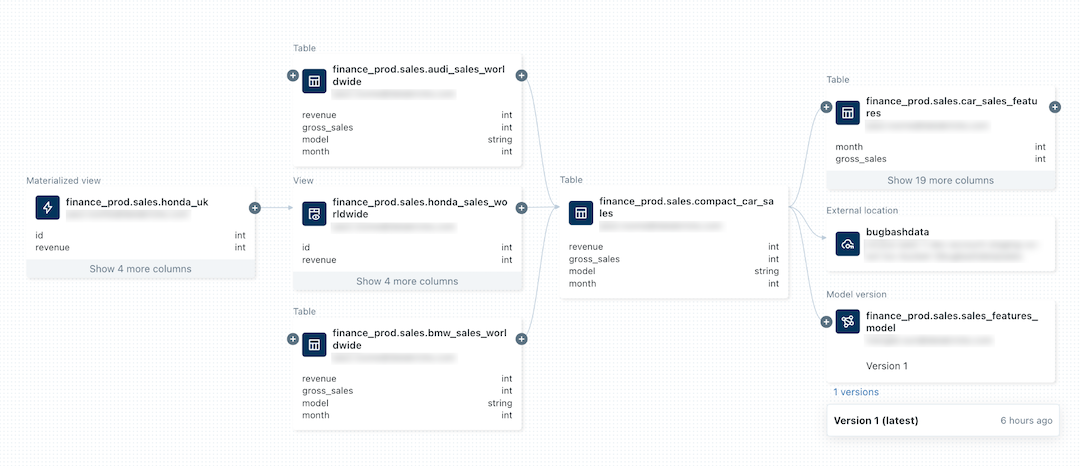
如需追蹤機器學習模型譜系的相關信息,請參閱 在 Unity 類別目錄中追蹤模型的數據譜系。
需求
使用 Unity Catalog 擷取資料溯源需要下列項目:
- 工作區必須啟用 Unity 目錄。
- 數據表必須在 Unity 目錄中繼存放區中註冊。
- 查詢必須使用 Spark DataFrame (例如會傳回 DataFrame 的 Spark SQL 函式) 或 Databricks SQL 介面。 如需 Databricks SQL 和 PySpark 查詢的範例,請參閱範例。
- 若要檢視數據表或視圖的譜系,使用者至少需要具有數據表或視圖父目錄的
BROWSE許可權。 父目錄也必須可從工作區存取。 請參閱 限制特定工作區的目錄存取。 - 若要檢視筆記本、工作或儀表板的譜系資訊,使用者必須擁有這些物件的權限,如工作區中的存取控制設定所定義。 請參閱譜系權限。
- 若要查看已啟用 Unity Catalog 管線的血統,您必須具有該管線的
CAN_VIEW權限。 - Delta 表之間的串流系譜追蹤需要 Databricks Runtime 11.3 LTS 或更新版本。
- DLT 工作負載的數據行歷程追蹤需要 Databricks Runtime 13.3 LTS 或更新版本。
- 您可能需要更新輸出防火牆規則,以允許連線到 Azure Databricks 控制平面中的事件中樞端點。 通常,如果您的 Azure Databricks 工作區部署在您自己的 VNet (也稱為 VNet 插入) 中,則適用此規則。 若要取得工作區區域的事件中樞端點,請參閱 Metastore、工件 Blob 儲存體、系統資料表儲存體、日誌 Blob 儲存體和事件中樞端點 IP 位址。 如需為 Azure Databricks 設定使用者定義路由 (UDR) 的相關資訊,請參閱 Azure Databricks 的使用者定義路由設定。
範例
注意
下列範例使用目錄名稱
lineage_data和架構名稱lineagedemo。 若要使用不同的目錄和架構,請變更範例中使用的名稱。若要完成此範例,您必須擁有架構的
CREATE和USE SCHEMA許可權。 具有架構上MANAGE許可權的中繼存放區管理員、目錄擁有者、架構擁有者或使用者可以授與這些許可權。 例如,若要為群組 『data_engineers』 中的所有使用者提供在lineagedemo目錄中lineage_data架構中建立數據表的許可權,具有上述其中一個許可權或角色的使用者可以執行下列查詢:CREATE SCHEMA lineage_data.lineagedemo; GRANT USE SCHEMA, CREATE on SCHEMA lineage_data.lineagedemo to `data_engineers`;
擷取和探索譜系
若要擷取譜系資料:
移至您的 Azure Databricks 起始頁面,點擊側邊欄中的
 新增,然後從功能表中選取 Notebook。
新增,然後從功能表中選取 Notebook。輸入筆記本的名稱,然後在預設語言中選擇 SQL。
在 [叢集]中,選取具有 Unity 目錄存取權的叢集。
點選 [建立]。
在第一個筆記本儲存格中,輸入下列查詢:
CREATE TABLE IF NOT EXISTS lineage_data.lineagedemo.menu ( recipe_id INT, app string, main string, dessert string ); INSERT INTO lineage_data.lineagedemo.menu (recipe_id, app, main, dessert) VALUES (1,"Ceviche", "Tacos", "Flan"), (2,"Tomato Soup", "Souffle", "Creme Brulee"), (3,"Chips","Grilled Cheese","Cheesecake"); CREATE TABLE lineage_data.lineagedemo.dinner AS SELECT recipe_id, concat(app," + ", main," + ",dessert) AS full_menu FROM lineage_data.lineagedemo.menu若要執行查詢,請按一下儲存格,然後按shift+enter,或者點擊
 並選擇執行儲存格。
並選擇執行儲存格。
若要使用目錄總管來檢視這些查詢所產生的譜系:
在 Azure Databricks 工作區頂端列的 [搜尋] 方塊中,搜尋
lineage_data.lineagedemo.dinner數據表並加以選取。選取 [歷程] 索引標籤。譜系面板隨即出現,並顯示相關的數據表(在此範例中為
menu數據表)。若要檢視資料譜系的互動式圖表,請按下 [查看譜系圖]。 依預設,圖表中會顯示一個層級。 點擊節點上的
 圖示,以揭示更多可用的連線。
圖示,以揭示更多可用的連線。按下連接譜系圖中節點的箭號,以開啟 [譜系連線] 面板。 歷程連線 面板會顯示連線的詳細數據,包括來源和目標數據表、筆記本和作業。
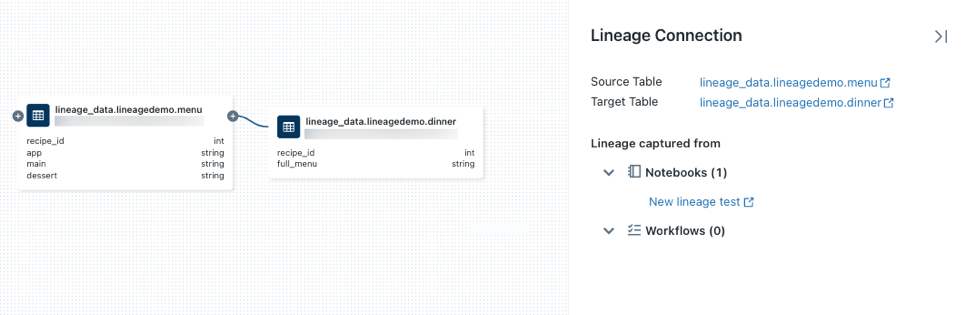
若要顯示與
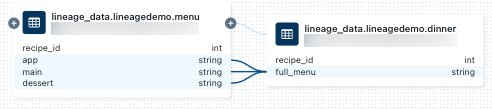
dinner數據表相關聯的筆記本,請在 [譜系連線] 面板中選取該筆記本,或關閉譜系圖形後點擊 [Notebooks]。 若要在新索引標籤中開啟筆記本,請按下筆記本名稱。若要檢視數據行層級譜系,請按兩下圖表中的數據行以顯示相關數據行的連結。 例如,點擊 [full_menu] 欄會顯示此欄衍生自的上游欄:
若要使用不同的語言來檢視譜系,例如 Python:
開啟您先前建立的筆記本、建立新的儲存格,然後輸入下列 Python 程式碼:
%python from pyspark.sql.functions import rand, round df = spark.range(3).withColumn("price", round(10*rand(seed=42),2)).withColumnRenamed("id","recipe_id") df.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.price") dinner = spark.read.table("lineage_data.lineagedemo.dinner") price = spark.read.table("lineage_data.lineagedemo.price") dinner_price = dinner.join(price, on="recipe_id") dinner_price.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.dinner_price")透過以下方式執行儲存格:按下儲存格,然後按 "shift+enter",或按下
,並選取 [執行儲存格]。在 Azure Databricks 工作區頂端列的 [搜尋] 方塊中,搜尋
lineage_data.lineagedemo.price數據表並加以選取。移至 [譜系] 索引標籤,然後按下 [查看譜系圖]。 按下
圖示,以探索查詢產生的資料譜系。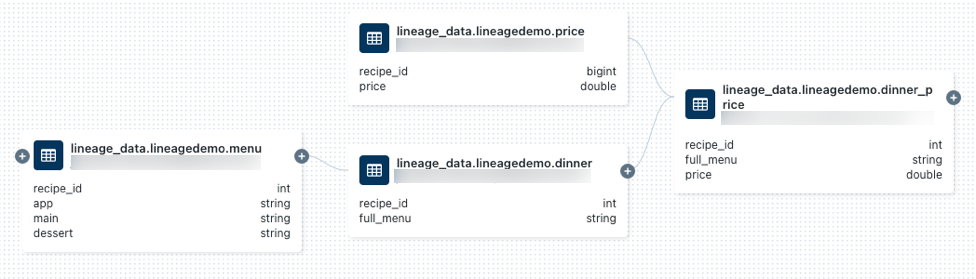
按下連接譜系圖中節點的箭號,以開啟 [譜系連線] 面板。 歷程連線 面板會顯示連線的詳細數據,包括來源和目標數據表、筆記本和作業。
擷取並檢視工作流程譜系
讀取或寫入 Unity Catalog 的任何工作流程都會記錄其譜系。 若要檢視 Azure Databricks 工作流程的譜系:
在側邊欄中單擊
新增,然後從功能表中選取 Notebook。輸入筆記本的名稱,然後在 [預設語言] 中選取 [SQL]。
按一下 [建立]。
在第一個筆記本儲存格中,輸入下列查詢:
SELECT * FROM lineage_data.lineagedemo.menu按一下頂端列中的 [排程]。 在排程對話框中,選取 [手動],選取具有 Unity Catalog 存取權的叢集,然後按一下 [建立]。
按下 [立即執行]。
在 Azure Databricks 工作區頂端列的 [搜尋] 方塊中,搜尋
lineage_data.lineagedemo.menu數據表並加以選取。在 [歷程] 索引標籤上,按一下 [工作流程],然後選取 [下游] 索引標籤。作業名稱將顯示在 [作業名稱] 底下,作為 [
menu] 表的取用者。
擷取並檢視儀表板譜系
若要建立儀表板並檢視其資料譜系:
移至您的 Azure Databricks 首頁,然後按一下側邊欄中的 目錄,以開啟目錄總管。
按一下目錄名稱,按一下 lineagedemo,然後選取
menu資料表。 您也可以使用頂端列中的 [搜尋] 方塊來搜尋menu數據表。點擊 在儀表板中開啟。
選擇您要新增至儀表板的資料行,然後按下 建立。
發佈儀表板。
在資料沿革中僅追蹤已發佈的儀表板。
在頂端列的 [搜尋] 方塊中,搜尋
lineage_data.lineagedemo.menu表格並選取它。在 [譜系] 索引標籤上,按下 [儀表板]。 儀錶板會出現在 儀錶板名稱 下,作為選單表格的使用者。
譜系權限
譜系圖與 Unity Catalog 使用相同的 權限模型。 在 Unity 目錄中繼存放區中註冊的數據表和其他數據物件,只有至少具有這些物件 BROWSE 許可權的使用者才能看見。 如果使用者在數據表上沒有 BROWSE 或 SELECT 許可權,他們就無法探索其譜系。 在所有連結至中繼存放庫的工作區中,只要使用者擁有足夠的物件許可權,譜系圖會顯示 Unity Catalog 物件。
例如,針對 userA執行下列命令:
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
當 userA 檢視 lineage_data.lineagedemo.menu 數據表的譜系圖形時,他們會看到 menu 數據表。 它們將無法查看相關聯數據表的相關信息,例如下游 lineage_data.lineagedemo.dinner 數據表。
dinner 數據表會顯示為 masked界面中的 userA 節點,而且 userA 無法從他們沒有許可權存取的數據表展開視覺圖表,來顯示下游數據表。
如果您執行下列命令,將 BROWSE 許可權授與 userB,該使用者可以檢視 lineage_data 架構中任何數據表的譜系圖形。
GRANT BROWSE on lineage_data to `userB@company.com`;
同樣地,譜系用戶必須具有特定許可權,才能檢視筆記本、作業和儀錶板等工作區物件。 此外,他們只能在登入建立這些物件的工作區時,查看工作區對象的詳細資訊。 其他工作區中工作區層級的物件詳細資訊會在譜系圖形中隱藏。
如需有關管理 Unity Catalog 中可安全存取物件的詳細資訊,請參閱 在 Unity Catalog 中管理許可權。 如需有關管理工作區物件 (例如筆記本、工作和儀表板) 存取權的詳細資訊,請參閱存取控制清單。
刪除譜系資料
警告
下列指示會刪除儲存在 Unity 目錄中的所有物件。 請僅在必要時使用這些指令。 例如,若要符合合規性需求。
若要刪除歷程數據,您必須刪除管理 Unity Catalog 物件的中繼存放區。 如需有關刪除中繼存放區的詳細資訊,請參閱刪除中繼存放區。 資料將在 90 天內刪除。
使用 Databricks Assistant 取得數據表譜系
Databricks Assistant 提供有關數據表譜系和深入解析的詳細資訊。
若要使用小幫手取得譜系資訊:
- 移至您的 Azure Databricks 登陸頁面,然後按一下側邊欄中的
 目錄,以開啟 [目錄總管]。
目錄,以開啟 [目錄總管]。 - 按兩下類別目錄名稱,然後按兩下
 小幫手圖示。
小幫手圖示。 - 在助理提示字元中,輸入:
- /getTableLineages,以檢視上游和下游相依性。
- /getTableInsights 來存取依據元數據所提供的見解,例如使用者活動和查詢模式。
這些查詢可讓小幫手回答「顯示下游譜系」或「最常查詢此數據表的人員」等問題。

使用系統數據表查詢血統數據
您可以使用譜系系統數據表,以程式設計方式查詢譜系數據。 如需詳細指示,請參閱 使用系統資料表監視帳戶活動 和 歷程系統資料表參考。
如果您的工作區位於不支援譜系系統數據表的區域,您也可以使用數據歷程 REST API,以程式設計方式擷取譜系數據。
使用資料譜系 REST API 擷取譜系
數據歷程 API 可讓您擷取數據表和數據行譜系。 不過,如果您的工作區位於支援譜系系統數據表的區域,您應該使用系統數據表查詢,而不是 REST API。 系統數據表是程式設計擷取譜系數據更好的選項。 大部分區域都支援譜系系統數據表。
重要
若要存取 Databricks REST API,您必須驗證。
擷取數據表譜系
此範例會擷取 dinner 數據表的歷程數據。
請求
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/table-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "include_entity_lineage": true}'
取代 <workspace-instance>。
此範例會使用 .netrc 檔案。
回應
{
"upstreams": [
{
"tableInfo": {
"name": "menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
],
"downstreams": [
{
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
},
{
"tableInfo": {
"name": "dinner_price",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
]
}
擷取欄位譜系
此範例會擷取 dinner 資料表的欄位資料。
請求
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/column-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "column_name": "dessert"}'
取代 <workspace-instance>。
此範例會使用 .netrc 檔案。
回應
{
"upstream_cols": [
{
"name": "dessert",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "main",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "app",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
}
],
"downstream_cols": [
{
"name": "full_menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "dinner_price",
"table_type": "TABLE"
}
]
}
限制
雖然所有連結到相同 Unity Catalog 中繼存放區的工作區的資料譜系已匯總,但像筆記本和儀錶板這類工作區對象的詳細資訊僅在其創建所在的工作區中可見。
由於譜系是在一年滾動視窗中計算,因此不會顯示一年多前收集的譜系。 例如,如果作業或查詢從數據表 A 讀取數據並寫入至數據表 B,則數據表 A 與數據表 B 之間的連結只會顯示一年。 您可以在一年時間範圍內依時間範圍篩選譜系數據。
檢視譜系時,使用工作 API
runs submit要求的工作不可用。 使用runs submit要求時,仍會擷取表格和欄位層級的譜系,但不會擷取與執行的連結。Unity 目錄會盡可能擷取譜系至欄位層級。 不過,在某些情況下,無法擷取欄位層級譜系。
只有當來源和目標都以數據表名稱來參考時,才支援欄位譜系(範例:
select * from <catalog>.<schema>.<table>)。 如果來源或目標是以路徑尋址,則無法擷取數據行譜系 (範例:select * from delta."s3://<bucket>/<path>")。如果重新命名數據表或檢視表,則不會擷取已重新命名數據表或檢視表的譜系。
如果重新命名架構或目錄,則不會擷取重新命名目錄或架構下數據表和檢視的歷程記錄。
如果您使用 Spark SQL 資料集檢查點,則不會擷取譜系。
在大部分情況下,Unity 目錄會從 DLT 管線擷取譜系。 不過,在某些情況下,無法保證完整的歷程涵蓋範圍,例如當管線使用 APPLY CHANGES API 或 TEMPORARY 資料表時。
譜系不會擷取堆疊函式。
全域暫存檢視不會被記錄在譜系中。
system.information_schema下的數據表不會在譜系中記錄。預設情況下,不會針對
MERGE作業擷取完整的欄位級別的系譜。您可以透過將 Spark 屬性
spark.databricks.dataLineage.mergeIntoV2Enabled設定為true來開啟MERGE操作的歷程擷取。 啟用此旗標可能會降低查詢效能的速度,特別是在涉及非常寬數據表的工作負載中。