使用 Apache Kafka 和 Azure Databricks 進行串流處理
本文說明如何在 Azure Databricks 上執行結構化串流工作負載時,使用 Apache Kafka 作為來源或接收器。
如需更多 Kafka,請參閱 Kafka 文件。
從 Kafka 讀取資料
以下是從 Kafka 串流讀取的範例:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "latest")
.load()
)
Azure Databricks 也支援 Kafka 資料來源的批次讀取語意,如下列範例所示:
df = (spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
)
對於累加式批次載入,Databricks 建議將 Kafka 與 Trigger.AvailableNow 搭配使用。 請參閱設定累加批次處理。
在 Databricks Runtime 13.3 LTS 和更新版本中,Azure Databricks 提供 SQL 函式來讀取 Kafka 資料。 只有 DLT 或 Databricks SQL 中的串流數據表才支援使用 SQL 進行串流處理。 請參閱 read_kafka 資料表值函式。
設定 Kafka 結構化串流讀取器
Azure Databricks 提供 kafka 關鍵詞作為數據格式,以設定 Kafka 0.10+ 的連線。
以下是 Kafka 的最常見組態:
有多種方式指定要訂閱的主題。 您應該只提供下列其中一個參數:
| 選項 | 值 | 描述 |
|---|---|---|
| 訂閱 | 以逗號分隔的主題清單。 | 要訂閱的主題清單。 |
| 訂閱模式 | Java regex 字串。 | 用於訂閱主題的範式。 |
| 分配 | JSON 字串 {"topicA":[0,1],"topic":[2,4]}。 |
要使用的特定主題分區。 |
其他值得注意的組態:
| 選項 | 價值 | 預設值 | 描述 |
|---|---|---|---|
| kafka.bootstrap.servers | host:port 的逗號分隔清單。 | empty | [必要] Kafka bootstrap.servers 組態。 如果您發現 Kafka 中沒有任何資料,請先檢查訊息代理程式地址清單。 如果訊息代理程式位址清單不正確,可能沒有任何錯誤。 這是因為 Kafka 客戶端假設代理程式最終會變得可用,而且在發生網路錯誤時會無限次嘗試重連。 |
| failOnDataLoss(數據丟失時失敗) |
true 或 false。 |
true |
[選用] 在資料可能遺失的情況下是否讓查詢失敗。 在許多情況下 (例如主題已刪除、主題在處理前已截斷等等),查詢可能永遠也無法從 Kafka 讀取資料。 我們會嘗試保守地估計資料是否可能遺失。 有時這可能會導致誤報。 如果此選項無法如預期般運作,或您希望查詢在資料遺失時繼續處理,請將此選項設定為 false。 |
| minPartitions | 整數 >= 0,0 = 停用。 | 0 (已停用) | [選用] 從 Kafka 讀取的分區數目下限。 您可以使用 minPartitions 選項將 Spark 設定為使用任意個最少分區從 Kafka 讀取。 通常,Spark 在 Kafka 主題分割區與從 Kafka 取用的 Spark 分區之間存在 1對1 對應。 如果您將 [minPartitions] 選項設定為大於 Kafka topicPartitions 的值,Spark 會將大型 Kafka 分割區分割除成較小的片段。 在尖峰負載、數據偏斜以及您的數據流處於落後狀況時,您可以設定這個選項來提高處理速率。 這需要在每次觸發時初始化 Kafka 使用者。如果您在連線至 Kafka 時使用 SSL,這可能會影響效能。 |
| kafka.group.id | Kafka 取用者群組識別碼。 | 未設定 | [選用] 從 Kafka 讀取時要使用的群組識別碼。 請謹慎使用此選項。 根據預設,每個查詢都會產生用於讀取資料的唯一群組識別碼。 這可確保每個查詢程序都有自己獨立的消費者群組,不會受到其他消費者的干擾,從而能夠讀取其訂閱主題的所有分割區。 在某些情況下 (例如,Kafka 群組型授權),您可能希望使用特定的授權群組識別碼來讀取資料。 您可以選擇性地設定群組識別碼。 但是,執行此作業時要特別謹慎,因為它可能會導致非預期行為。
|
| 起始偏移量 | 最早、最新 | 最新 | [選擇性] 查詢啟動時的起始點,可以是「最早」,即從最早的位移開始,或是以 json 字串指定每個 TopicPartition 的起始位移。 在 JSON 中,-2 可以作為偏移來指代最早的位置,而 -1 則表示最新的位置。 注意:對於批次查詢,不允許使用最新版本(無論是以隱式方式還是通過在 JSON 中使用 -1)。 對於串流查詢,只有在啟動新的查詢時,才會適用這項操作,且恢復執行時一律會從查詢中斷的地方繼續。 查詢期間新探索的分區將從最早位置開始。 |
如需其他選用組態,請參閱結構化串流 Kafka 整合指南。
Kafka 記錄的架構
Kafka 記錄的架構為:
| 列 | 類型 |
|---|---|
| 關鍵 | 二進制 |
| 價值 | binary |
| 主題 | 字串 |
| 分區 | 整數 (int) |
| 抵消 | 長 |
| 時間戳記 | 長 |
| 時間戳類型 | 整數 (int) |
key和value 一律以ByteArrayDeserializer 還原序列化為位元組陣列。 使用 DataFrame 作業(例如 cast("string")),明確地進行鍵和值的反序列化。
將資料寫入 Kafka
以下是串流寫入 Kafka 的範例:
(df
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.start()
)
Azure Databricks 也支援 Kafka 資料接收器的批次寫入語意,如下列範例所示:
(df
.write
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.save()
)
設定 Kafka 結構化串流寫入器
重要
Databricks Runtime 13.3 LTS 和更新版本包含了一個更新的 kafka-clients 程式庫,該程式庫預設啟用等冪寫入功能。 如果 Kafka 接收器使用 2.8.0 或更低版本,並且已設定 ACL 但未啟用 IDEMPOTENT_WRITE,則寫入將會失敗並出現錯誤訊息 org.apache.kafka.common.KafkaException:Cannot execute transactional method because we are in an error state。
透過升級至 Kafka 2.8.0 或更新版本或者在設定結構化串流寫入器時設定 .option(“kafka.enable.idempotence”, “false”),來解決此錯誤。
提供給 DataStreamWriter 的架構會與 Kafka 匯集互動。 您可以使用下列欄位:
| 欄名稱 | 必要或選用 | 類型 |
|---|---|---|
key |
選用 |
STRING 或 BINARY |
value |
必須的 |
STRING 或 BINARY |
headers |
選用 | ARRAY |
topic |
選擇性(如果 topic 設為 writer 選項,則會忽略) |
STRING |
partition |
選用 | INT |
以下是寫入 Kafka 時所設定的常見選項:
| 選項 | 值 | 預設值 | 描述 |
|---|---|---|---|
kafka.boostrap.servers |
以逗號分隔的 <host:port> 清單 |
None | [必要] Kafka bootstrap.servers 組態。 |
topic |
STRING |
未設定 | [選用] 設定要寫入的所有資料列的主題。 此選項會覆寫資料中已存在的任何主題欄位。 |
includeHeaders |
BOOLEAN |
false |
[選用] 是否要在資料列中包含 Kafka 標頭。 |
如需其他選用組態,請參閱結構化串流 Kafka 整合指南。
擷取 Kafka 指標
您可以使用 avgOffsetsBehindLatest、maxOffsetsBehindLatest 和 minOffsetsBehindLatest 指標,獲取串流查詢在所有已訂閱主題中相較於最新可用偏移量落後的偏移數的平均、最小和最大值。 請參閱以互動方式讀取計量。
注意
在 Databricks Runtime 9.1 和更新版本中可用。
藉由檢查 estimatedTotalBytesBehindLatest的值,取得查詢進程未從訂閱的主題取用的估計位元組總數。 此估計值基於在過去 300 秒內處理的批次。 您可以透過將選項 bytesEstimateWindowLength 設定為其他值,來變更估計值所基於的時間範圍。 例如,若要將它設定為10分鐘:
df = (spark.readStream
.format("kafka")
.option("bytesEstimateWindowLength", "10m") # m for minutes, you can also use "600s" for 600 seconds
)
如果在筆記本中執行串流,您可以在串流查詢進度儀表板中的 [原始資料] 索引標籤下查看這些計量:
{
"sources": [
{
"description": "KafkaV2[Subscribe[topic]]",
"metrics": {
"avgOffsetsBehindLatest": "4.0",
"maxOffsetsBehindLatest": "4",
"minOffsetsBehindLatest": "4",
"estimatedTotalBytesBehindLatest": "80.0"
}
}
]
}
使用 SSL 將 Azure Databricks 連線至 Kafka
若要啟用 Kafka 的 SSL 連線,請遵循 Confluent 文件中的指示,參見 SSL 加密和驗證章節。 您可以提供此處所述的組態 (以 kafka. 為首碼) 作為選項。 例如,您可以在屬性 kafka.ssl.truststore.location 中指定信任存放區位置。
Databricks 建議您:
- 將您的憑證儲存在雲端物件儲存體中。 您可以將對憑證的存取權限制為僅可以存取 Kafka 的叢集。 請參閱 使用 Unity Catalog 資料控管。
- 將憑證密碼儲存為祕密範圍中的祕密。
下列範例使用物件儲存位置和 Databricks 祕密來啟用 SSL 連線:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", ...)
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.ssl.truststore.location", <truststore-location>)
.option("kafka.ssl.keystore.location", <keystore-location>)
.option("kafka.ssl.keystore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<keystore-password-key-name>))
.option("kafka.ssl.truststore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<truststore-password-key-name>))
)
將 HDInsight 上的 Kafka 連線至 Azure Databricks
建立 HDInsight Kafka 叢集。
如需相關指示,請參閱透過 Azure 虛擬網路連線至 HDInsight 上的 Kafka。
設定 Kafka 訊息代理程式來公告正確的位址。
請遵循設定 Kafka 進行 IP 公告中的指示。 如果您在 Azure 虛擬機上自行管理 Kafka,請確定代理程式
advertised.listeners設定設為主機的內部 IP。建立 Azure Databricks 叢集。
將 Kafka 叢集連接到 Azure Databricks 叢集。
請遵循對等互連虛擬網路中的指示。
使用 Microsoft Entra ID 和 Azure 事件中樞進行服務主體驗證
Azure Databricks 支援使用事件中樞服務對 Spark 作業進行驗證。 此驗證是透過具有 Microsoft Entra ID 的 OAuth 來完成。
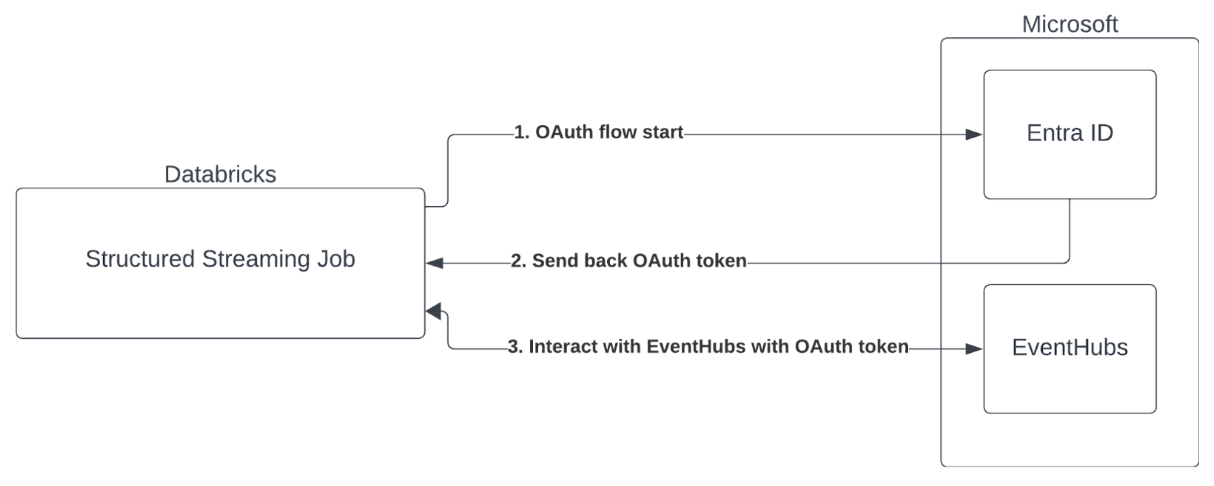
Azure Databricks 支援在下列計算環境中使用用戶端識別碼和祕密進行 Microsoft Entra ID 驗證:
- Databricks Runtime 12.2 LTS 和更高版本適用於設置為專用訪問模式的計算資源(以前稱為單用戶訪問模式)。
- Databricks Runtime 14.3 LTS 和之後的版本在配置為標準存取模式(以前稱為共用存取模式)的計算資源上。
- 未使用 Unity Catalog 設定的 DLT 管線。
Azure Databricks 不支援在任何計算環境或使用 Unity Catalog 設定的 DLT 管線中,透過憑證進行 Microsoft Entra ID 驗證。
此驗證不適用於使用標準存取模式的計算資源或在 Unity Catalog DLT 上執行。
設定結構化串流 Kafka 連接器
若要使用 Microsoft Entra ID 執行驗證,您需要下列值:
租戶識別碼。 您可以在 [Microsoft Entra ID] 服務索引標籤中找到此項。
clientID (也稱為應用程式識別碼)。
用戶端密碼。 在您具有此密碼後,應將其作為祕密新增至 Databricks 工作區。 若要新增此祕密,請參閱祕密管理。
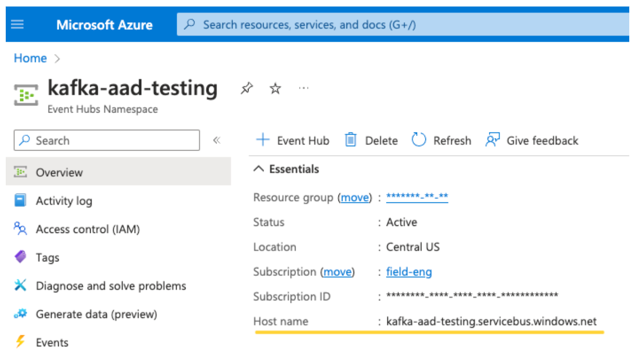
EventHubs 的主題。 您可以在特定 事件中樞命名空間 頁面的 [實體] 區段底下,找到 [事件中樞] 區段的主題清單。 若要處理多個主題,您可以在 Event Hubs 層級設定 IAM 角色。
EventHubs 伺服器。 您可以在特定 [事件中樞命名空間] 的概觀頁面上找到此項:
此外,若要使用 Entra ID,我們需要告知 Kafka 使用 OAuth SASL 機制 (SASL 是一般通訊協定,而 OAuth 是 SASL「機制」的一種類型):
-
kafka.security.protocol應為SASL_SSL -
kafka.sasl.mechanism應為OAUTHBEARER -
kafka.sasl.login.callback.handler.class應是 Java 類別的完整名稱,其值為kafkashaded,用於我們修改後的 Kafka 類別的登錄回撥處理程序。 如需確切的類別,請參閱下列範例。
範例
接下來,讓我們看看執行中的範例:
Python
# This is the only section you need to modify for auth purposes!
# ------------------------------
tenant_id = "..."
client_id = "..."
client_secret = dbutils.secrets.get("your-scope", "your-secret-name")
event_hubs_server = "..."
event_hubs_topic = "..."
# -------------------------------
sasl_config = f'kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="{client_id}" clientSecret="{client_secret}" scope="https://{event_hubs_server}/.default" ssl.protocol="SSL";'
kafka_options = {
# Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers": f"{event_hubs_server}:9093",
"kafka.sasl.jaas.config": sasl_config,
"kafka.sasl.oauthbearer.token.endpoint.url": f"https://login.microsoft.com/{tenant_id}/oauth2/v2.0/token",
"subscribe": event_hubs_topic,
# You should not need to modify these
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class": "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
}
df = spark.readStream.format("kafka").options(**kafka_options)
display(df)
Scala
// This is the only section you need to modify for auth purposes!
// -------------------------------
val tenantId = "..."
val clientId = "..."
val clientSecret = dbutils.secrets.get("your-scope", "your-secret-name")
val eventHubsServer = "..."
val eventHubsTopic = "..."
// -------------------------------
val saslConfig = s"""kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="$clientId" clientSecret="$clientSecret" scope="https://$eventHubsServer/.default" ssl.protocol="SSL";"""
val kafkaOptions = Map(
// Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers" -> s"$eventHubsServer:9093",
"kafka.sasl.jaas.config" -> saslConfig,
"kafka.sasl.oauthbearer.token.endpoint.url" -> s"https://login.microsoft.com/$tenantId/oauth2/v2.0/token",
"subscribe" -> eventHubsTopic,
// You should not need to modify these
"kafka.security.protocol" -> "SASL_SSL",
"kafka.sasl.mechanism" -> "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class" -> "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
)
val scalaDF = spark.readStream
.format("kafka")
.options(kafkaOptions)
.load()
display(scalaDF)
處理潛在錯誤
不支援串流選項。
如果您嘗試在以 Unity 目錄設定的 DLT 管線中使用此驗證機制,您可能會收到下列錯誤:
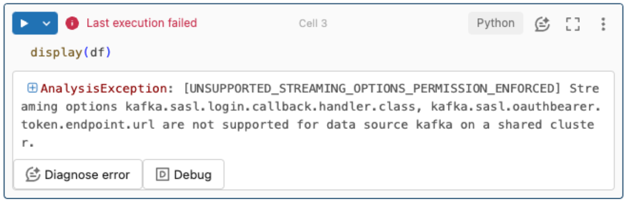
若要解決此錯誤,請使用支援的計算組態。 請參閱使用 Microsoft Entra ID 和 Azure 事件中樞的服務主體認證。
無法建立新的
KafkaAdminClient。此為內部錯誤,在下列任何驗證選項不正確時 Kafka 都會擲回此錯誤:
- 用戶端識別碼 (也稱為應用程式識別碼)
- 租戶識別碼
- EventHubs 伺服器
若要解決錯誤,請確認這些選項的值正確無誤。
此外,如果您修改範例中預設提供的組態選項 (系統要求您不修改),例如
kafka.security.protocol,您可能會看到此錯誤。未傳回任何記錄
如果嘗試顯示或處理 DataFrame 但未取得結果,您將在 UI 中看到下列內容。
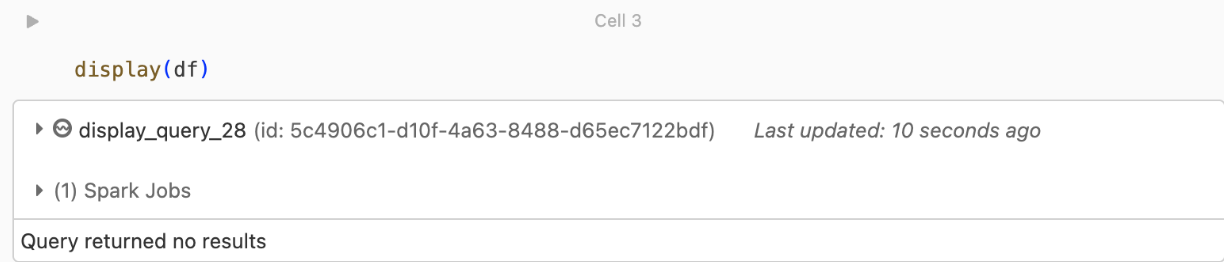
此訊息表示驗證成功,但 EventHubs 未傳回任何資料。 一些可能的 (儘管並不詳盡) 原因包括:
- 指定的 EventHubs 主題錯誤。
-
startingOffsets的預設 Kafka 組態選項是latest,而您目前尚未接收到該 topic 的任何資料。 您可以設定startingOffsetstoearliest,從 Kafka 最早的位移開始讀取數據。