Google BigQuery
本文說明如何在 Azure Databricks 中讀取和寫入 Google BigQuery 數據表。
重要
本文所述的設定為實驗性質。 實驗性功能是以現況提供,且 Databricks 不透過客戶技術支援。 若要取得完整的查詢同盟支援,您應該改用 Lakehouse Federation,讓您的 Azure Databricks 用戶能夠利用 Unity 目錄語法和數據控管工具。
您必須使用金鑰型驗證來連線到 BigQuery。
權限
您的專案必須具有特定的 Google 權限,才能使用 BigQuery 來讀取和寫入。
注意
本文討論 BigQuery 具象化視圖。 如需詳細資訊,請參閱Google文章 具體化檢視簡介。 若要瞭解其他 BigQuery 術語和 BigQuery 資訊安全模型,請參閱 Google BigQuery 文件。
若要使用 BigQuery 讀取和寫入資料,關鍵將取決於兩個 Google Cloud 專案:
- Project (
project):Azure Databricks 從中讀取或寫入 BigQuery 數據表的 Google Cloud 專案識別符。 - 父系專案 (
parentProject):父系專案的識別碼,這是用於讀取和寫入的 Google Cloud 專案識別碼。 將此設定為與您產生密鑰之 Google 服務帳戶相關聯的 Google Cloud 專案。
您必須在存取 BigQuery 的程式代碼中明確提供 project 和 parentProject 值。 請使用與下列類似的程式碼:
spark.read.format("bigquery") \
.option("table", table) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Google Cloud 專案所需的權限取決於 project 和 parentProject 是否相同。 下列各節列出每個案例的必要許可權。
如果 project 和 parentProject 相符,則需要權限
如果您的 project 和 parentProject 識別子相同,請使用下表來判斷最小許可權:
如果 project 和 parentProject 不同,則需要權限
如果您的 project 和 parentProject 識別符不同,請使用下表來判斷最小許可權:
| Azure Databricks 工作 | 需要 Google 權限 |
|---|---|
| 讀取不含具體化檢視的 BigQuery 數據表 | 在 parentProject 專案中:
在 project 專案中:
|
| 使用具體化檢視讀取 BigQuery 數據表 | 在 parentProject 專案中:
在 project 專案中:
在具體化專案中:
|
| 撰寫 BigQuery 數據表 | 在 parentProject 專案中:
在 project 專案中:
|
步驟 1:設定 Google Cloud
啟用 BigQuery 儲存體 API
BigQuery 儲存體 API 預設會在已啟用 BigQuery 的新 Google Cloud 專案中啟用。 不過,如果您有現有的專案且未啟用 BigQuery 儲存體 API,請遵循本節中的步驟加以啟用。
您可以使用 Google Cloud CLI 或 Google Cloud Console 來啟用 BigQuery 儲存體 API。
使用 Google Cloud CLI 啟用 BigQuery 儲存體 API
gcloud services enable bigquerystorage.googleapis.com
使用 Google Cloud Console 啟用 BigQuery 儲存體 API
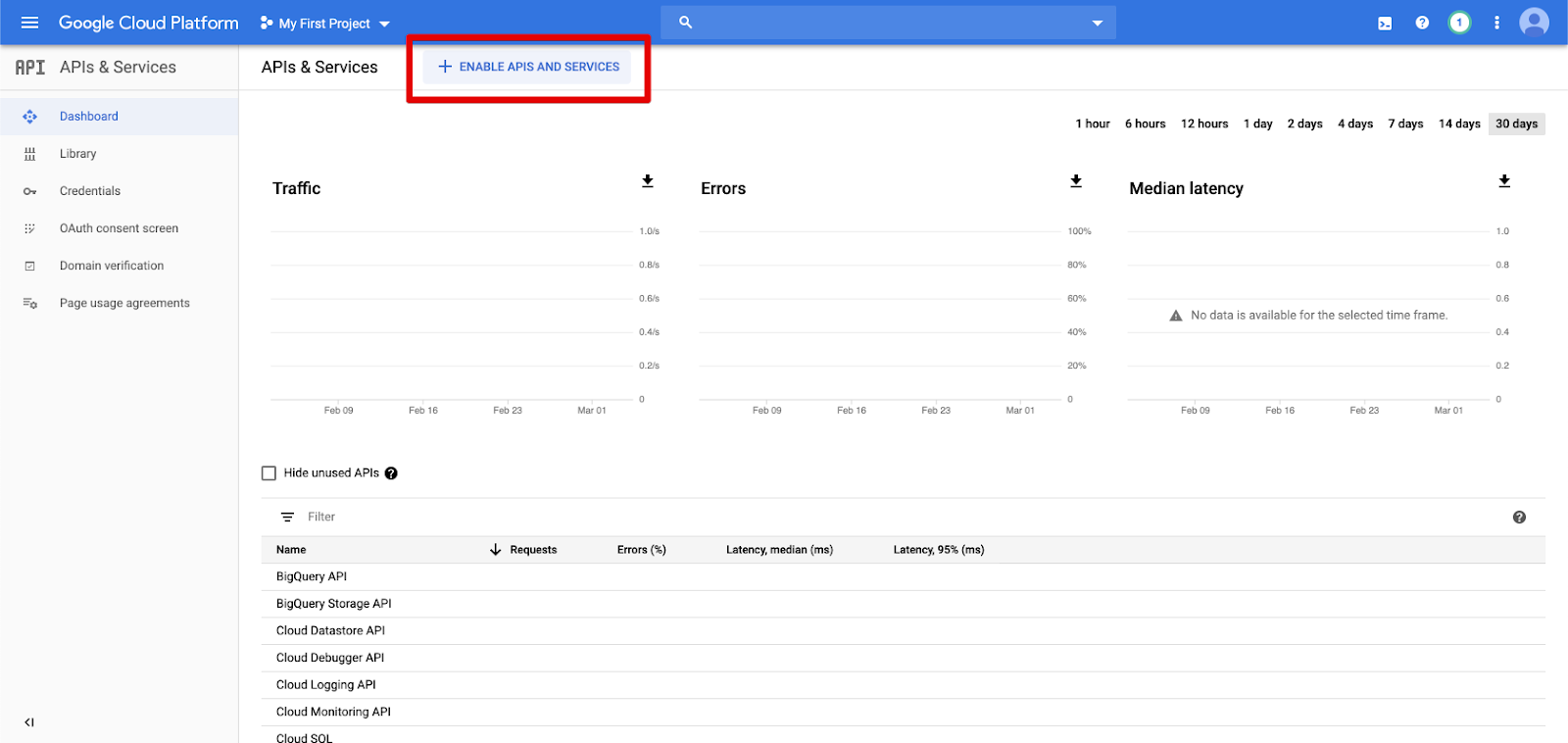
在左側瀏覽窗格中,按一下 [API 與服務]。
按一下 [啟用 API 與服務] 按鈕。
在搜尋列中輸入
bigquery storage api,然後選取第一個結果。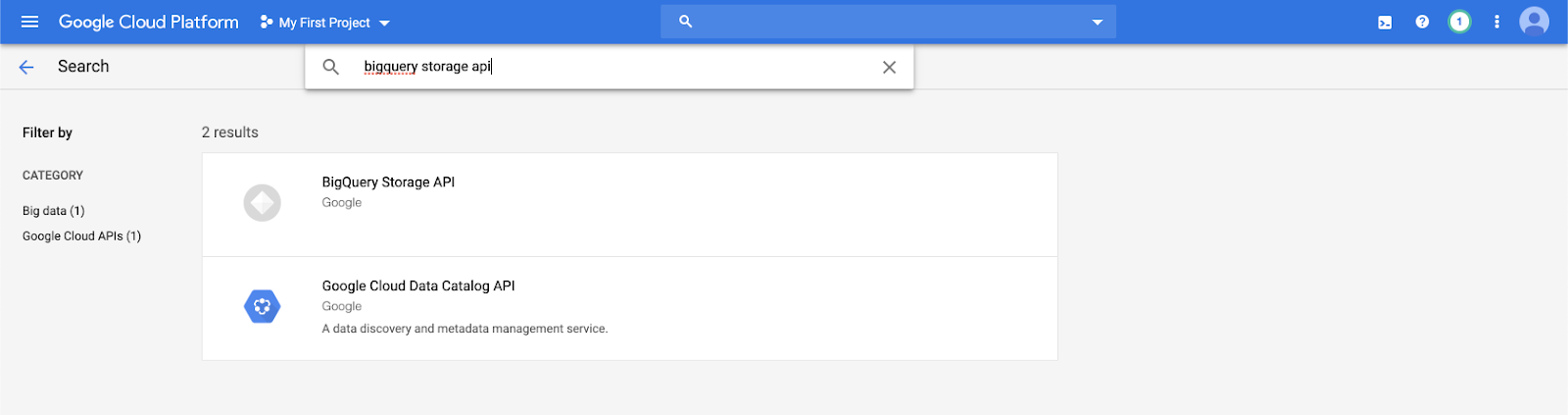
確定已啟用 BigQuery 儲存體 API。
建立 Azure Databricks 的 Google 服務帳戶
建立 Azure Databricks 叢集的服務帳戶。 Databricks 建議您對此服務帳戶授與執行其工作所需的最低權限。 請參閱 BigQuery 角色與權限 (英文)。
您可以使用 Google Cloud CLI 或 Google Cloud Console 來建立服務帳戶。
使用 Google Cloud CLI 建立 Google 服務帳戶
gcloud iam service-accounts create <service-account-name>
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.user \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.dataEditor \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
建立服務帳戶的金鑰:
gcloud iam service-accounts keys create --iam-account \
"<service-account-name>@<project-name>.iam.gserviceaccount.com" \
<project-name>-xxxxxxxxxxx.json
使用 Google Cloud Console 建立 Google 服務帳戶
若要建立帳戶:
在左側瀏覽窗格中,按一下 [IAM 和系統管理員]。
按一下 [服務帳戶]。
按一下 [+ 建立服務帳戶]。
輸入服務帳戶的名稱與描述。
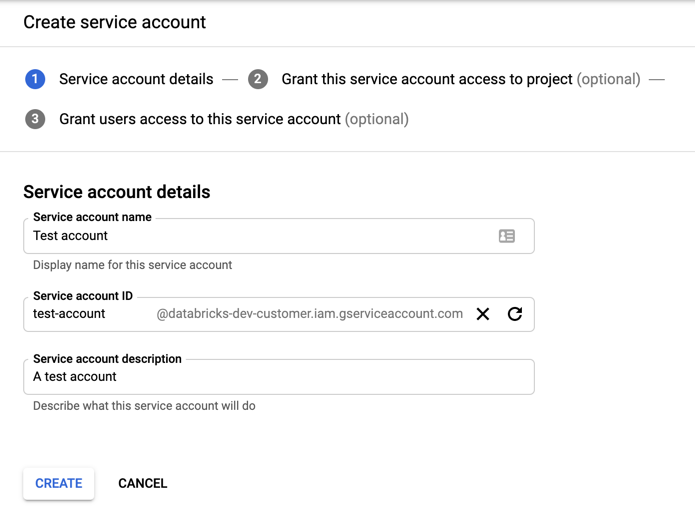
按一下 [建立]。
指定服務帳戶的角色。 在 [選取角色] 下拉式清單中,請輸入
BigQuery並新增下列角色: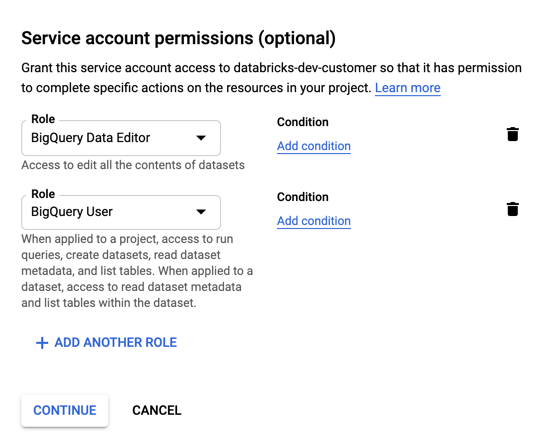
按一下 [繼續]。
按一下 [完成]。
若要為您的服務帳戶建立金鑰:
在服務帳戶清單中,按一下您新建立的帳戶。
在 [金鑰] 區段中,選取 [新增密鑰] > [建立新金鑰] 按鈕。
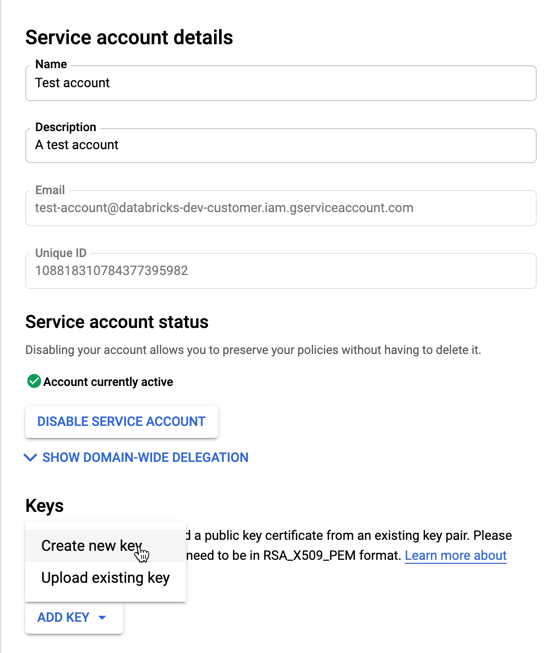
接受 JSON 金鑰類型。
按一下 "建立"。 系統會將 JSON 金鑰檔案下載到您的電腦內。
重要
您為服務帳戶產生的 JSON 金鑰檔案是一個私鑰,應該只與授權的使用者共用,因為它會控制您 Google Cloud 帳戶中數據集和資源的訪問許可權。
建立一個用於暫時性儲存的 Google Cloud Storage (GCS) 儲存區
若要將資料寫入 BigQuery,資料來源會需要存取 GCS 貯體。
在左側瀏覽窗格中,按一下「儲存體」。
按一下 [建立儲存桶]。
設定儲存桶詳細資料。
按一下「建立」
。 按一下 [權限] 索引標籤和 [新增成員]。
為儲存桶上的服務帳戶提供下列權限。
按一下 [儲存]。
步驟 2:設定 Azure Databricks
若要設定叢集來存取 BigQuery 數據表,您必須提供 JSON 金鑰檔案作為 Spark 組態。 使用本機工具將您的 JSON 金鑰檔案以 Base64 進行編碼。 基於安全性目的,請勿使用可存取金鑰的網頁式或遠端工具。
當您 設定叢集時:
在 [Spark 組態] 索引標籤中新增下列 Spark 組態。使用採用 Base64 編碼之 JSON 金鑰檔案的字串取代 <base64-keys>。 將括號中的其他項目(例如 <client-email>)替換為您 JSON 金鑰檔案中這些欄位的值。
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key <private-key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private-key-id>
讀取和寫入 BigQuery 數據表
若要讀取 BigQuery 數據表,請指定
df = spark.read.format("bigquery") \
.option("table",<table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
若要寫入 BigQuery 數據表,請指定
df.write.format("bigquery") \
.mode("<mode>") \
.option("temporaryGcsBucket", "<bucket-name>") \
.option("table", <table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.save()
其中 <bucket-name> 是您在 建立 Google Cloud Storage(GCS)儲存桶中建立的桶名稱,用於暫時存放記憶體。 請參閱 許可權 以瞭解 <project-id> 和 <parent-id> 值的需求。
從 BigQuery 建立外部數據表
重要
Unity 目錄不支援此功能。
您可以在 Databricks 中建立一個未管理的資料表,直接從 BigQuery 讀取資料:
CREATE TABLE chosen_dataset.test_table
USING bigquery
OPTIONS (
parentProject 'gcp-parent-project-id',
project 'gcp-project-id',
temporaryGcsBucket 'some-gcp-bucket',
materializationDataset 'some-bigquery-dataset',
table 'some-bigquery-dataset.table-to-copy'
)
Python 筆記本範例:將 Google BigQuery 數據表載入 DataFrame
下列 Python 筆記本會將 Google BigQuery 數據表載入 Azure Databricks DataFrame。
Google BigQuery Python 範例筆記本
Scala 筆記本範例:將Google BigQuery 數據表載入 DataFrame
下列 Scala 筆記本會將 Google BigQuery 數據表載入 Azure Databricks DataFrame。