適用於 Apache Spark 的 Azure 數據總管連接器
Apache Spark 是用於進行大規模資料處理的整合分析引擎。 Azure 資料總管是快速、完全受控的資料分析服務,可即時分析大量資料流。
適用於 Spark 的 Kusto 連接器是可在任何 Spark 叢集上執行的開放原始碼專案。 它會實作資料來源和資料接收器,以在 Azure 資料總管和 Spark 叢集之間移動資料。 使用 Azure 資料總管和 Apache Spark,您可以建置以數據驅動案例為目標的快速且可調整的應用程式。 例如,機器學習 (ML)、擷取-轉換-載入 (ETL) 和日誌分析。 透過連接器,Azure 資料總管會成為標準 Spark 來源和匯入作業的有效資料存放區,例如寫入、讀取和寫入資料流。
您可以透過佇列擷取或串流擷取寫入 Azure 資料總管。 從 Azure 資料探勘器讀取支援資料欄剪枝和條件下推,這些功能可篩選 Azure 資料探勘器中的資料,從而減少傳輸的資料量。
注意
如需使用適用於 Azure 數據總管的 Synapse Spark 連接器的詳細資訊,請參閱 使用適用於 Azure Synapse Analytics 的 Apache Spark 連線到 Azure 數據總管。
本主題描述如何安裝和設定 Azure 數據總管 Spark 連接器,以及在 Azure 數據總管和 Apache Spark 叢集之間移動資料。
注意
雖然下列一些範例參考 Azure Databricks Spark 叢集,但 Azure Data Explorer Spark 連接器不會直接相依於 Databricks 或任何其他 Spark 散發。
必要條件
- Azure 訂用帳戶。 建立免費的 Azure 帳戶。
- Azure 資料總管叢集和資料庫。 建立叢集和資料庫。
- Spark 叢集
- 安裝連接器程式庫:
- Maven 3.x 已安裝
提示
Spark 2.3.x 版本也受到支援,但可能需要變更pom.xml相依性。
如何建置 Spark 連接器
從 2.3.0 版開始,我們引進了新成品識別碼以取代 spark-kusto-connector:kusto-spark_3.0_2.12,以 Spark 3.x 和 Scala 2.12 為目標。
注意
2.5.1 之前的版本無法再用於擷取至現有資料表,請更新為較新的版本。 此為選用步驟。 如果您使用預先建置的程式庫,例如 Maven,請參閱 Spark 叢集設定。
建置必要條件
請參閱此來源以建置 Spark 連接器。
針對使用 Maven 專案定義的 Scala/Java 應用程式,請將您的應用程式與最新的構建產物鏈結。 在Maven Central上尋找最新的構件。
For more information, see [https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12](https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12).如果您未使用預先建置的程式庫,您必須安裝相依性中列出的程式庫,包括下列 Kusto Java SDK 程式庫。 若要尋找要安裝的正確版本,請查看相關版本的 pom:
若要建置 jar 並執行所有測試:
mvn clean package -DskipTests若要建置 jar、執行所有測試,並將 jar 安裝到本機 Maven 存放庫:
mvn clean install -DskipTests
如需詳細資訊,請參閱連接器使用方式。
Spark 叢集設定
注意
建議在執行下列步驟時使用最新的 Kusto Spark 連接器版本。
根據 Azure Databricks 叢集 Spark 3.0.1 和 Scala 2.12 設定下列 Spark 叢集設定:
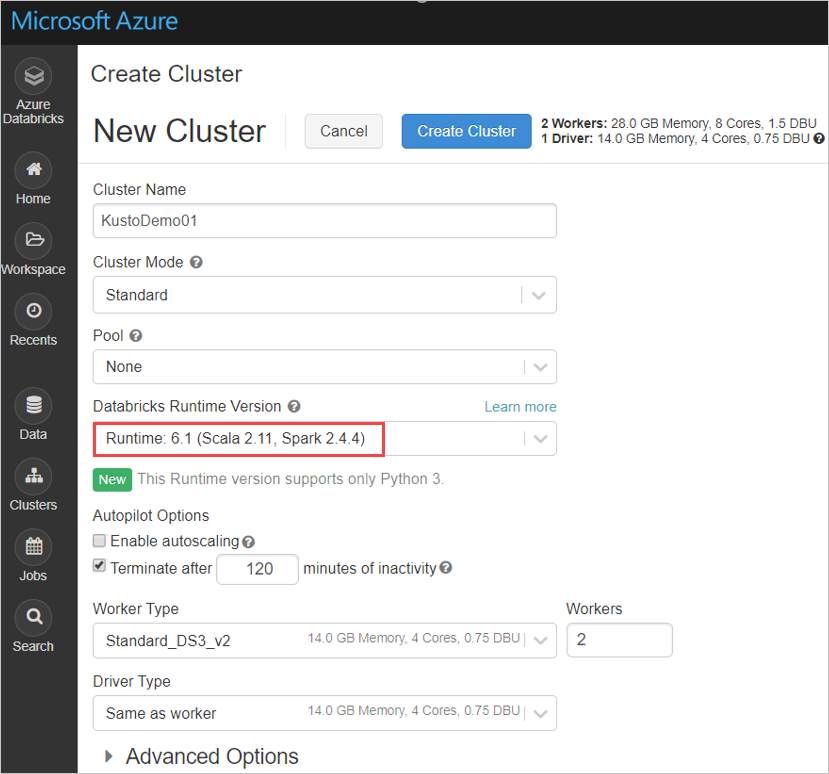
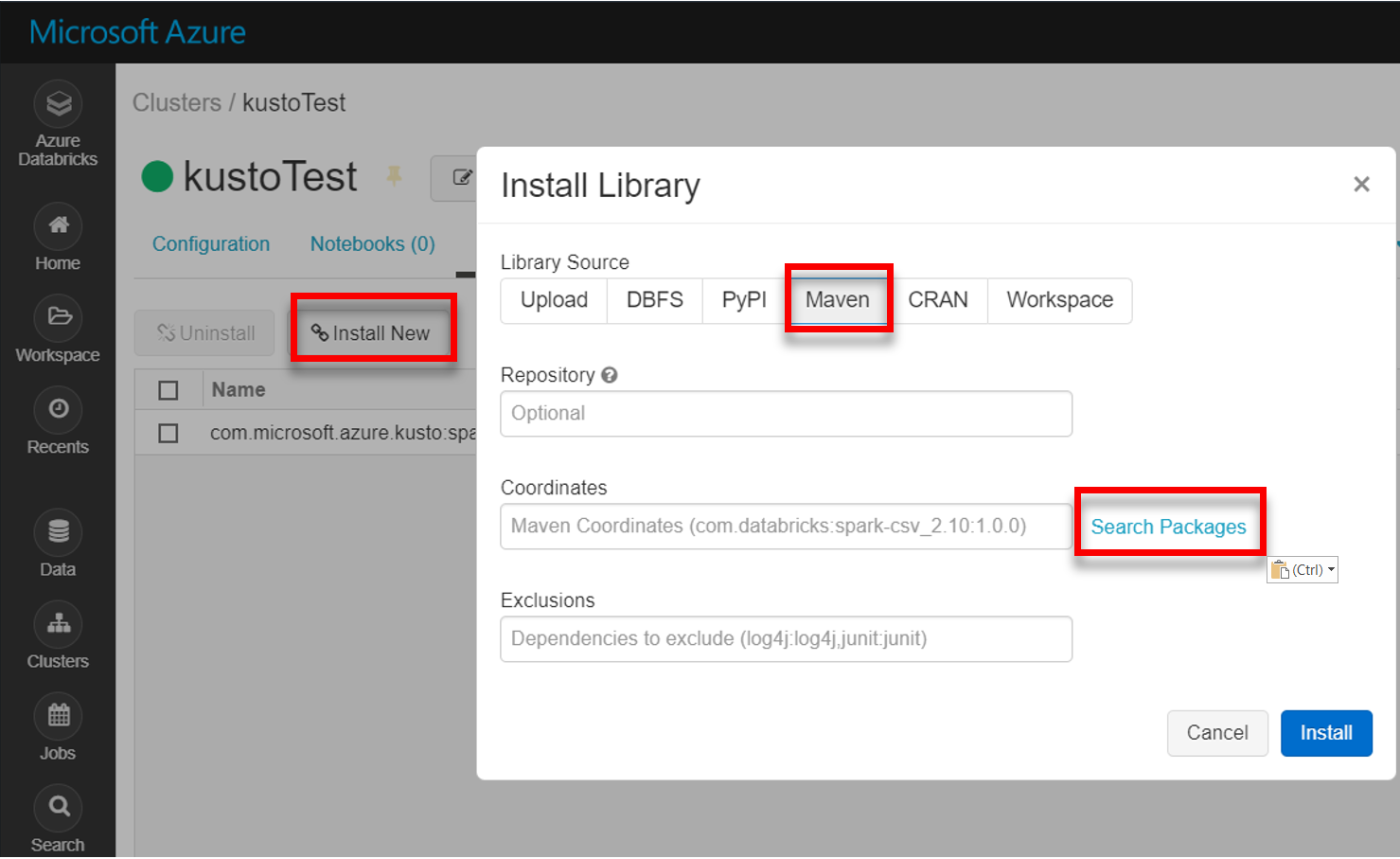
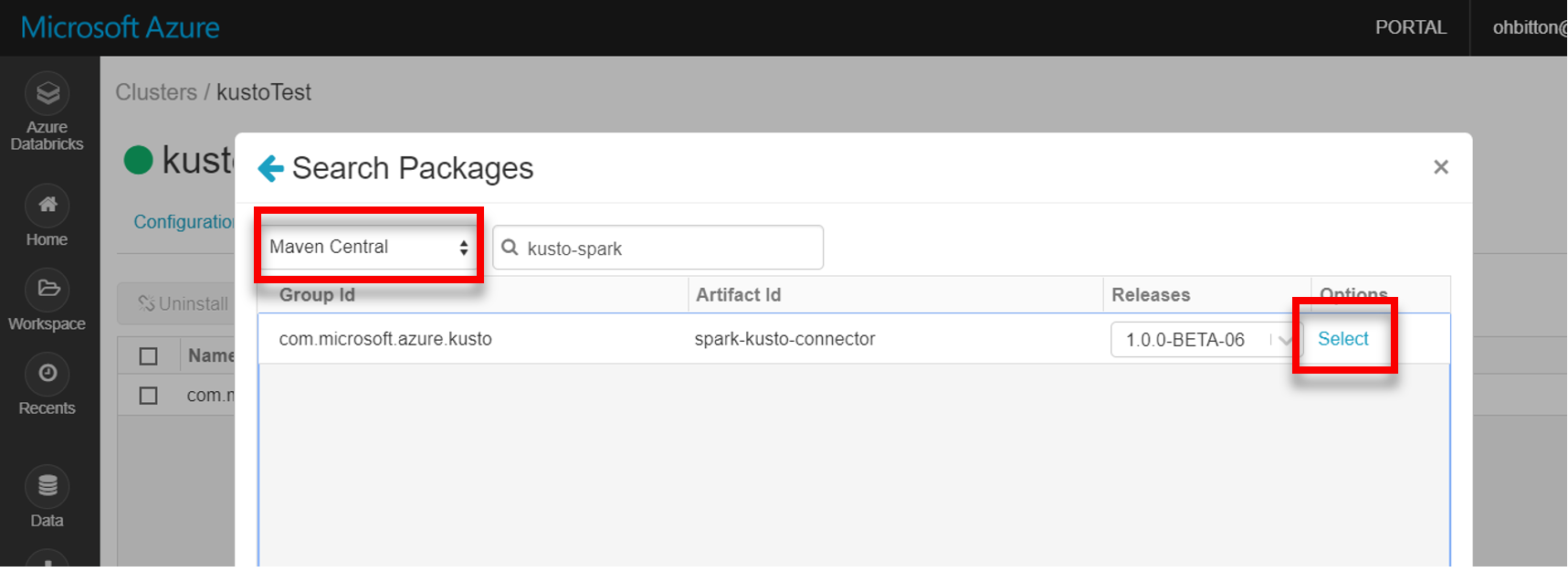
從 Maven 安裝最新的 spark-kusto-connector 程式庫:
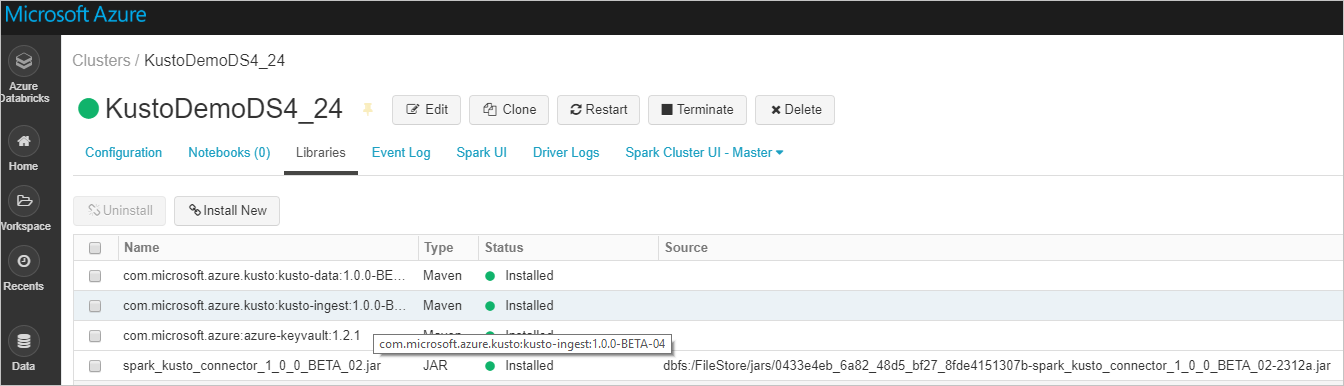
驗證已安裝所有必要的程式庫:
若要使用 JAR 檔案進行安裝,請驗證已安裝其他相依性:
驗證
Kusto Spark 連接器可讓您使用下列其中一種方法,向 Microsoft Entra ID 進行驗證:
- Microsoft Entra 應用程式
- Microsoft Entra 存取權標記
- 裝置驗證 (適用於非生產案例)
- Azure 金鑰保存庫 若要存取金鑰保存庫資源,請安裝 azure-keyvault 套件並提供應用程式認證。
Microsoft Entra 應用程式驗證
Microsoft Entra 應用程式驗證是最簡單且最常見的驗證方法,建議用於 Kusto Spark 連接器。
透過 Azure CLI 登入您的 Azure 訂用帳戶。 然後在瀏覽器中進行驗證。
az login選擇用來託管主體的訂用帳戶。 當您有多個訂用帳戶時,需要此步驟。
az account set --subscription YOUR_SUBSCRIPTION_GUID建立服務主體。 在此範例中,服務主體稱為
my-service-principal。az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}從傳回的 JSON 資料中,複製
appId、password和tenant供日後使用。{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
您已建立您的 Microsoft Entra 應用程式和服務主體。
Spark 連接器會使用下列 Entra 應用程式屬性進行驗證:
| 屬性 | 選項字串 | 描述 |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Microsoft Entra 應用程式 (用戶端) 識別碼。 |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID(Kusto AAD 身分識別碼) | Microsoft Entra 驗證授權單位。 Microsoft Entra 目錄 (租用戶) 識別碼。 選用 - 預設為 microsoft.com。 如需詳細資訊,請參閱 Microsoft Entra 授權單位。 |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | Microsoft Entra 應用程式用戶端金鑰。 |
| KUSTO_ACCESS_TOKEN | kustoAccessToken | 如果您已經有使用 Kusto 的存取權建立的 accessToken,則可以用來傳遞至連接器以及進行驗證。 |
注意
舊版 API 版本 (小於 2.0.0) 具有下列命名:"kustoAADClientID"、"kustoClientAADClientPassword"、"kustoAADAuthorityID"
Kusto 權限
根據您想要執行的 Spark 作業,授與 Kusto 端下列權限。
| Spark 作業 | 權限 |
|---|---|
| 閱讀 - 單一模式 | 讀者 |
| 讀取 - 強制分散模式 | 讀者 |
| 寫入 - 佇列模式,其中包含 CreateTableIfNotExist 資料表建立選項 | 管理員 |
| 寫入 - 具有 FailIfNotExist 資料表建立選項的佇列模式 | 資料匯入器 |
| 寫入 - TransactionalMode | 管理員 |
如需主體角色的詳細資訊,請參閱角色型存取控制。 如需管理安全性角色,請參閱安全性角色管理。
Spark 接收器:寫入 Kusto
設定匯流排參數:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"以批次形式將 Spark DataFrame 寫入 Kusto 叢集:
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()或使用簡化的語法:
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ // Optional, for any extra options: val conf: Map[String, String] = Map() val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)寫入串流資料:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // As an alternative to adding .option by .option, you can provide a map: val conf: Map[String, String] = Map( KustoSinkOptions.KUSTO_CLUSTER -> cluster, KustoSinkOptions.KUSTO_TABLE -> table, KustoSinkOptions.KUSTO_DATABASE -> database, KustoSourceOptions.KUSTO_ACCESS_TOKEN -> accessToken) // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Spark 來源:從 Kusto 讀取
讀取少量資料時,定義資料查詢:
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)選用:如果您提供暫存的 Blob 儲存體(而非 Kusto),則會由呼叫者負責建立 Blob。 這包括佈建儲存體、輪替存取金鑰,以及刪除暫時性資源。 KustoBlobStorageUtils 模組包含輔助函式,用於根據帳戶和容器座標及帳戶憑證,或使用具有寫入、讀取和列出權限的完整 SAS URL,來刪除 Blob。 不再需要對應的 RDD 時,每個交易都會將暫時性 Blob 成品儲存在個別的目錄中。 此目錄會作為讀取交易資訊記錄的一部分,擷取並報告於 Spark 驅動程式節點上。
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")在上述範例中,不會使用連接器介面存取金鑰保存庫;會使用運用 Databricks 秘密這種更為簡單的方法。
從 Kusto 讀取。
如果您提供暫時性 Blob 儲存體,請按照以下方式從 Kusto 讀取:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)如果 Kusto 提供暫時的 Blob 儲存體,請從 Kusto 讀取,如以下所示:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)