教學課程:適用於 PostgreSQL 的 Azure Cosmos DB 中背景工作角色節點上的分區資料
適用於:![]() Azure Cosmos DB for PostgreSQL (由 PostgreSQL 的 Citus 資料庫延伸模組提供)
Azure Cosmos DB for PostgreSQL (由 PostgreSQL 的 Citus 資料庫延伸模組提供)
在此教學課程中,您會使用 Azure Cosmos DB for PostgreSQL 來瞭解如何:
- 建立雜湊分散式分區
- 查看資料表分區的位置
- 識別扭曲分佈
- 建立分散式資料表的限制式
- 對分散式資料執行查詢
必要條件
此教學課程需要有兩個背景工作角色節點的執行中叢集。 如果您沒有執行中的叢集,請遵循建立叢集教學課程,然後再執行一次。
雜湊分散式資料
將資料表資料列散發到多個 PostgreSQL 伺服器,是在 Azure Cosmos DB for PostgreSQL 中可調整查詢的關鍵技巧。 同時,多個節點可以保留比傳統資料庫更多的資料,而且在許多情況下,也可以平行使用背景工作角色 CPU 來執行查詢。 雜湊分散式資料表的概念也稱為資料列型分區化。
在必要條件一節中,我們建立了具有兩個背景工作角色節點的叢集。
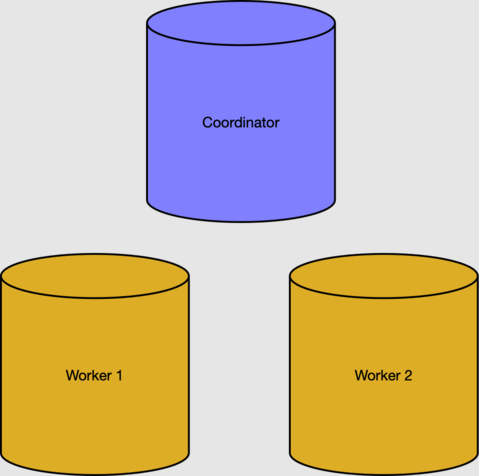
協調器節點的中繼資料資料表會追蹤背景工作角色和分散式資料。 我們可以在 pg_dist_node 資料表中檢查作用中的背景工作角色。
select nodeid, nodename from pg_dist_node where isactive;
nodeid | nodename
--------+-----------
1 | 10.0.0.21
2 | 10.0.0.23
注意
Azure Cosmos DB for PostgreSQL 的節點名稱是虛擬網路中的內部 IP 位址,您看到的實際位址可能有所不同。
資料列、分區和放置
若要使用背景工作角色節點的 CPU 和儲存體資源,我們必須在整個叢集中散發資料表資料。 散發資料表會將每個資料列指派給名為「分區」的邏輯群組。讓我們建立一個資料表並散發:
-- create a table on the coordinator
create table users ( email text primary key, bday date not null );
-- distribute it into shards on workers
select create_distributed_table('users', 'email');
Azure Cosmos DB for PostgreSQL 會根據「散發資料行」的值,將每個資料列指派給分區,在我們的案例中指定為 email。 每個資料列只會有一個分區,而每個分區都可以包含多個資料列。
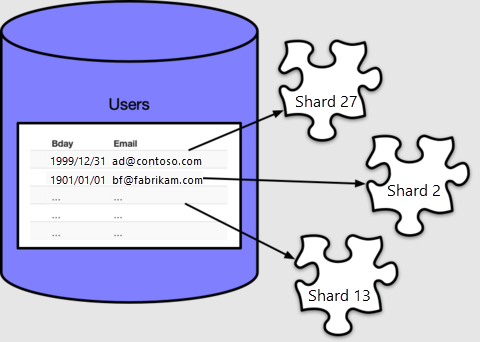
根據預設 create_distributed_table() 會有 32 個分區,如我們在中繼資料資料表中的計數 pg_dist_shard 中所見:
select logicalrelid, count(shardid)
from pg_dist_shard
group by logicalrelid;
logicalrelid | count
--------------+-------
users | 32
Azure Cosmos DB for PostgreSQL 會根據散發資料行中值的雜湊,使用 pg_dist_shard 資料表來指派要分區的資料列。 在此教學課程中,雜湊詳細資料並不重要。 重要的是,我們可以查詢以查看哪些值會對應至哪些分區識別碼:
-- Where would a row containing hi@test.com be stored?
-- (The value doesn't have to actually be present in users, the mapping
-- is a mathematical operation consulting pg_dist_shard.)
select get_shard_id_for_distribution_column('users', 'hi@test.com');
get_shard_id_for_distribution_column
--------------------------------------
102008
將資料列對應至分區是純粹的邏輯概念。 分區必須指派給特定的背景工作角色節點以進行儲存,Azure Cosmos DB for PostgreSQL 稱之為「分區放置」。
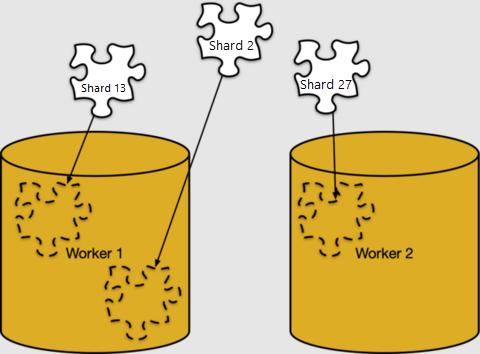
我們可以查看 pg_dist_placement 中的分區放置。 將其與我們所看到的其他中繼資料資料表聯結,會顯示每個分區的所在位置。
-- limit the output to the first five placements
select
shard.logicalrelid as table,
placement.shardid as shard,
node.nodename as host
from
pg_dist_placement placement,
pg_dist_node node,
pg_dist_shard shard
where placement.groupid = node.groupid
and shard.shardid = placement.shardid
order by shard
limit 5;
table | shard | host
-------+--------+------------
users | 102008 | 10.0.0.21
users | 102009 | 10.0.0.23
users | 102010 | 10.0.0.21
users | 102011 | 10.0.0.23
users | 102012 | 10.0.0.21
資料扭曲
將資料平均放在背景工作角色節點上時,以及將相關資料放在相同的背景工作角色上時,叢集的執行效率會最高。 在本節中,我們會將重點放在第一個部分,也就是放置的一致性。
為了示範,讓我們建立 users 資料表的範例資料:
-- load sample data
insert into users
select
md5(random()::text) || '@test.com',
date_trunc('day', now() - random()*'100 years'::interval)
from generate_series(1, 1000);
若要查看分區大小,可以在分區上執行資料表大小函式。
-- sizes of the first five shards
select *
from
run_command_on_shards('users', $cmd$
select pg_size_pretty(pg_table_size('%1$s'));
$cmd$)
order by shardid
limit 5;
shardid | success | result
---------+---------+--------
102008 | t | 16 kB
102009 | t | 16 kB
102010 | t | 16 kB
102011 | t | 16 kB
102012 | t | 16 kB
可以看到分區的大小相同。 我們已經看到放置平均分散在背景工作角色中,因此可以推斷背景工作角色節點的資料列數大致相等。
由於散發資料行的屬性 email,users 範例中的資料列會平均分佈。
- 電子郵件地址數目大於或等於分區數目。
- 每個電子郵件地址的資料列數目都很相似 (在我們的案例中,每個位址只會有一個資料列,因為針對電子郵件宣告了索引鍵)。
選擇任何一個屬性失敗的資料表和散發資料行,將會在背景工作角色上產生不平均的資料大小,也就是「資料扭曲」。
將限制式新增至分散式資料
使用 Azure Cosmos DB for PostgreSQL 可讓您繼續享有關聯式資料庫的安全性,包括資料庫限制式。 不過,有一個限制。 由於散發式系統的本質,Azure Cosmos DB for PostgreSQL 不會交叉參照背景工作角色節點之間的唯一性限制式或參考完整性。
讓我們將 users 資料表範例視為相關資料表。
-- books that users own
create table books (
owner_email text references users (email),
isbn text not null,
title text not null
);
-- distribute it
select create_distributed_table('books', 'owner_email');
為了提高效率,我們會以與 users 相同的方式散發 books:依擁有者的電子郵件地址。 依類似的資料行值來散發,稱為共置。
由於索引鍵是位於散發資料行,因此將外部索引鍵散發給使用者不會出現問題。 不過,我們會在授與 isbn 索引鍵時遇到問題:
-- will not work
alter table books add constraint books_isbn unique (isbn);
ERROR: cannot create constraint on "books"
DETAIL: Distributed relations cannot have UNIQUE, EXCLUDE, or
PRIMARY KEY constraints that do not include the partition column
(with an equality operator if EXCLUDE).
在分散式資料表中,最佳作法是將資料行唯一的模數設為散發資料行:
-- a weaker constraint is allowed
alter table books add constraint books_isbn unique (owner_email, isbn);
上述限制式只會讓每位使用者都具有唯一的 isbn。 另一個選項是讓書籍成為參考資料表 而不是分散式資料表,並建立與使用者相關聯的個別分散式資料表。
查詢分散式資料表
在先前的章節中,我們已了解如何將分散式資料表資料列放在背景工作角色節點的分區中。 在大部分的情況下,您不需要知道資料在叢集中的儲存方式,或應該將資料儲存在哪個叢集中。 Azure Cosmos DB for PostgreSQL 具有自動分割一般 SQL 查詢的分散式查詢執行程式。 其會在接近資料的背景工作角色節點上平行執行。
例如,我們可以執行查詢來尋找使用者的平均存留期,將分散式 users 資料表視為協調器上的一般資料表。
select avg(current_date - bday) as avg_days_old from users;
avg_days_old
--------------------
17926.348000000000
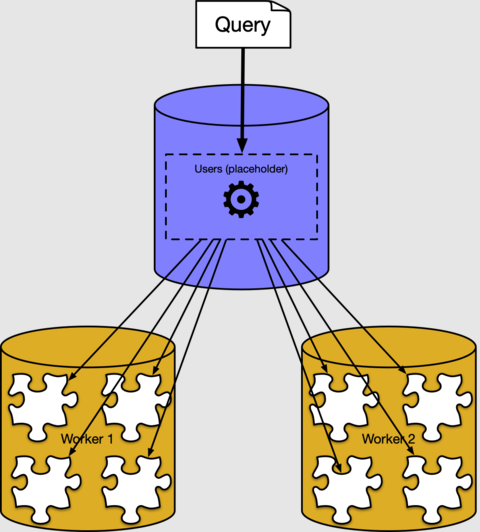
Azure Cosmos DB for PostgreSQL 執行程式會在背景為每個分區建立個別的查詢,並在背景工作角色上執行,並結合結果。 如果您使用 PostgreSQL EXPLAIN 命令,就能看到:
explain select avg(current_date - bday) from users;
QUERY PLAN
----------------------------------------------------------------------------------
Aggregate (cost=500.00..500.02 rows=1 width=32)
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=100000 width=16)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=10.0.0.21 port=5432 dbname=citus
-> Aggregate (cost=41.75..41.76 rows=1 width=16)
-> Seq Scan on users_102040 users (cost=0.00..22.70 rows=1270 width=4)
輸出會顯示「查詢片段」的執行計畫範例,其在分區102040 (背景工作角色 10.0.0.21 上的資料表 users_102040) 上。 其他片段則不會顯示,因為非常類似。 我們可以看到背景工作角色節點會掃描分區資料表,並套用彙總。 協調器節點會結合並最終結果的彙總。
下一步
在本教學課程中,我們建立了分散式資料表,並了解其分區和放置。 我們看到了使用唯一性與外部索引鍵限制式的挑戰,最後也看到分散式查詢在高階的工作方式。