在 Azure Cosmos DB for PostgreSQL 中建立即時分析應用程式模型
適用於:![]() Azure Cosmos DB for PostgreSQL (由 PostgreSQL 的 Citus 資料庫延伸模組提供)
Azure Cosmos DB for PostgreSQL (由 PostgreSQL 的 Citus 資料庫延伸模組提供)
使用分區索引鍵共置大型資料表
若要挑選即時作業分析應用程式的分區索引鍵,請遵循下列指導方針:
- 選擇大型資料表上通用的資料行
- 選擇資料中自然維度的資料行,或應用程式的重要部分。 以下是一些範例:
- 在金融世界中,分析安全性趨勢的應用程式可能會使用
security_id。 - 在您想要分析網站使用計量的使用者分析工作負載中,
user_id是良好的散發資料行
- 在金融世界中,分析安全性趨勢的應用程式可能會使用
藉由共置大型資料表,您可以將 SQL 查詢平行向下推送至背景工作角色節點。 向下推送查詢可避免透過網路在節點之間隨機顯示資料。 可以有效率地執行 JOIN、彙總、彙總套件、篩選、LIMIT 等作業。
若要將共置資料表上的平行分散式查詢視覺化,請考慮此圖表:
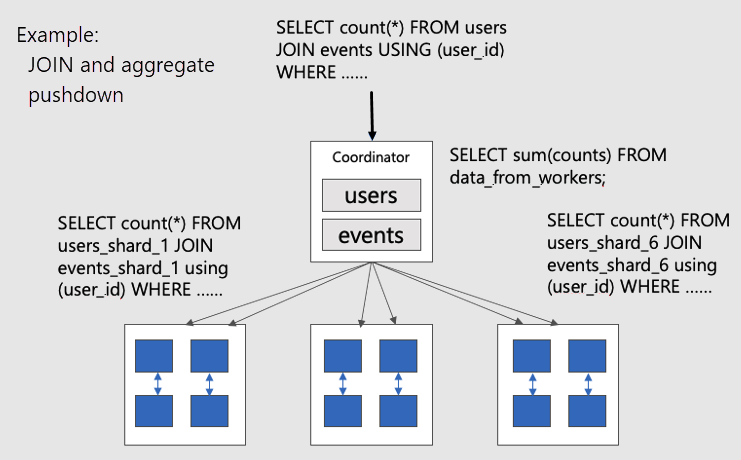
users 和 events 資料表皆由 user_id 分區,因此相同使用者識別碼的相關資料列會放在相同的背景工作角色節點上。 SQL JOIN 不需要在背景工作角色之間提取資訊,即可能發生。
即時應用程式的最佳資料模型
讓我們繼續探討分析使用者網站瀏覽和計量的應用程式範例。 具有兩個「事實」資料表--使用者和事件,以及其他較小的「維度」資料表。
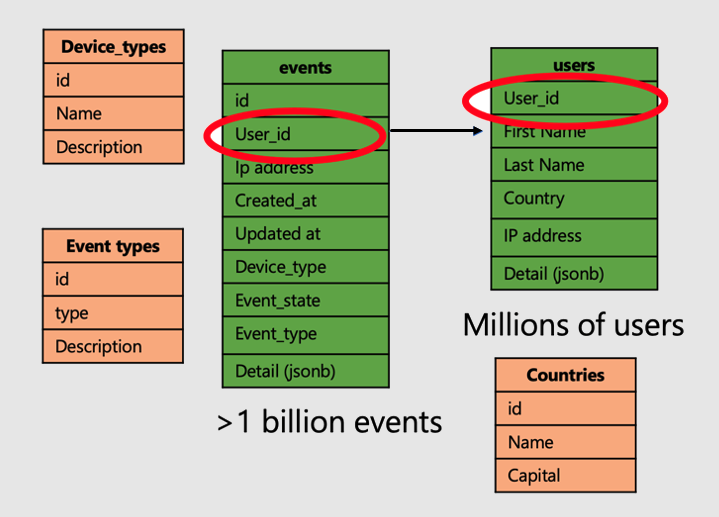
若要在 Azure Cosmos DB for PostgreSQL 上套用分散式資料表的超級能力,請遵循下列步驟:
- 在通用資料行上散發大型事實資料表。 在我們的案例中,使用者和事件會散發在
user_id上。 - 將小型/維度資料表 (
device_types、countries和 'event_types) 標示為參考資料表。 - 請務必在分散式資料行的主要、唯一和外部索引鍵限制式中包含散發資料行。 包含資料行可能需要產生索引鍵複合。 需要更新參考資料表的索引鍵。
- 當您聯結大型分散式資料表時,請務必使用分區索引鍵來聯結。
-- Distribute the fact tables
SELECT create_distributed_table('users', 'user_id');
SELECT create_distributed_table('products', 'user_id', colocate_with => 'users');
-- Turn dimension tables into reference tables, with synchronized copies
-- maintained on every worker node
SELECT create_reference_table('countries');
-- similarly for device_types and event_types...
下一步
現在,我們已完成探索可調整應用程式的資料模型化。 下一步是使用您選擇的程式設計語言來連結和查詢資料庫。