設定活躍度探查
容器化的應用程式可能會執行一段較長的時間,因而導致可能需要藉由重新啟動容器來修復的中斷狀態。 Azure 容器執行個體支援活躍度探查,因此您可以在容器群組內設定容器,以便在重要功能無法運作時重新啟動。 活躍度探查的行為就像 Kubernetes 活躍度探查。
本文說明如何部署包含活躍度探查的容器群組,示範如何自動重新啟動模擬的狀況不良容器。
Azure 容器執行個體也支援整備度探查,您可以設定此探查,以確保流量只在容器準備好時才會到達容器。
YAML 部署
使用下列程式碼片段來建立 liveness-probe.yaml 檔案。 此檔案所定義的容器群組是由最終會變成狀況不良的 NGINX 容器所組成的。
apiVersion: 2019-12-01
location: eastus
name: livenesstest
properties:
containers:
- name: mycontainer
properties:
image: mcr.microsoft.com/oss/nginx/nginx:1.15.5-alpine
command:
- "/bin/sh"
- "-c"
- "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
ports: []
resources:
requests:
cpu: 1.0
memoryInGB: 1.5
livenessProbe:
exec:
command:
- "cat"
- "/tmp/healthy"
periodSeconds: 5
osType: Linux
restartPolicy: Always
tags: null
type: Microsoft.ContainerInstance/containerGroups
執行下列命令,即可使用上述 YAML 設定來部署此容器群組:
az container create --resource-group myResourceGroup --name livenesstest -f liveness-probe.yaml
Start 命令
部署包含定義啟動命令的 command 屬性,該命令會在容器第一次開始執行時執行。 此屬性接受字串陣列。 此命令會模擬進入不良狀態的容器。
首先,其會啟動 bash 工作階段,並在 /tmp 目錄中建立名為 healthy 的檔案。 其接著將在刪除檔案之前先進入睡眠狀態 30 秒,然後再進入睡眠狀態 10 分鐘:
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
活躍度命令
此部署會定義 livenessProbe,以支援可用來作為活躍度檢查的 exec 活躍度命令。 如果此命令以非零值結束,即會終止並重新啟動容器,並發出信號表示找不到 healthy 檔案。 如果此命令已順利結束且結束代碼為 0,則不會採取任何動作。
periodSeconds 屬性會指定活躍度命令應該每隔 5 秒執行一次。
確認活躍度輸出
在第一個 30 秒內,啟動命令所建立的 healthy 就會存在。 當活躍度命令檢查 healthy 檔案是否存在時,狀態碼會傳回 0,發出訊號表示成功,因此不會重新啟動。
30 秒之後,cat /tmp/healthy 命令將開始失敗,因而導致狀況不良和終止事件發生。
這些事件可從 Azure 入口網站或 Azure CLI 來檢視。
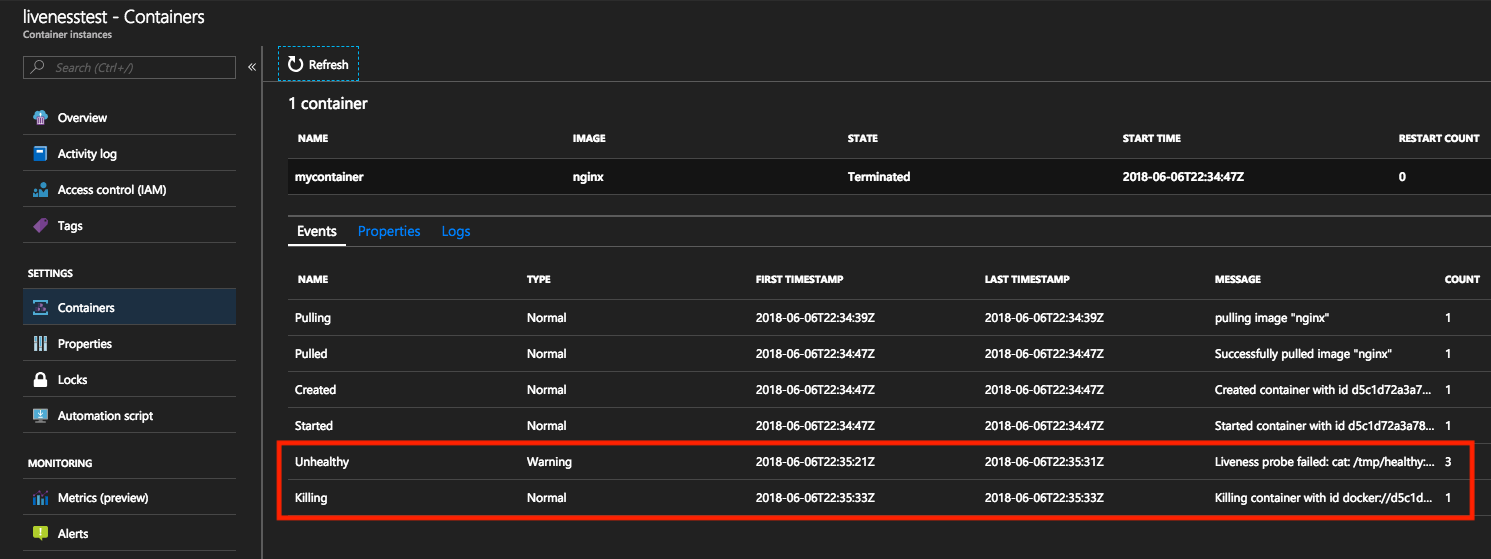
藉由檢視 Azure 入口網站中的事件,將在活躍度命令失敗時觸發類型為 Unhealthy 的事件。 後續的事件類型將是 Killing,表示容器刪除,因此可以開始重新啟動。 適用於容器的重新啟動計數將在每次發生這種事件時遞增。
重新啟動會就地完成,因此將保留像是公用 IP 位址和節點特定內容的資源。

如果活躍度探查持續失敗且觸發太多次重新啟動,容器將進入指數型後端停止延遲。
活躍度探查和重新啟動原則
重新啟動原則會取代活躍度探查所觸發的重新啟動行為。 例如,如果您設定 restartPolicy = Never 和活躍度探查,容器群組將不會因為失敗的活躍度檢查而重新啟動。 容器群組將改為遵守容器群組的 Never 重新啟動原則。
下一步
工作型案例可能需要活躍度探查,以在必要功能未正常運作時啟用自動重新啟動。 如需有關執行工作型容器的詳細資訊,請參閱在 Azure 容器執行個體中執行容器化工作。