HADR 設定最佳做法 (Azure VM 上的 SQL Server)
Windows Server 容錯移轉叢集與 Azure 虛擬機器 (VM) 上的 SQL Server 搭配使用,以進行高可用性和災害復原 (HADR)。
本文提供搭配使用容錯移轉叢集執行個體 (FCI) 和可用性群組與 Azure VM 上的 SQL Server 時的叢集設定最佳做法。
若要深入了解,請參閱此系列的其他文章:檢查清單、VM 大小、儲存體、安全性、HADR 設定、收集基準。
檢查清單
請檢閱下列檢查清單,以簡要了解本文其餘部分將更詳細涵蓋的 HADR 最佳做法。
高可用性和災害復原 (HADR) 功能,例如 Always On 可用性群組,而容錯移轉叢集執行個體會依賴基礎 Windows Server 容錯移轉叢集技術。 請檢閱修改 HADR 設定的最佳做法,以更妥善地支援雲端環境。
針對您的 Windows 叢集,請考慮下列最佳做法:
- 盡可能將 SQL Server VM 部署至多個子網路,以避免依賴 Azure Load Balancer 或分散式網路名稱 (DNN),將流量路由傳送至 HADR 解決方案。
- 將叢集變更為較不積極的參數,以避免因為暫時性網路失敗或 Azure 平台維修而發生非預期的中斷。 若要深入了解,請參閱活動訊號和閾值設定。 針對 Windows Server 2012 和更新版本,請使用下列建議值:
- SameSubnetDelay:1 秒
- SameSubnetThreshold:40 個活動訊號
- CrossSubnetDelay:1 秒
- CrossSubnetThreshold:40 個活動訊號
- 將您的 VM 放置在可用性設定組或不同的可用性區域中。 若要深入了解,請參閱 VM 可用性設定。
- 每個叢集節點都會使用單一 NIC。
- 設定叢集仲裁投票,以使用 3 個或以上的奇數投票。 請不要將投票指派給災害復原區域。
- 請仔細監視資源限制,以避免由於資源限制而造成非預期的重新啟動或容錯移轉。
- 確定您的作業系統、驅動程式和 SQL Server 都是最新組建。
- 針對 Azure VM 上的 SQL Server 最佳化效能。 若要深入了解,請檢閱本文中的其他小節。
- 減少或分散工作負載,以避免資源限制。
- 移至其限制較高的 VM 或磁碟,以避免受到限制。
針對 SQL Server 可用性群組或容錯移轉叢集執行個體,請考慮下列最佳做法:
- 如果您經常遇到非預期的失敗,則請遵循本文其餘部分所述的效能最佳做法。
- 如果最佳化 SQL Server VM 效能無法解決未預期的容錯移轉,則請考慮針對可用性群組或容錯移轉叢集執行個體放寬監視。 不過,這麼做可能無法解決問題的基礎來源,而且可能會透過降低失敗的可能性來掩蓋徵兆。 您可能還是需要調查並解決基礎根本原因。 針對 Windows Server 2012 或更高版本,請使用下列建議值:
- 租用逾時:使用此方程式來計算租用逾時最大值:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
從 40 秒開始。 如果您要使用先前建議的寬鬆SameSubnetThreshold和SameSubnetDelay值,則請不要超過 80 秒的租用逾時值。 - 指定期間內的失敗次數上限:將此值設定為 6。
- 租用逾時:使用此方程式來計算租用逾時最大值:
- 使用虛擬網路名稱 (VNN) 和 Azure Load Balancer 連線至您的 HADR 解決方案時,請在連接字串中指定
MultiSubnetFailover = true,即使您的叢集只橫跨一個子網路也是一樣。- 如果用戶端不支援
MultiSubnetFailover = True,則您可能需要設定RegisterAllProvidersIP = 0和HostRecordTTL = 300,以在較短的時間內快取用戶端認證。 不過,這麼做可能會對 DNS 伺服器造成額外的查詢。
- 如果用戶端不支援
- 若要使用分散式網路名稱 (DNN) 連線至 HADR 解決方案,請考慮下列事項:
- 您必須使用支援
MultiSubnetFailover = True的用戶端驅動程式,且此參數必須在連接字串中。 - 連線至可用性群組的 DNN 接聽程式時,請在連接字串中使用唯一的 DNN 連接埠。
- 您必須使用支援
- 針對基本可用性群組使用資料庫鏡像連接字串,以略過負載平衡器或 DNN 的需求。
- 在部署高可用性解決方案之前,請先驗證 VHD 的磁區大小,以避免發生不一致的 I/O。 若要深入了解,請參閱 KB3009974。
- 如果 SQL Server 資料庫引擎、Always On 可用性群組接聽程式或容錯移轉叢集執行個體健康情況探查設定為使用 49,152 與 65,536 之間的連接埠 (TCP/IP 的預設動態連接埠範圍),則請新增每個連接埠的排除。 這樣做將讓其他系統無法動態指派相同的連接埠。 下列範例會建立連接埠 59999 的排除:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
若要將 HADR 檢查清單與其他最佳做法相互比較,請參閱完整的效能最佳做法檢查清單。
VM 可用性設定
若要降低停機的影響,請考慮下列 VM 最佳可用性設定:
- 搭配使用鄰近放置群組與加速網路,以提供最低延遲。
- 將虛擬機器叢集節點放在不同的可用性區域以防止資料中心層級的失敗,或放在相同資料中心內的單一可用性設定組以提供低延遲備援。
- 針對可用性設定組中的 VM 使用進階受控作業系統和資料磁碟。
- 將每個應用程式層設定至不同的可用性設定組。
Quorum
雖然雙節點叢集在沒有仲裁資源的情況下運作,但客戶必須使用仲裁資源,才能取得生產支援。 叢集驗證不會傳遞沒有仲裁資源的任何叢集。
技術上來說,三節點叢集在沒有仲裁資源的情況下,可以承受單一節點遺失 (減少至兩個節點),但在叢集關閉至兩個節點之後,如果遺失另一個節點或通訊失敗,則叢集資源將會離線,以防止拆分案例。 設定仲裁資源將允許叢集在線上只有一個節點的情況下繼續連線。
磁碟見證是最有彈性的仲裁選項,但若要在 Azure VM 上的 SQL Server 上使用磁碟見證,您必須使用 Azure 共用磁碟,以對高可用性解決方案施加一些限制。 因此,當您使用 Azure 共用磁碟設定容錯移轉叢集執行個體時,請使用磁碟見證,否則請盡可能使用雲端見證。
下表列出 Azure VM 上 SQL Server 可用的仲裁選項:
| 雲端見證 | 磁碟見證 | 檔案共用見證 | |
|---|---|---|---|
| 支援的 OS | Windows Server 2016+ | 全部 | 全部 |
- 「雲端見證」適用於多個網站、多個區域 (zone) 和多個區域 (region) 中的部署。 除非您使用共用儲存體叢集解決方案,否則請盡可能使用雲端見證。
- 「磁碟見證」是最具復原性的仲裁選項,且適用於使用 Azure 共用磁碟 (或任何共用磁碟解決方案,例如共用 SCSI、iSCSI 或光纖通道 SAN) 的任何叢集。 叢集共用磁碟區不能用來作為磁碟見證。
- 「檔案共用見證」適用於磁碟見證和雲端見證無法使用的情況。
若要開始使用,請參閱設定叢集仲裁。
仲裁投票
您可以變更參與 Windows Server 容錯移轉叢集之節點的仲裁投票。
修改節點投票設定時,請遵循下列指導方針:
| 仲裁投票指導方針 |
|---|
| 從預設為沒有投票的每個節點開始。 每個節點應該只有一票,而且要有明確的理由。 |
| 針對裝載可用性群組主要複本的叢集節點,或容錯移轉叢集執行個體的慣用擁有者,啟用投票。 |
| 為自動容錯移轉啟用投票。 可能因為自動容錯移轉而裝載主要複本或 FCI 的每個節點,都應該有投票權。 |
| 如果可用性群組有一個以上的次要複本,請只針對具有自動容錯移轉的複本啟用投票。 |
| 為次要災害復原網站中的節點停用投票。 如果主要站台沒有任何問題,則次要站台中的節點不應該餐與將叢集設為離線的決策。 |
| 具有奇數的投票數,最少有三個仲裁投票。 在雙節點叢集中,如有需要,請新增仲裁見證,以進行額外的投票。 |
| 容錯移轉後重新評定投票指派。 您應避免容錯移轉至不支援良好仲裁的叢集設定。 |
連線能力
若要比對連線至可用性群組接聽程式或容錯移轉叢集執行個體的內部部署體驗,請將 SQL Server VM 部署至相同虛擬網路中的多個子網路。 多個子網路不需要 Azure Load Balancer 的額外相依性或是分散式網路名稱,即可將流量路由傳送至您的接聽程式。
若要簡化您的 HADR 解決方案,請盡可能將 SQL Server VM 部署至多個子網路。 若要深入了解,請參閱多重子網路 AG 和多重子網路 FCI。
如果您的 SQL Server VM 位於單一子網路中,則可以為容錯移轉叢集執行個體和可用性群組接聽程式設定虛擬網路名稱 (VNN) 和 Azure Load Balancer 或是分散式網路名稱 (DNN)。
如果有的話,則分散式網路名稱是建議的連線選項:
- 端對端解決方案更強大,因為您不再需要維護負載平衡器資源。
- 排除負載平衡器探查可將容錯移轉持續時間降至最低。
- DNN 可透過 Azure VM 上的 SQL Server,簡化容錯移轉叢集執行個體或可用性群組接聽程式的佈建和管理。
請考慮下列限制:
- 用戶端驅動程式必須支援
MultiSubnetFailover=True參數。 - 從 Windows Server 2016 和更新版本的 SQL Server 2016 SP3、SQL Server 2017 CU25 和 SQL Server 2019 CU8 開始,已提供 DNN 功能。
若要深入了解,請參閱 Windows Server 容錯移轉叢集概觀。
若要設定連線,請參閱下列文章:
在使用 DNN 時,多數 SQL Server 功能都會以明確的方式與 FCI 和可用性群組搭配運作,但特定功能可能需要特別考量。 若要深入了解,請參閱 FCI 和 DNN 互通性以及 AG 和 DNN 互通性。
提示
在連接字串中設定 MultiSubnetFailover 參數 = true,即使是橫跨單一子網路的 HADR 解決方案也是一樣,以支援未來橫跨多個子網路時不需要更新連接字串。
活動訊號和閾值
將叢集的活動訊號和閾值設定變更為寬鬆設定。 預設的活動訊號和閾值叢集設定是專為高度調整的內部部署網路所設計,不考慮在雲端環境中增加延遲的可能性。 活動訊號網路是以 UDP 3343 進行維護,在傳統上,其可靠性遠低於 TCP,而且更容易出現對話不完整的情況。
因此,針對 Azure VM 高可用性解決方案上的 SQL Server 執行叢集節點時,請將叢集設定變更為較寬鬆的監視狀態,以避免因為網路延遲或失敗、Azure 維護或叫用資源瓶頸的可能性增加而發生暫時性失敗。
延遲和閾值設定對於健康情況偵測總計都具有累計效果。 例如,將 CrossSubnetDelay 設定為每 2 秒傳送一次活動訊號,並在進行復原之前,將 CrossSubnetThreshold 設定為 10 個遺漏的活動訊號,表示叢集在執行復原動作之前,可以擁有 20 秒的網路容錯總計。 一般情況下,您會繼續傳送頻繁的活動訊號,但最好是具有較大的閾值。
為了確保在合法中斷期間復原,並為暫時性問題提供更大的容錯,請將您的延遲和閾值設定放寬到下表中詳述的建議值:
| 設定 | Windows Server 2012 或更新版本 | Windows Server 2008 R2 |
|---|---|---|
| SameSubnetDelay | 1 秒 | 2 秒 |
| SameSubnetThreshold | 40 個活動訊號 | 10 個活動訊號 (最大) |
| CrossSubnetDelay | 1 秒 | 2 秒 |
| CrossSubnetThreshold | 40 個活動訊號 | 20 個活動訊號 (最大) |
使用 PowerShell 來變更您的叢集參數:
(get-cluster).SameSubnetThreshold = 40
(get-cluster).CrossSubnetThreshold = 40
使用 PowerShell 來驗證您的變更:
get-cluster | fl *subnet*
請考慮下列事項:
- 這項變更是立即的,不需要重新啟動叢集或任何資源。
- 相同的子網路值不得大於跨子網路值。
- SameSubnetThreshold <= CrossSubnetThreshold
- SameSubnetDelay <= CrossSubnetDelay
根據可容忍的停機時間,以及應該根據應用程式、商務需求和環境在多長時間內發生矯正措施,來選擇寬鬆值。 如果您無法超過預設的 Windows Server 2019 值,則請至少符合這些值 (如果可能的話):
如需參考,下表詳述預設值:
| 設定 | Windows Server 2019 | Windows Server 2016 | Windows Server 2008 - 2012 R2 |
|---|---|---|---|
| SameSubnetDelay | 1 秒 | 1 秒 | 1 秒 |
| SameSubnetThreshold | 20 個活動訊號 | 10 個活動訊號 | 5 個活動訊號 |
| CrossSubnetDelay | 1 秒 | 1 秒 | 1 秒 |
| CrossSubnetThreshold | 20 個活動訊號 | 10 個活動訊號 | 5 個活動訊號 |
若要深入了解,請參閱調整容錯移轉叢集網路閾值。
寬鬆監視
如果依建議調整您的叢集活動訊號和閾值設定的容錯能力不足,而且您仍看到因為暫時性問題而發生容錯移轉,而不是真正的中斷,則您可以將 AG 或 FCI 監視設定地更寬鬆。 在某些情況下,考慮到活動層級,暫時放寬監視一段時間可能是有益的。 例如,當您執行 IO 密集工作負載 (例如資料庫備份、索引維護、DBCC CHECKDB 等) 時,您可能想要放寬監視。活動完成後,請將您的監視設定為較不寬鬆的值。
警告
變更這些設定可能會隱藏潛在問題,而且應該用作暫時性解決方案來降低而非消除失敗的可能性。 仍應調查和解決潛在的問題。
首先,從預設值調高下列參數以進行寬鬆監視,並視需要進行調整:
| 參數 | 預設值 | 寬鬆值 | Description |
|---|---|---|---|
| 健康情況檢查逾時 | 30000 | 60000 | 判斷主要複本或節點的健康情況。 叢集資源 DLL sp_server_diagnostics 傳回結果的間隔等於健康情況檢查逾時閾值的 1/3。 如果 sp_server_diagnostics 變慢或未傳回資訊,資源 DLL 會先等候健康情況檢查逾時閾值的完整間隔,然後再判斷資源是否沒有回應,並起始自動容錯移轉 (如果已設定這麼做)。 |
| 失敗狀況層級 | 3 | 2 | 觸發自動容錯移轉的條件。 失敗狀況層級共五層,範圍從最低限制 (第一層級) 到最高限制 (第五層級) |
使用 Transact-SQL (T-SQL) 以針對 AG 和 FCI 修改健康情況檢查和失敗情況。
對於可用性群組:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 2);
對於容錯移轉叢集執行個體:
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY HealthCheckTimeout = 60000;
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY FailureConditionLevel = 2;
對於「可用性群組」,請從下列建議參數開始,並視需要調整:
| 參數 | 預設值 | 寬鬆值 | Description |
|---|---|---|---|
| 租用逾時 | 20000 | 40000 | 防止核心分裂。 |
| 工作階段逾時 | 10000 | 20000 | 檢查複本之間的通訊問題。 工作階段逾時期間是複本屬性,可控制可用性複本將連線視為失敗之前等候已連線複本發出 Ping 回應的時間長度 (以秒為單位)。 根據預設,複本會等候 Ping 回應的時間為 10 秒。 這個複本屬性僅適用於可用性群組之給定次要複本與主要複本間的連線。 |
| 指定期間內的失敗次數上限 | 2 | 6 | 用來避免在多個節點失敗內有無限的叢集資源移動。 值過低可能會導致可用性群組處於失敗狀態。 增加值以防止效能問題短暫中斷,因為值過低可能會導致 AG 處於失敗狀態。 |
進行任何變更之前,請考慮下列事項:
- 請不要將任何逾時值降低到比其預設值更低。
- 使用此方程式來計算最大的租用逾時值:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay)。
從 40 秒開始。 如果您要使用先前建議的寬鬆SameSubnetThreshold和SameSubnetDelay值,則請不要超過 80 秒的租用逾時值。 - 若為同步認可複本,將工作階段逾時變更為較高的值,可能會增加 HADR_sync_commit 等候。
租用逾時
使用 [容錯移轉叢集管理員],以修改可用性群組的 [租用逾時] 設定。 如需詳細步驟,請參閱 SQL Server 可用性群組租用健康情況檢查文件。
工作階段逾時
使用 Transact-SQL (T-SQL) 以修改可用性群組的「工作階段逾時」:
ALTER AVAILABILITY GROUP AG1
MODIFY REPLICA ON 'INSTANCE01' WITH (SESSION_TIMEOUT = 20);
指定期間內的失敗次數上限
使用 [容錯移轉叢集管理員] 來修改 [指定期間內的失敗次數上限] 值:
- 在導覽窗格中,選取 [角色]。
- 在 [角色] 下,以滑鼠右鍵按一下叢集資源,並選擇 [屬性]。
- 選取 [容錯移轉] 索引標籤,並視需要增加 [指定期間內的失敗次數上限] 值。
資源限制
VM 或磁碟限制可能會導致資源瓶頸,進而影響叢集的健康情況,並妨礙健康情況檢查。 如果您在使用資源限制時遇到問題,請考慮下列事項:
- 使用 Azure 入口網站中的 I/O 分析 (預覽版) 來識別可能導致容錯移轉的磁碟效能問題。
- 確定您的作業系統、驅動程式和 SQL Server 都是最新組建。
- 最佳化 Azure VM 環境上的 SQL Server,如 Azure 虛擬機器上 SQL Server 的效能指導方針所述
- 使用
- 在不超過資源限制的情況下,減少或散佈工作負載以降低使用率
- 如果有任何機會,請調整 SQL Server 工作負載,例如
- 新增/最佳化索引
- 視需要更新統計資料,並在可能的情況下使用完整掃描
- 使用資源管理員這類功能 (從 SQL Server 2014 開始,僅限企業版) 以限制特定工作負載期間的資源使用率,例如備份或索引維護。
- 移至具有較高限制的 VM 或磁碟,以符合或超過您工作負載的需求。
網路
盡可能將 SQL Server VM 部署至多個子網路,以避免依賴 Azure Load Balancer 或分散式網路名稱 (DNN),將流量路由傳送至 HADR 解決方案。
使用每一伺服器 (叢集節點) 單一 NIC。 Azure 網路有實體備援,因此 Azure 虛擬機器客體叢集上不需要額外的 NIC。 叢集驗證報告會警告您節點只能在單一網路上觸達。 您可在 Azure 虛擬機器客體容錯移轉叢集上忽略此警告。
特定 VM 的頻寬限制會跨 NIC 共用,而新增額外的 NIC 並不會改善 Azure VM 上 SQL Server 的可用性群組效能。 因此,不需要新增第二個 NIC。
Azure 中不符合 RFC 規範的 DHCP 服務可能會造成建立特定容錯移轉叢集設定失敗。 發生這種失敗的原因是,叢集網路名稱已獲指派重複的 IP 位址,例如,與其中一個叢集節點相同的 IP 位址。 這是您使用可用性群組 (取決於 Windows 容錯移轉叢集功能) 時會發生的問題。
當雙節點叢集建立且上線時,請考慮以下案例:
- 當叢集上線後,NODE1 會要求一個叢集網路名稱的動態指派 IP 位址。
- 除了 NODE1 自己的 IP 位址以外,DHCP 服務不會提供任何 IP 位址,因為 DHCP 服務會辨識來自 NODE1 本身的要求。
- Windows 偵測到將重複的位址指派給 NODE1 和容錯移轉叢集網路名稱,而且預設叢集群組無法上線。
- 預設叢集群組移動至 NODE2。 NODE2 會將 NODE1 的 IP 位址視為叢集 IP 位址,並讓預設叢集群組上線。
- 當 NODE2 嘗試與 NODE1 建立連線時,在 NODE1 導向的封包絕不會離開 NODE2,因為它將 NODE1 的 IP 位址解析至其本身。 NODE2 無法與 NODE1 建立連線,因此失去仲裁並關閉叢集。
- NODE1 會將封包傳送至 NODE2,但 NODE2 無法回覆。 NODE1 會失去仲裁並關閉叢集。
您可以將未使用的靜態 IP 位址指派給叢集網路名稱,以讓叢集網路名稱上線,並將 IP 位址新增至 Azure Load Balancer,此來避免此情況。
如果 SQL Server 資料庫引擎、Always On 可用性群組接聽程式或容錯移轉叢集執行個體健康狀態探查、資料庫鏡像端點、叢集核心 IP 資源,或任何其他 SQL 資源設定為使用 49,152 與 65,536 之間的連接埠 (TCP/IP 的預設動態連接埠範圍),則請新增每個連接埠的排除。 這樣做會讓其他系統程序無法動態指派相同的連接埠。 下列範例會建立連接埠 59999 的排除:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
沒有連接埠正在使用中時,請務必設定排除連接埠,否則命令將會失敗,並出現類似「程序無法存取檔案,因為另一個程序正在使用」等訊息。
若要確認已正確設定排除項目,請使用下列命令:netsh int ipv4 show excludedportrange tcp。
為可用性群組角色 IP 探查埠設定此排除項目,應防止事件識別碼:1069 狀態為 10048 的事件。 您可以在 Windows 容錯移轉叢集事件中看到此事件,並會有下列訊息:
Cluster resource '<IP name in AG role>' of type 'IP Address' in cluster role '<AG Name>' failed.
An Event ID: 1069 with status 10048 can be identified from cluster logs with events like:
Resource IP Address 10.0.1.0 called SetResourceStatusEx: checkpoint 5. Old state OnlinePending, new state OnlinePending, AppSpErrorCode 0, Flags 0, nores=false
IP Address <IP Address 10.0.1.0>: IpaOnlineThread: **Listening on probe port 59999** failed with status **10048**
Status [**10048**](/windows/win32/winsock/windows-sockets-error-codes-2) refers to: **This error occurs** if an application attempts to bind a socket to an **IP address/port that has already been used** for an existing socket.
這可能是內部進程採用同樣定義為探查埠的連接埠所造成。 請記住,探查埠是用來從 Azure Load Balancer 檢查後端集區執行個體的狀態。
如果健康狀態探查無法從後端執行個體取得回應,則直到健康狀態探查再次成功之前,不會將任何新的連線傳送至該後端執行個體。
已知問題
請檢閱解決方式,以了解一些常見的已知問題和錯誤。
資源爭用 (特別是 IO) 造成容錯移轉
耗盡 VM 的 I/O 或 CPU 容量可能會導致可用性群組發生容錯移轉。 識別在容錯移轉之前發生的競爭,這是識別造成自動容錯移轉原因的最可靠方式。
使用 I/O 分析
使用 Azure 入口網站中的 I/O 分析 (預覽版) 來識別可能導致容錯移轉的磁碟效能問題。
使用 VM 儲存體 IO 計量進行監視
監視 Azure 虛擬機器以查看儲存體 IO 使用率計量,並了解 VM 或磁碟層級延遲。
請遵循下列步驟來檢閱 Azure VM 整體 IO 耗盡事件:
選取 [監視] 底下的 [計量],以開啟 [計量] 頁面。
選取 [本地時間] 以指定您感興趣的時間範圍和時區 (VM 本地時間或 UTC/GMT)。
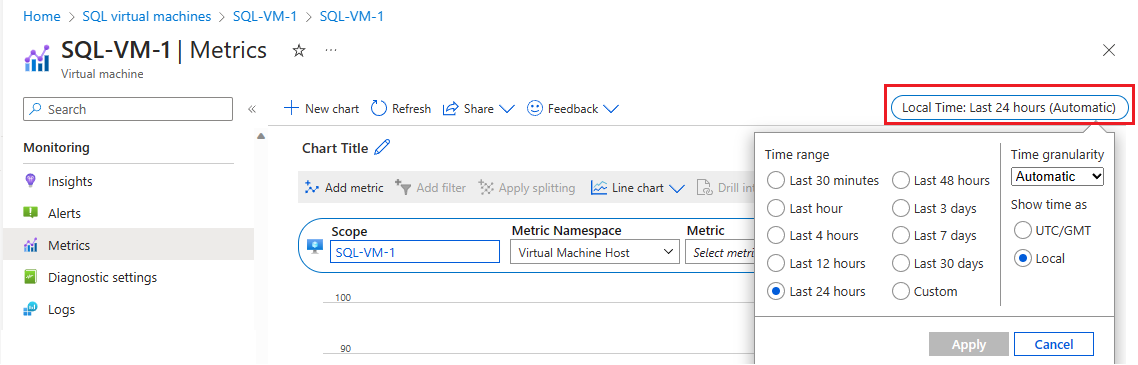
選取 [新增計量] 以新增下列兩個計量,並查看圖表:
- 已使用的 VM 快取頻寬百分比
- 已使用的 VM 未快取頻寬百分比
![Azure 入口網站中 [計量] 頁面的螢幕擷取畫面。](media/hadr-cluster-best-practices/hadr-metrics-cached-uncached.png?view=azuresql)
Azure VM HostEvents 會導致容錯移轉
Azure VM HostEvent 可能會導致可用性群組發生容錯移轉。 如果您認為 Azure VM HostEvent 造成容錯移轉,您可以檢查 Azure 監視器活動記錄和 Azure VM 資源健康狀態概觀。
Azure 監視器活動記錄是 Azure 中的平台記錄,可提供訂閱層級事件的深入解析。 活動記錄包含資訊,例如修改資源或啟動虛擬機器時。 您可以在 Azure 入口網站中檢視活動記錄,或使用 PowerShell 和 Azure CLI 來擷取項目。
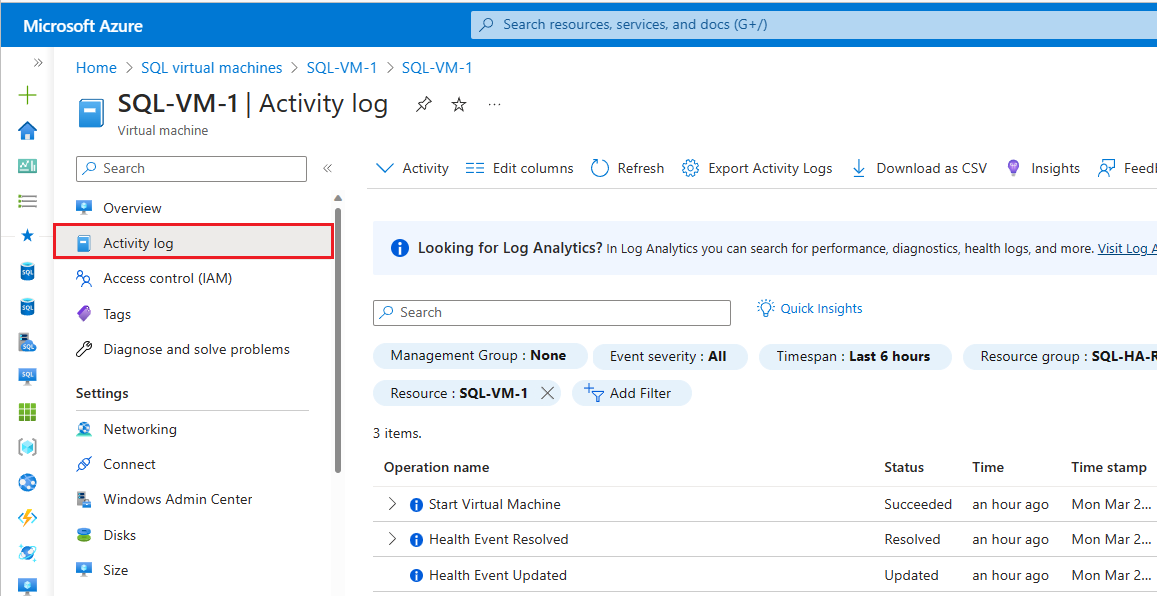
若要檢查 Azure 監視器活動記錄,請遵循下列步驟:
瀏覽至您在 Azure 入口網站的虛擬機器
在 [虛擬機器] 窗格上選取 [活動記錄]
選取 [時間範圍],然後在可用性群組發生容錯移轉時選擇時間範圍。 選取 [套用]。
如果 Azure 有關於平台起始無法使用根本原因的進一步資訊,該資訊可能會在初始無法使用之後張貼在 Azure VM - 資源健康狀態概觀頁面中最多 72 個小時。 此資訊目前僅適用於虛擬機器。
- 瀏覽至您在 Azure 入口網站的虛擬機器
- 選取 [健康情況] 窗格下的 [資源健康狀態]。
![Azure 入口網站中 [資源健康狀態] 頁面的螢幕擷取畫面。](media/hadr-cluster-best-practices/resource-health.png?view=azuresql)
您也可以根據此頁面的健康狀態事件來設定警示。
從成員資格移除的叢集節點
如果 Windows 叢集活動訊號和閾值設定對您的環境而言太過積極,則您可能會經常在系統事件記錄中看見下列訊息。
Error 1135
Cluster node 'Node1' was removed from the active failover cluster membership.
The Cluster service on this node may have stopped. This could also be due to the node having
lost communication with other active nodes in the failover cluster. Run the Validate a
Configuration Wizard to check your network configuration. If the condition persists, check
for hardware or software errors related to the network adapters on this node. Also check for
failures in any other network components to which the node is connected such as hubs, switches, or bridges.
如需詳細資訊,請檢閱針對事件識別碼 1135 的叢集問題進行疑難排解。
租用已到期/租用不再有效
如果監視對您的環境而言太過積極,則您可能會發現頻繁的可用性群組或 FCI 重新啟動、失敗或容錯移轉。 此外,對於可用性群組,您可能會在 SQL Server 錯誤記錄中看到下列訊息:
Error 19407: The lease between availability group 'PRODAG' and the Windows Server Failover Cluster has expired.
A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster.
To determine whether the availability group is failing over correctly, check the corresponding availability group
resource in the Windows Server Failover Cluster
Error 19419: The renewal of the lease between availability group '%.*ls' and the Windows Server Failover Cluster
failed because the existing lease is no longer valid.
連接逾時
如果工作階段逾時對可用性群組環境而言太過積極,則您可能會經常看見下列訊息:
Error 35201: A connection timeout has occurred while attempting to establish a connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or firewall issue exists,
or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
Error 35206
A connection timeout has occurred on a previously established connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or a firewall issue
exists, or the availability replica has transitioned to the resolving role.
未容錯移轉群組
如果 [指定期間內的失敗次數上限] 值過低,而您因為暫時性問題而遇到間歇性失敗,您的可用性群組可能因為失敗狀態而結束。 增加此值,以容忍更多暫時性失敗。
Not failing over group <Resource name>, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2.
事件 1196 - 網路名稱資源無法註冊相關聯的 DNS 名稱
- 請檢查每個叢集節點的 NIC 設定,以確定沒有任何外部 DNS 記錄存在
- 請確定您的叢集 A 記錄存在於您的內部 DNS 伺服器上。 如果沒有,請在 DNS 伺服器中為叢集建立新的 A 記錄手動存取控制物件,然後勾選 [允許任何已驗證的使用者更新具有相同擁有者名稱的 DNS 記錄]。
- 將資源「叢集名稱」與 IP 資源離線,並加以修正。
事件 157 - 磁碟已意外移除。
如果儲存空間屬性 AutomaticClusteringEnabled 在 AG 環境設為 True,就會發生這種情況。 將其變更為 False。 此外,執行具有儲存體選項的驗證報告,可能會觸發磁碟重設或意外移除事件。 儲存系統節流也會觸發「磁碟意外移除」事件。
事件 1206 - 叢集網路名稱資源無法上線。
無法更新網域中與資源關聯的電腦物件。 請確定您在網域上擁有適當的權限
Windows 叢集錯誤
如果您未開啟用來通訊的叢集服務連接埠,可能會在設定 Windows 容錯移轉叢集或連線時遇到問題。
如果使用 Windows Server 2019 而且沒有看到 Windows 叢集 IP,則表示您已設定分散式網路名稱,只有 SQL Server 2019 才支援此功能。 如果您有舊版的 SQL Server,可以使用網路名稱移除並重新建立叢集。
在這裡檢閱其他 Windows 容錯移轉叢集事件錯誤及其解決方案
後續步驟
若要深入了解,請參閱: