了解 Azure NetApp Files 中的磁碟區語言
Azure NetApp Files 磁碟區上的磁碟區語言 (類似於用戶端作業系統的系統地區設定),可在使用 NFS 和 SMB 通訊協定時控制支援的語言和字元集。 Azure NetApp Files 使用 C.UTF-8 的預設磁碟區語言,提供符合 POSIX 規範的 UTF-8 編碼字元集。 C.UTF-8 語言原生支援大小為 0 到 3 個位元組的字元,其中包括基本多語平面 (BMP) 中大多數的語言,包括日文、德文,以及希伯來文和希伯來文和斯拉夫文的大部分字元。 如需 BMP 的詳細資訊,請參閱 Unicode。
BMP 以外的字元有時會超過 Azure NetApp Files 所支援的 3 個位元組大小。 因此,這些字元需要使用代理字組邏輯,將多個字元位元組的集合組合成新的字元。 例如,Emoji 符號屬於此類別,且在 Azure NetApp Files 未強制使用 UTF-8 的情況下仍受支援,例如使用 UTF-16 編碼的 Windows 用戶端或未強制使用 UTF-8 的 NFSv3。 NFSv4.x 會強制使用 UTF-8,這表示使用 NFSv4.x 時,代理字組字元不會正確顯示。
非標準編碼,例如 Shift-JIS 和較不常見的 CJK 字元,在 Azure NetApp Files 強制使用 UTF-8 時也不會正確顯示。
提示
您應該使用 UTF-8 傳送和接收文字,以避免無法正確轉譯字元的情況,這可能會導致檔案建立/重新命名或複製錯誤的案例。
目前無法在 Azure NetApp Files 中修改磁碟區語言設定。 如需詳細資訊,請參閱使用特殊字元集的通訊協定行為。
如需最佳做法,請參閱字元集最佳做法。
Azure NetApp Files NFS 和 SMB 磁碟區中的字元編碼
在 Azure NetApp Files 檔案共用環境中,檔案和資料夾名稱會以終端使用者讀取和解譯的一系列字元來表示。 這些字元的顯示方式取決於用戶端如何傳送和接收這些字元的編碼方式。 例如,如果用戶端在存取 Azure NetApp Files 磁碟區時,將舊版 美國標準資訊交換標準代碼 (ASCII) 編碼傳送至 Azure NetApp Files 磁碟區,則只會顯示 ASCII 格式支援的字元。
例如,資料的日文字元為「資」。 此字元無法在 ASCII 中表示,因此使用 ASCII 編碼的用戶端會顯示“?”, 而非「資」。
ASCII 僅支援 95 個可列印字元,主要是英文中使用的字元。 每個字元都會使用 1 個位元組,這會納入 Azure NetApp Files 磁碟區上的總檔案路徑長度中。 這會限制資料集的國際化,因為檔名可以包含許多 ASCII 無法辨識的字元,例如日文、斯拉夫文和表情符號。 國際標準 (ISO/IEC 8859) 試圖支援更多的國際字元,但也有其限制。 大部分的新式用戶端會使用某種形式的 Unicode 來傳送和接收字元。
Unicode
由於 ASCII 和 ISO/IEC 8859 編碼的限制,為了讓任何人都可以從其裝置檢視其所屬地區的語言,因此制定了 Unicode 標準。
- 相較於舊式編碼 (例如 ASCII),Unicode 透過增加每個字元允許的位元組數目 (最多 4 個位元組),以及檔案路徑中允許的位元組總數,來支援超過一百萬個字元集。
- Unicode 藉由保留 ASCII 的前 128 個字元,同時確保前 256 個字碼元素與 ISO/IEC 8859 標準相同,來支援回溯相容性。
- 在 Unicode 標準中,字元集會細分成平面。 平面是 65,536 個字碼元素的連續群組。 Unicode 標準共有 17 個平面 (0-16)。 因為 UTF-16 的限制,上限為 17 個。
- 平面 0 是 基本多語平面 (BMP)。 此平面包含多種語言最常使用的字元。
- 截至 Unicode 15.1 版,在 17 個平面中,目前只有 5 個已指派字元集。
- 平面 1-17 被稱為 補充多語平面 (SMP),並包含較少使用的字元集,例如古代書寫系統,如楔形文字和象形文字,以及特殊的中文/日文/韓文 (CJK) 字元。
- 若要了解如何查看字元長度和路徑大小,以及控制傳送至系統的編碼,請參閱將檔案轉換成不同的編碼。
Unicode 使用 Unicode 轉換格式作為其標準,UTF-8 和 UTF-16 是兩個主要格式。
Unicode 平面
Unicode 利用 17 個 65,536 個字元的平面 (256 個字碼元素乘以平面中的 256 個方塊),平面 0 作為基本多語平面 (BMP)。 此平面包含多種語言最常使用的字元。 由於世界的語言和字元集數量龐大,超過 65536 個字元,因此需要更多平面來支援較少使用的字元集。
例如,第一架飛機(補充多語飛機(SMP)包括歷史劇本,如村形和埃及象形,以及一些奧薩奇,沃朗花旗,阿德拉姆,萬喬和托托。 平面 1 也包含一些符號和表情符號字元。
平面 2 是補充表意字元平面 (SIP),包含中文/日文/韓文 (CJK) 統一表意文字。 平面 1 和平面2 中的字元大小通常為 4 個位元組。
例如:
- 平面 1 中的「大眼睛笑臉」表情符號 "😃" 大小為 4 個位元組。
- 平面 1 中的埃及象形文字 "𓀀" 大小為 4 個位元組。
- 平面 1 中的歐塞奇 (Osage) 字元 "𐒸" 大小為 4 個位元組。
- 平面 2 中的 CJK 字元 "𫝁" 大小為 4 個位元組。
由於這些字元的大小都是 >3 個位元組,因此需要使用代理字組才能正常運作。 Azure NetApp Files 原生支援代理字組,但字元的顯示會因使用的通訊協定、用戶端的地區設定和遠端用戶端存取應用程式的設定而有所不同。
UTF-8
UTF-8 使用 8 位元編碼,最多可以有 1,112,064 個字碼元素 (或字元)。 UTF-8 是 Linux 作業系統中所有語言的標準編碼方式。 由於 UTF-8 使用 8 位元編碼,因此可能的不帶正負號整數上限為 255 (2^8 – 1),這也是該編碼的最大檔名長度。 網際網路上超過 98% 的頁面使用 UTF-8,因此是迄今為止最廣泛採用的編碼標準。 Web 超文字應用程式技術工作群組 (WHATWG) 認為 UTF-8 是「所有 [文字] 的強制編碼方式」,且基於安全考量,瀏覽器應用程式不應使用 UTF-16。
UTF-8 格式的字元各使用 1 到 4 個位元組,但幾乎所有語言中的所有字元都會使用 1 到 3 個位元組。 例如:
- 拉丁字母 “A” 使用 1 個位元組。 (128 個保留的 ASCII 字元之一)
- 著作權符號 “©” 使用 2 個位元組。
- 字元 “ä” 使用 2 個位元組。 (“a” 使用 1 個位元組 + 母音變化使用 1 個位元組)
- 資料 (資) 的日文漢字符號使用 3 個位元組。
- 笑臉表情符號 (😃) 使用 4 個位元組。
語言地區設定可以使用電腦標準 UTF-8 (C.UTF-8) 或更為特定的區域格式,例如en_US.UTF-8、ja.UTF-8 等。使用 Linux 用戶端存取 Azure NetApp Files 時,應盡可能使用 UTF-8 編碼。 至於 OS X,macOS 用戶端也會使用 UTF-8 作為其預設編碼,不應該調整。
Windows 用戶端則使用 UTF-16。 在大部分情況下,此設定應保留為 OS 地區設定的預設值,但較新的用戶端會透過核取方塊提供 UTF-8 字元的測試支援。 您也可以調整 Windows 中的終端用戶端,視需要在 PowerShell 或 CMD 中使用 UTF-8。 如需詳細資訊,請參閱使用特殊字元集的雙重通訊協定行為。
UTF-16
UTF-16 使用 16 位元編碼,而且能夠編碼 Unicode 的所有 1,112,064 個字碼元素。 UTF-16 的編碼方式可以使用一或兩個 16 位元字碼單位,每個是 2 個位元組的大小。 UTF-16 中的所有字元都使用 2 或 4 個位元組的大小。 UTF-16 中使用 4 個位元組的字元會利用代理字組,結合兩個不同的 2 位元組字元來建立新的字元。 這些補充字元落在標準 BMP 平面之外,並屬於其他多語平面之一。
UTF-16 用於 Windows 作業系統以及 API、JAVA 和 JavaScript。 因為這不支援與 ASCII 格式的回溯相容性,因此在網路上從未受到歡迎。 UTF-16 僅佔網際網路上所有頁面的 0.002% 左右。 Web 超文字應用程式技術工作群組 (WHATWG) 認為 UTF-8 是「所有文字的強制編碼方式」,且基於瀏覽器的安全考量,建議應用程式不要使用 UTF-16。
Azure NetApp Files 支援大部分的 UTF-16 字元,包括代理字組。 若字元未受支援,Windows 用戶端會回報「您指定的檔名無效或太長」的錯誤。
遠端用戶端的字元集處理
您可以設定遠端連線至掛接 Azure NetApp Files 磁碟區的用戶端 (例如 Linux 用戶端的 SSH 連線,以存取 NFS 掛接),來傳送和接收特定的磁碟區語言編碼。 透過遠端連線公用程式傳送至用戶端的語言編碼可控制如何建立和檢視字元集。 因此,使用與另一個遠端連線不同語言編碼的遠端連線(例如兩個不同的 PuTTY 視窗)在 Azure NetApp Files 磁碟區中列出檔案和資料夾名稱時,可能會顯示字元的不同結果。 在大部分情況下,這不會產生差異 (例如拉丁/英文字元),但在特殊字元的情況下,例如 Emoji,結果可能會有所不同。
例如,在遠端連線中使用 UTF-8 編碼,會顯示 Azure NetApp Files 磁碟區中字元的可預測結果,因為 C.UTF-8 是磁碟區語言。 「資料」 (資) 的日文字元會根據終端機所傳送的編碼方式而有所不同。
PuTTY 中的字元編碼
PuTTY 視窗使用 UTF-8 時 (在 Windows 的翻譯設定中找到),Azure NetApp Files 中掛接的 NFSv3 磁碟區會正確地顯示:

如果 PuTTY 視窗使用不同的編碼方式,例如 ISO-8859-1:1998 (Latin-1、西歐),即使檔名相同,相同的字元仍會以不同的方式顯示。

PuTTY 預設不包含 CJK 編碼。 有修補程式可用來將這些語言集新增至 PuTTY。
Bastion 中的字元編碼
Microsoft Azure 建議使用 Bastion 對 Azure 中的虛擬機器 (VM) 進行遠端連線。 使用 Bastion 時,傳送和接收的語言編碼不會在設定中公開,但會利用標準 UTF-8 編碼。 因此,使用 UTF-8 在 PuTTY 中看到的大部分字元集也應該顯示在 Bastion 中,前提是所使用的通訊協定支援字元集。

提示
您可以使用其他 SSH 終端機,例如 TeraTerm。 TeraTerm 預設提供更廣泛的支援字元集,包括 CJK 編碼和非標準編碼,例如 Shift-JIS。
使用特殊字元集的通訊協定行為
Azure NetApp Files 磁碟區使用 UTF-8 編碼,且原生支援不超過 3 個位元組的字元。 ASCII 和 UTF-8 字元集中的所有字元都會正確顯示,因為這些字元落在 1 到 3 個位元組的範圍中。 例如:
- 拉丁字母字元 “A” 使用 1 個位元組 (這是 128 個保留的 ASCII 字元之一)。
- 著作權符號 © 使用 2 個位元組。
- 字元 “ä” 會使用 2 個位元組 (“a” 使用 1 個位元組,以及母音變化使用 1 個位元組)。
- 資料 (資) 的日文漢字符號使用 3 個位元組。
Azure NetApp Files 也透過代理字組邏輯支援超過 3 個位元組的字元 (例如 Emoji),前提是用戶端編碼和通訊協定版本有所支援。 如需通訊協定行為的詳細資訊,請參閱:
SMB 行為
在 SMB 磁碟區中,Azure NetApp Files 會針對任何可從 SMB 用戶端存取的檔案或目錄建立和維護兩個名稱:原始長名稱和 8.3 格式的名稱。
使用 Azure NetApp Files 在 SMB 中的檔名
若檔案或目錄名稱超過允許的字元位元組或使用不支援的字元,Azure NetApp Files 會產生 8.3 格式的名稱,如下所示:
- 其會截斷原始檔案或目錄名稱。
- 將檔案或目錄名稱截斷後,若為重複名稱,系統會將波狀符號 (~) 和數字 (1-5) 附加其後方。 如果有超過五個檔案使用重複名稱,Azure NetApp Files 會建立與原始名稱無關的唯一名稱。 處理檔案時,Azure NetApp Files 會將副檔名截斷為三個字元。
例如,如果 NFS 用戶端建立名為 specifications.html 的檔案,Azure NetApp Files 會以 8.3 格式建立檔名 specif~1.htm。 如果此名稱已存在,Azure NetApp Files 會在檔名結尾使用不同的數字。 例如,如果 NFS 用戶端接著建立另一個名為 specifications\_new.html 的檔案,則 specifications\_new.html 的 8.3 格式為 specif~2.htm。
使用 Azure NetApp Files 在 SMB 中的特殊字元
搭配 Azure NetApp Files 磁碟區使用 SMB 時,由於代理字組支援,允許在檔案和資料夾名稱中使用的超過 3 個位元組的字元 (包括表情符號)。 在使用預設的 UTF-16 編碼以英文設定從Windows 用戶端建立的資料夾中,對於 BMP以外的字元,Windows 檔案總管看到的情況如下。
注意
Windows 檔案總管中的預設字型是 Segoe UI。 字型變更可能會影響用戶端上某些字元的顯示方式。

用戶端上的字元顯示方式取決於系統字型以及語言和地區設定。 一般而言,不論編碼是否為 UTF-8 或UTF-16,所有通訊協定都支援屬於 BMP 的字元。
使用 CMD 或 PowerShell 時,字元集顯示取決於字型設定。 這些公用程式的預設字型選擇有限。 CMD 使用 Consolas 做為預設字型。
檔案名稱的顯示可能會因使用的字型而有所不同,因為某些控制台並未原生支援 Segoe UI 或其他能夠正確轉譯特殊字元的字型。
在 Windows 用戶端上,可以使用 PowerShell ISE 來解決這個問題,此方式提供更健全的字型支援。 例如,將 PowerShell ISE 設定為 Segoe UI 時,會正確顯示具有支援字元的檔案名稱。

不過,PowerShell ISE 是專為指令碼設計,而不是用於管理共用。 較新的 Windows 版本提供 Windows 終端機,可讓您控制字型和編碼值。

如果磁碟區已啟用雙通訊協定 (NFS 和 SMB),您可能會觀察到不同的行為。 如需詳細資訊,請參閱使用特殊字元集的雙重通訊協定行為。
NFS 行為
NFS 顯示特殊字元的方式取決於所使用的 NFS 版本、用戶端的地區設定、安裝的字型,以及使用中遠端連線用戶端的設定。 例如,使用 Bastion 存取 Ubuntu 用戶端句柄字元的方式,與設定為相同 VM 上不同地區設定的 PuTTY 用戶端不同。 以下的 NFS 範例採用 Ubuntu VM 的這些地區設定:
~$ locale
LANG=C.UTF-8
LANGUAGE=
LC\_CTYPE="C.UTF-8"
LC\_NUMERIC="C.UTF-8"
LC\_TIME="C.UTF-8"
LC\_COLLATE="C.UTF-8"
LC\_MONETARY="C.UTF-8"
LC\_MESSAGES="C.UTF-8"
LC\_PAPER="C.UTF-8"
LC\_NAME="C.UTF-8"
LC\_ADDRESS="C.UTF-8"
LC\_TELEPHONE="C.UTF-8"
LC\_MEASUREMENT="C.UTF-8"
LC\_IDENTIFICATION="C.UTF-8"
LC\_ALL=
NFSv3 行為
NFSv3 不會對檔案和資料夾強制使用 UTF 編碼。 在大部分情況下,特殊字元集應該沒有任何問題。 不過,所使用的連線用戶端可能會影響傳送和接收字元的方式。 例如,針對 Azure 連線用戶端 Bastion 中的資料夾名稱使用 BMP 以外的 Unicode 字元,可能會因用戶端編碼的運作方式,而導致一些非預期的行為。
在下列螢幕擷取畫面中,Bastion 無法在透過NFSv3 為目錄命名時,從瀏覽器外部複製並貼上值至 CLI 提示字元。 嘗試複製並貼上 NFSv3Bastion𓀀𫝁😃𐒸 的值時,特殊字元會在輸入中顯示為引號。

允許在 NFSv3 上使用複製貼上命令,但字元會建立為其數值,因而影響其顯示:
NFSv3Bastion'$'\262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355
此顯示是因為 Bastion 在複製和貼上時,用來傳送文字值的編碼所導致。
使用 PuTTY 在 NFSv3 上建立具有相同字元的資料夾時,該資料夾名稱與 Bastion 中用來建立資料夾的名稱不同。 表情符號會如預期般顯示 (由於已安裝的字型和地區設定),但其他字元則不會顯示,例如歐塞奇 (Osage) 中的 "𐒸"。

從 PuTTY 視窗中,字元會顯示正確:

NFSv4.x 行為
NFSv4.x 會根據 RFC-8881 國際化規格,在檔案和資料夾名稱中強制使用 UTF-8 編碼。
因此,如果以非 UTF-8 編碼方式傳送特殊字元,NFSv4.x 可能不會允許此值。
在某些情況下,可以使用基本多語平面 (BMP) 以外的字元來允許命令,但在建立之後可能不會顯示值。
例如,以資料夾名稱發出 mkdir,包括字元 "𓀀𫝁😃𐒸" (補充多語平面 (SMP) 和補充表意字元平面 (SIP) 中的字元) 似乎在 NFSv4.x 中是成功的。 執行 ls 命令時,將不會顯示資料夾。
root@ubuntu:/NFSv4/NFS$ mkdir "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS$ ls -la
total 8
drwxrwxr-x 3 nobody 4294967294 4096 Jan 10 17:15 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
root@ubuntu:/NFSv4/NFS$
資料夾存在於磁碟區中。 變更為隱藏的目錄名稱可從 PuTTY 用戶端運作,而且可以在該目錄內建立檔案。
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ sudo touch Unicode.txt
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ ls -la
-rw-r--r-- 1 root root 0 Jan 10 17:31 Unicode.txt
來自 PuTTY 的 stat 命令也會確認資料夾存在:
root@ubuntu:/NFSv4/NFS$ stat "NFSv4 Putty 𓀀𫝁😃𐒸"
**File: NFSv4 Putty** **𓀀**** 𫝁 ****😃**** 𐒸**
Size: 4096 Blocks: 8 IO Block: 262144 **directory**
Device: 3ch/60d Inode: 101 Links: 2
Access: (0775/drwxrwxr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-01-10 17:15:44.860775000 +0000
Modify: 2024-01-10 17:31:35.049770000 +0000
Change: 2024-01-10 17:31:35.049770000 +0000
Birth: -
即使已確認資料夾存在,萬用字元命令也沒有作用,因為用戶端在顯示中無法正式「查看」資料夾。
root@ubuntu:/NFSv4/NFS$ cp \* /NFSv3/
cp: can't stat '\*': No such file or directory
NFSv4.1 會在遇到未採用 UTF-8 編碼的字元時,將錯誤傳送給用戶端。
例如,使用 Bastion 嘗試存取我們透過 NFSv4.1 使用 PuTTY 建立的相同目錄時,結果是:
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃�"
-bash: cd: $'NFSv4 Putty \262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355': Invalid argument
The "invalid argument" error message doesn't help diagnose the root cause, but a packet capture shines a light on the problem:
78 1.704856 y.y.y.y x.x.x.x NFS 346 V4 Call (Reply In 79) LOOKUP DH: 0x44caa451/NFSv4 Putty ��������
79 1.705058 x.x.x.x y.y.y.y NFS 166 V4 Reply (Call In 25) OPEN Status: NFS4ERR\_INVAL
RFC-8881 中涵蓋 NFS4ERR_INVAL。
由於可以從 PuTTY 存取資料夾 (因為傳送和接收的編碼正確),因此只要指定了名稱,就可以複製該資料夾。 將該資料夾從 NFSv4.1 Azure NetApp Files 磁碟區複製到 NFSv3 Azure NetApp Files 磁碟區後,資料夾名稱會顯示:
root@ubuntu:/NFSv4/NFS$ cp -r /NFSv4/NFS/"NFSv4 Putty 𓀀𫝁😃𐒸" /NFSv3/NFSv3/
root@ubuntu:/NFSv4/NFS$ ls -la /NFSv3/NFSv3 | grep v4
drwxrwxr-x 2 root root 4096 Jan 10 17:49 NFSv4 Putty 𓀀𫝁😃𐒸
如果嘗試使用 `iconv`` 將檔案轉換成非 UTF-8 格式,例如 Shift-JIS,將會看到相同的NFS4ERR\_INVAL錯誤。
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
如需詳細資訊,請參閱將檔案轉換成不同的編碼。
雙重通訊協定行為
Azure NetApp Files 允許 NFS 和 SMB 透過雙重通訊協定存取來存取磁碟區。 由於 NFS (UTF-8) 和 SMB (UTF-16) 所使用的語言編碼差異很大,字元集、檔案和資料夾名稱,以及路徑長度在通訊協定之間可能會有非常不同的行為。
從 SMB 檢視 NFS 建立的檔案和資料夾
若將 Azure NetApp Files 用於雙重通訊協定存取 (SMB 和 NFS),UTF-16 不支援的字元集可能會用於透過 NFS 使用 UTF-8 所建立的檔案名稱。 在這些情況下,若 SMB 存取含有不支援字元的檔案,會使用 8.3 簡短檔案名稱慣例在 SMB 中截斷名稱。
NFSv3 建立的檔案和 SMB 的字元集行為
NFSv3 不會強制使用 UTF-8 編碼。 在使用 NFSv3 時,使用非標準語言編碼的字元 (例如 Shift-JIS) 適用於 Azure NetApp Files。
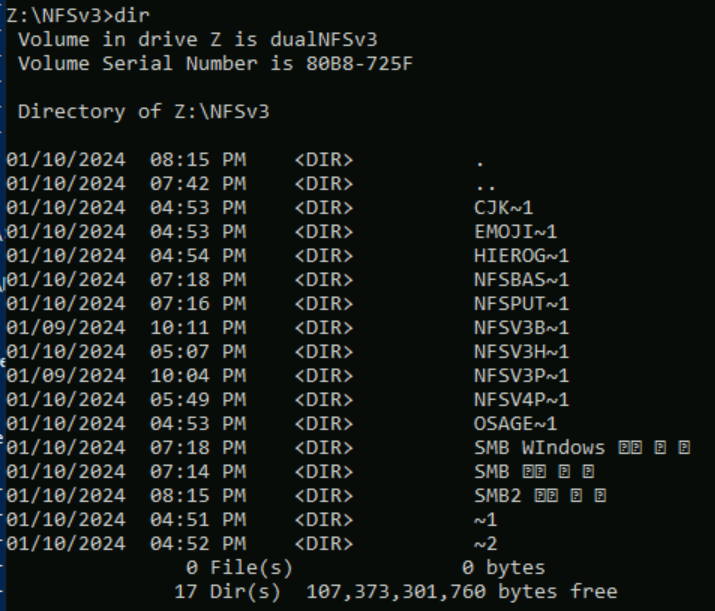
在下列範例中,使用 Unicode 中不同平面不同字元集的一系列資料夾名稱,是使用 NFSv3 在 Azure NetApp Files 磁碟區中建立的。 從 NFSv3 檢視時,這些名稱會正確顯示。
root@ubuntu:/NFSv3/dual$ ls -la
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-English
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-Japanese-German-資ä
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-copyright-©
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-CJK-plane2-𫝁
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-emoji-plane1-😃
從 Windows SMB 中,含有 BMP 所屬字元的資料夾會正確顯示,但由於 UTF-8/UTF-16 轉換與這些字元不相容,該平面以外的字元會以 8.3 名稱格式顯示。
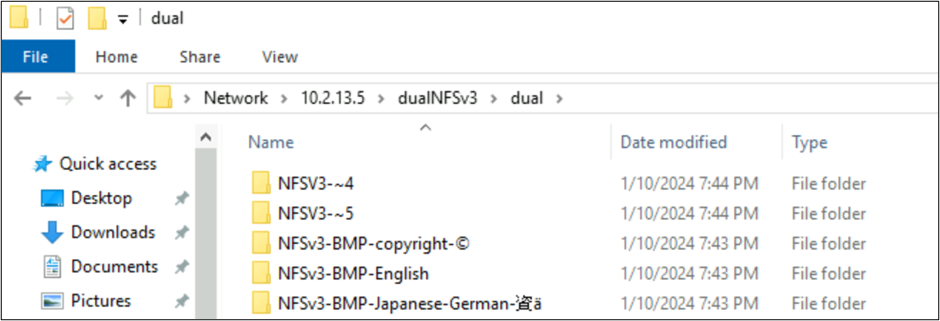
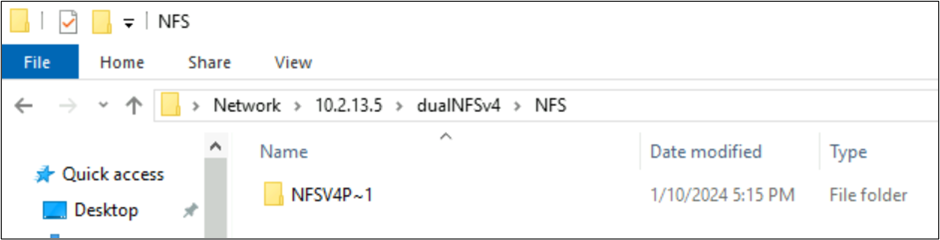
NFSv4.1 建立的檔案和 SMB 的字元集行為
在上述範例中,名為 NFSv4 Putty 𓀀𫝁😃𐒸 的資料夾是在 Azure NetApp Files 磁碟區上透過 NFSv4.1 建立,但無法使用 NFSv4.1 來檢視。 不過,您可以使用 SMB 來查看。 由於從 NFS 用戶端建立的不支援字元集,以及 UTF-8/UTF-16 轉換對不同 Unicode 平面中的字元是不相容的,所以在 SMB 中,名稱會截斷為支援的 8.3 格式。
若資料夾名稱使用 BMP 中採用的標準 UTF-8 字元,SMB 會正確轉譯名稱。
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-English
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-資ä
root@ubuntu:/NFSv4/NFS$ ls -la
total 16
drwxrwxr-x 5 nobody 4294967294 4096 Jan 10 18:26 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
**drwxrwxr-x 2 root root 4096 Jan 10 18:21 NFS-created-English**
**drwxrwxr-x 2 root root 4096 Jan 10 18:26 NFS-created-**** 資 ****ä**
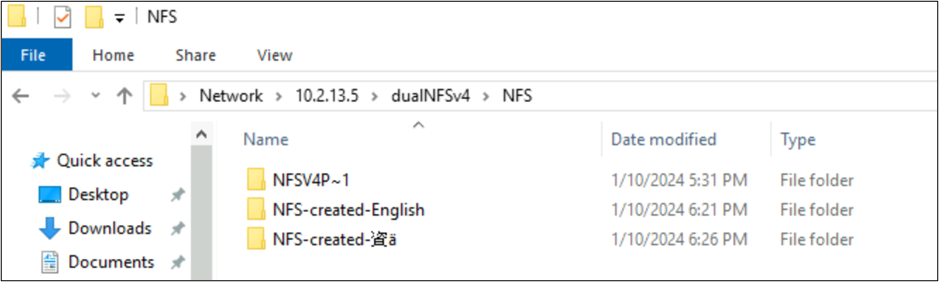
NFS 上 SMB 建立的檔案和資料夾
Windows 用戶端是用來存取 SMB 共用的主要用戶端類型。 這些用戶端預設為 UTF-16 編碼。 在區域設定中啟用 UTF-8 編碼字元,就可以在 Windows 中支援某些 UTF-8 編碼字元:
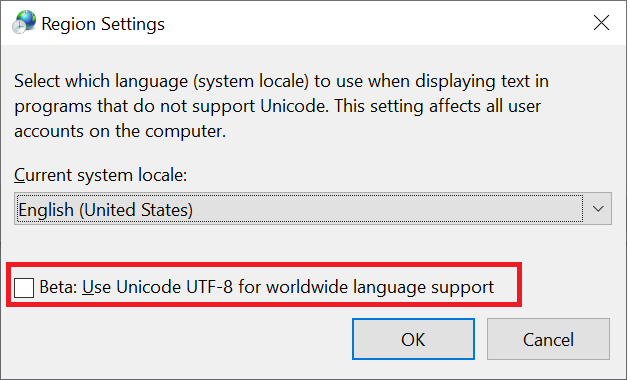
在 Azure NetApp Files 中的 SMB 共用上建立檔案或資料夾時,字元集會編碼為 UTF-16。 因此,使用UTF-8編碼的用戶端(例如以Linux為基礎的NFS用戶端)可能無法正確轉譯某些字元集,特別是落在基本多語平面 (BMP) 外部的字元。
不支援的字元行為
在這些案例中,若 NFS 用戶端存取使用 SMB 建立且含有不支援字元的檔案,名稱會顯示為代表字元 Unicode 值的一系列數值。
例如,此資料夾是在 Windows 檔案總管中使用 BMP 以外的字元建立的。
PS Z:\SMB\> dir
Directory: Z:\SMB
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/9/2024 9:53 PM SMB𓀀𫝁😃𐒸
在 NFSv3 上,SMB 建立的資料夾會顯示:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 9 21:53 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
在 NFSv4.1,SMB 建立的資料夾會顯示如下:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 4 17:09 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
支援的字元行為
字元位於 BMP 中時,SMB 和 NFS 通訊協定及其版本之間沒有任何問題。
例如,在 Azure NetApp Files 磁碟區上使用 SMB 建立的資料夾名稱 (其中含有跨多種語言採用的 BMP 字元,如英文、德文、斯拉夫文、Runic),在所有通訊協定和版本中都會正常顯示。
- 基本拉丁文 "SMB"
- 希臘文 "ͶΘΩ"
- 斯拉夫文 "ЁЄЊ"
- Runic "ᚠᚱᛯ"
- CJK 相容性表意字元 "豈滑虜"
這是 SMB 中顯示名稱的方式:
PS Z:\SMB\> mkdir SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/11/2024 8:00 PM SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
這是從 NFSv3 顯示名稱的方式:
$ ls | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
這是從 NFSv4.1 顯示名稱的方式:
$ ls /NFSv4/SMB | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
將檔案轉換成不同的編碼方式
檔案和資料夾名稱並不是檔案系統物件中唯一使用語言編碼的部分。 檔案內容 (例如文字檔內的特殊字元) 也可能會有影響。 例如,如果嘗試以不相容格式的特殊字元儲存檔案,可能會看到錯誤訊息。 在此情況下,含有片假名字元的檔案無法儲存為 ANSI,因為該編碼中沒有這些字元。
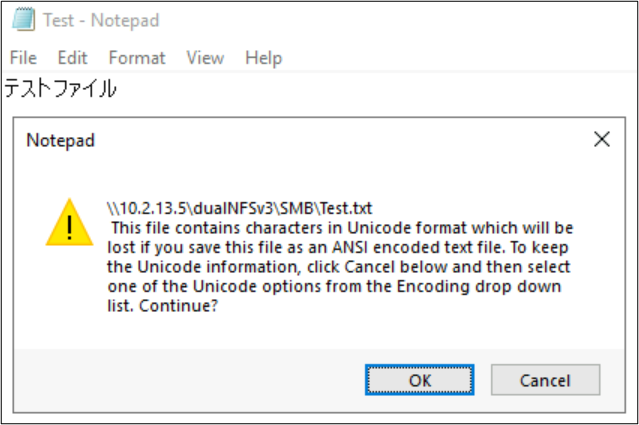
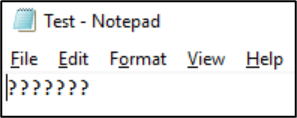
若該檔案以該格式儲存,字元就會轉換成問號:
您可以從 NAS 用戶端檢視檔案編碼。 在 Windows 用戶端上,您可以使用 [記事本] 或 Notepad++ 之類的應用程式來檢視檔案的編碼方式。 如果用戶端上安裝 Windows 子系統 Linux 版 (WSL) 或 Git,則可以使用 file 命令。
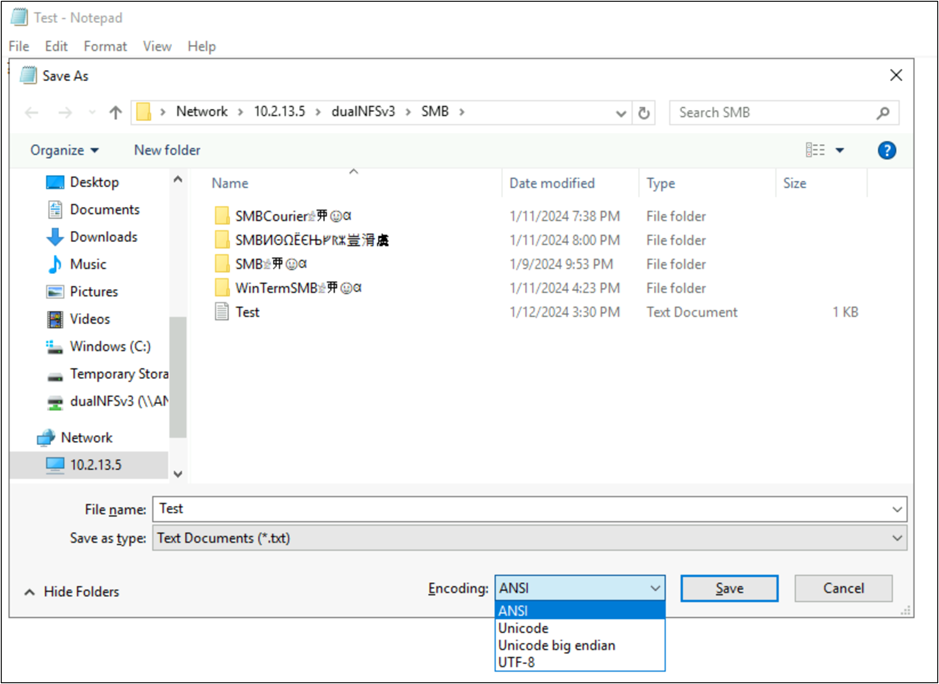
這些應用程式也可讓您藉由儲存為不同的編碼類型,來變更檔案的編碼方式。 此外,PowerShell 可用來使用 Get-Content 和 Set-Content Cmdlet 來轉換檔案的編碼方式。
例如,檔案 utf8-text.txt 會編碼為UTF-8,並包含 BMP 以外的字元。 因為使用 UTF-8,因此字元會正確顯示。
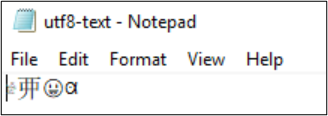
如果編碼轉換成 UTF-32,字元就不會正確顯示。
PS Z:\SMB\> Get-Content .\utf8-text.txt |Set-Content -Encoding UTF32 -Path utf32-text.txt
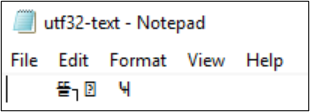
Get-Content 也可以用來顯示檔案內容。 根據預設,PowerShell 會使用 UTF-16 編碼 (字碼頁 437) 且控制台的字型選擇有限,因此無法正確顯示含有特殊字元的 UTF-8 格式檔案:
Linux 用戶端可以使用 file 命令來檢視檔案的編碼方式。 在雙重通訊協定環境中,如果使用 SMB 建立檔案,則使用 NFS 的 Linux 用戶端可以檢查檔案編碼方式。
$ file -i utf8-text.txt
utf8-text.txt: text/plain; charset=utf-8
$ file -i utf32-text.txt
utf32-text.txt: text/plain; charset=utf-32le
您可以使用 iconv 命令,在 Linux 用戶端上執行檔案編碼轉換。 若要檢視支援的編碼格式清單,請使用 iconv -l。
例如,UTF-8 編碼的檔案可以轉換成 UTF-16。
$ iconv -t UTF16 utf8-text.txt \> utf16-text.txt
$ file -i utf8-text.txt
utf8-text.txt: text/plain; **charset=utf-8**
$ file -i utf16-text.txt
utf16-text.txt: text/plain; **charset=utf-16le**
如果目的地編碼不支援檔案名稱或檔案內容上的字元集,則不允許轉換。 例如,Shift-JIS 無法支援檔案內容中的字元。
$ iconv -t SJIS utf8-text.txt SJIS-text.txt
iconv: illegal input sequence at position 0
如果檔案含有編碼所支援的字元,轉換就會成功。 例如,如果檔案包含片假名字元「テストファイル」,NFS 上的 Shift-JIS 轉換就會成功。 因為地區設定的關係,此處使用的 NFS 用戶端無法辨識 Shift-JIS,因此編碼會顯示 "unknown-8bit"。
$ cat SJIS.txt
テストファイル
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
$ iconv -t SJIS SJIS.txt \> SJIS2.txt
$ file -i SJIS.txt
SJIS.txt: text/plain; **charset=utf-8**
$ file -i SJIS2.txt
SJIS2.txt: text/plain; **charset=unknown-8bit**
因為 Azure NetApp Files 磁碟區只支援 UTF-8 相容的格式,因此片假名字元會轉換成無法讀取的格式。
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
使用 NFSv4.x 時,即使 NFSv4.x 強制使用 UTF-8 編碼,在檔案內容中存在不相容的字元時,還是會允許轉換。 在此範例中,位於 Azure NetApp Files 磁碟區上含有片假名字元的 UTF-8 編碼檔案會正確顯示檔案的內容。
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
S$ cat SJIS.txt
テストファイル
但經過轉換後,檔案中的字元就會因為編碼不相容而顯示不正確。
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
如果檔案的名稱包含 UTF-8 不支援的字元,透過 NFSv3 轉換可能會成功,但因為 NFSv4.x 強制使用通訊協定版本的 UTF-8,此轉換將會失敗。
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
字元集最佳做法
在 Azure NetApp Files 磁碟區上使用標準基本多語平面 (BMP) 以外的特殊字元或字元時,應該考慮一些最佳做法。
- 由於 Azure NetApp Files 磁碟區使用 UTF-8 磁碟區語言,因此 NFS 用戶端的檔案編碼也應該使用 UTF-8 編碼來取得一致的結果。
- 檔案名稱中的字元集或檔案內容中所含的字元集應與 UTF-8 相容,以確保顯示正確和發揮作用。
- 由於 SMB 使用 UTF-16 字元編碼,因此 BMP以外的字元可能無法在雙通訊協定磁碟區中的 NFS 上正確顯示。 盡可能將檔案內容中特殊字元的使用比例降到最低。
- 避免在檔案名稱中使用 BMP 以外的特殊字元,特別是在使用 NFSv4.1 或雙通訊協定磁碟區時。
- 若字元集不在 BMP 中,使用單一檔案通訊協定時 (僅 SMB 或僅 NFS),UTF-8 編碼應允許在 Azure NetApp Files 中顯示這些字元。 不過,在大部分情況下,雙通訊協定磁碟區無法支援這些字元集。
- Azure NetApp Files 磁碟區不支援非標準編碼 (例如 Shift-JIS)。
- Azure NetApp Files 磁碟區支援代理字組字元 (例如 Emoji)。