透過跨區域複寫 Log Analytics 工作區以增強復原能力 (預覽)
跨區域複寫 Log Analytics 工作區可讓您在發生區域失敗時切換到複寫的工作區並繼續作業,藉此增強復原能力。 本文說明 Log Analytics 工作區複寫的運作方式、如何複寫工作區、如何切換過去和切換回來,以及如何決定何時要在複寫的工作區之間進行切換。
以下影片會快速概述 Log Analytics 工作區複寫的運作方式:
重要
雖然我們有時會使用容錯移轉一詞 (例如在 API 呼叫中),但容錯移轉也常用來描述自動流程。 因此,本文會使用轉換一詞來強調切換到複寫的工作區是您手動觸發的動作。
Log Analytics 工作區複寫的運作方式
我們將您的原始工作區和區域稱為主要。 我們將複寫的工作區和替代區域稱為次要。
工作區複寫流程會在次要區域中建立工作區的執行個體。 此流程會使用與主要工作區相同的設定來建立次要工作區,而且 Azure 監視器會自動使用您日後對主要工作區設定所做的任何變更來更新次要工作區。
次要工作區是「陰影」工作區,僅供復原之用。 您無法在 Azure 入口網站中看到次要工作區,也無法直接對其進行管理或存取。
當您啟用工作區複寫時,Azure 監視器也會將擷取到主要工作區的新記錄傳送至次要區域。 在啟用工作區複寫之前擷取至工作區的記錄則不會複製過去。
如果有中斷影響到您的主要區域,您可以切換到次要區域並將所有擷取和查詢要求重新路由至次要區域。 在 Azure 緩解中斷情形,且主要工作區恢復良好狀態後,便可以切換回主要區域。
當您切換過去時,次要工作區會變成使用中狀態,主要工作區則會變成非使用中狀態。 然後,Azure 監視器會透過次要區域 (而非主要區域) 中的擷取管線來擷取新資料。 當您切換到次要區域時,Azure 監視器會將您從次要區域擷取的所有資料複寫到主要區域。 這是非同步流程,不會影響擷取延遲。
注意
在切換到次要區域後,如果主要區域無法處理傳入的記錄資料,Azure 監視器會對次要區域中的資料進行長達 11 天的緩衝處理。 前 4 天,Azure 監視器會自動重新嘗試定期複寫資料。

在區域性失敗期間防止傳輸中的數據遺失
Azure 監視器有數個機制,可確保在主要區域中發生失敗時,傳輸中的數據不會遺失。
當主要區域的管線無法處理數據時,Azure 監視器會保護到達主要區域擷取端點的數據。 當管線可供使用時,它會繼續處理傳輸中的數據,而 Azure 監視器會擷取數據並將其復寫至次要區域。
如果主要區域的擷取端點無法使用,Azure 監視器代理程式會定期重試將記錄數據傳送至端點。 次要區域中的數據擷取端點會在觸發切換后幾分鐘開始接收來自代理程序的數據。
如果您撰寫自己的用戶端將記錄數據傳送至 Log Analytics 工作區,請確定客戶端處理失敗的擷取要求。
部署考量
目前不支援複寫連結至專用叢集的 Log Analytics 工作區。
從工作區刪除記錄的清除作業 (英文) 會同時從主要和次要工作區中移除相關的記錄。 如果其中一個工作區執行個體無法使用,清除作業就會失敗。
Azure 監視器支持查詢非使用中區域。 當您在區域之間切換時,查詢型警示會繼續運作,除非作用中區域中的警示服務無法正常運作,或警示規則無法使用。 目前不支援跨區域複寫警示規則。
當您為與 Sentinel 互動的工作區啟用複寫時,最多可能需要 12 天的時間,才能將關注清單和威脅情報資料完全複寫到次要工作區。
在切換期間無法起始工作區管理作業,包括:
- 變更工作區保留期、定價層、每日上限等等
- 變更網路設定
- 透過新的自訂記錄變更結構描述,或連接來自新資源提供者的平台記錄,例如傳送來自新資源類型的診斷記錄
在轉換期間,不支援以舊版 Log Analytics 代理程式功能為目標的解決方案。 在轉換期間,解決方案數據會從 所有 代理程式內嵌。
容錯移轉流程會更新網域名稱系統 (DNS) 記錄,以將所有擷取要求重新路由至次要區域進行處理。 某些 HTTP 用戶端具有「黏性連線」,可能需要較長的時間才能取得 DNS 更新的 DNS。 在轉換期間,這些用戶端可能會嘗試透過主要區域擷取記錄一段時間。 您可能會使用各種用戶端將記錄擷取到主要工作區,包括舊版 Log Analytics 代理程式、Azure 監視器代理程式、程序代碼(使用記錄擷取 API 或舊版 HTTP 數據收集 API),以及其他服務,例如Microsoft Sentinel。
目前不支援這些功能,或僅提供部分支援:
功能 支援 輔助資料表方案 不支援。 Azure 監視器不會將具有輔助記錄方案之資料表中的資料複寫到次要工作區。 因此,此資料在發生區域失敗時不會受到資料遺失的保護,且在您轉換至次要工作區時無法使用。 搜尋作業、還原 部分支援 - 搜尋作業和還原作業會建立資料表,並在其中填入搜尋結果或還原的資料。 在啟用工作區複寫後,針對這些作業所建立的新資料表會複寫到次要工作區。 在您啟用複寫之前所填入的資料表則不會進行複寫。 如果在您進行轉換時,系統正在進行這些作業,結果會不符合您的預期。 視工作區的健康狀態和確切的時間而定,作業可能會成功完成但未進行複寫,或者也可能會失敗。 透過 Log Analytics 工作區的 Application Insights 不支援 VM 深入解析 不支援 容器深入解析 不支援 私人連結 容錯移轉期間不支援
支援的區域
目前只有一組按區域群組 (地理位置相鄰區域的群組) 加以組織的有限區域支援工作區複寫。 當您啟用複寫時,請從與工作區主要位置相同的區域群組中的支援區域清單中選取次要位置。 例如,位於西歐的工作區可以複寫到北歐,但無法複寫到美國西部 2,因為這兩個區域位於不同的區域群組中。
目前支援的區域群組和區域如下:
| 區域群組 | 地區 | 備註 | ||
|---|---|---|---|---|
| 北美洲 | 美國東部 | 美國東部無法復寫美國東部 2 和美國中南部區域。 | ||
| 美國東部 2 | 美國東部 2 無法復寫至美國東部和美國中南部區域。 | |||
| 美國西部 | ||||
| 美國西部 2 | ||||
| 美國中部 | ||||
| 美國中南部 | 美國中南部無法復寫至美國東部和美國東部 2 個區域。 | |||
| 加拿大中部 | ||||
| 歐洲 | 西歐 | |||
| 北歐 | ||||
| 英國南部 | ||||
| 英國西部 | ||||
| 德國中西部 | ||||
| 法國中部 |
資料落地需求
不同的客戶有不同的資料落地需求,因此請務必控制資料的儲存位置。 Azure 監視器會在您選擇的主要和次要區域中處理和儲存記錄。 如需詳細資訊,請參閱支援的區域 (英文)。
支援Microsoft Sentinel 和其他服務
使用 Log Analytics 工作區的各種服務和功能可與工作區複寫和轉換相容。 當您切換到次要工作區時,這些服務和功能可繼續運作。
例如,造成記錄擷取延遲的區域網路問題可能會影響Microsoft Sentinel 客戶。 使用複寫的工作區的客戶可以切換至其次要區域,以繼續使用其 Log Analytics 工作區和 Sentinel。 不過,如果網路問題影響到 Sentinel 的服務健康狀態,則切換到另一個區域並不會緩解問題。
某些 Azure 監視器體驗 (包括 Application Insights 和 VM Insights) 目前只與工作區複寫和轉換部分相容。 如需完整清單,請參閱 部署考慮。
計價模式
當您啟用工作區複寫時,會向您收取內嵌至工作區之所有數據的複寫費用。
重要
如果您使用 Azure 監視器代理程式將數據傳送至工作區、記錄擷取 API、Azure 事件中樞 或其他使用數據收集規則的數據源,請務必將數據收集規則與工作區的數據收集端點產生關聯。 此關聯可確保您內嵌的數據會復寫到次要工作區。 如果您未將數據收集規則與工作區數據收集端點產生關聯,即使您未復寫數據,仍需支付您內嵌至工作區的所有數據的費用。
需要的權限
| 動作 | 需要的權限 |
|---|---|
| 啟用工作區複寫 |
Microsoft.OperationalInsights/workspaces/write 和 Microsoft.Insights/dataCollectionEndpoints/write 權限,例如,監視參與者內建角色提供的權限 |
| 切換過去和切換回來 (觸發容錯移轉和容錯回復) |
Microsoft.OperationalInsights/locations/workspaces/failover、Microsoft.OperationalInsights/workspaces/failback、 Microsoft.Insights/dataCollectionEndpoints/triggerFailover/action和 Microsoft.Insights/dataCollectionEndpoints/triggerFailback/action 許可權,例如,監視參與者內建角色所提供的許可權 |
| 檢查工作區狀態 | Log Analytics 工作區的 Microsoft.OperationalInsights/workspaces/read 權限,例如,監視參與者內建角色提供的權限 |
啟用和停用工作區複寫
您可以使用 REST 命令來啟用和停用工作區複寫。 該命令會觸發長時間執行的作業,這表示新設定可能需要幾分鐘的時間才會完成套用。 在啟用複寫後,所有資料表 (資料類型) 最多可能需要一個小時才會開始複寫,而且有些資料類型可能會比其他資料類型更早開始複寫。 在啟用工作區複寫後,對資料表結構描述所做的變更 (例如,您建立的新自訂記錄資料表或自訂欄位,或為新的資源類型設定的診斷記錄) 最多可能需要一個小時才會開始複寫。
啟用工作區複寫
若要在 Log Analytics 工作區上啟用複寫,請使用這個 PUT 命令:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": true,
"location": "<secondary_region>"
}
},
"location": "<primary_region>"
}
其中:
-
<subscription_id>:與您的工作區相關的訂用帳戶識別碼。 -
<resourcegroup_name>:包含 Log Analytics 工作區資源的資源群組。 -
<workspace_name>:工作區的名稱。 -
<primary_region>:Log Analytics 工作區的主要區域。 -
<secondary_region>:Azure 監視器在其中建立次要工作區的區域。
如需支援的 location 值,請參閱支援的區域 (英文)。
PUT 命令是需要一些時間才能完成的長時間執行作業。 呼叫成功會傳回 200 狀態代碼。 您可以追蹤要求的佈建狀態,如檢查要求的佈建狀態所述。
檢查要求的佈建狀態
若要檢查要求的佈建狀態,請執行這個命令 GET:
GET
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
其中:
-
<subscription_id>:與您的工作區相關的訂用帳戶識別碼。 -
<resourcegroup_name>:包含 Log Analytics 工作區資源的資源群組。 -
<workspace_name>:Log Analytics 工作區的名稱。
請使用 GET 命令來驗證工作區的佈建狀態有從 Updating 變更為 Succeeded,而且次要區域的設定符合預期。
注意
當您為與 Sentinel 互動的工作區啟用複寫時,最多可能需要 12 天的時間,才能將關注清單和威脅情報資料完全複寫到次要工作區。
建立數據收集規則與工作區數據收集端點的關聯
Azure 監視器代理程式、記錄擷取 API,以及 Azure 事件中樞 收集數據,並根據您設定資料收集規則 (DCR) 的方式,將其傳送至您指定的目的地。
如果您有會將資料傳送至主要工作區的資料收集規則,則必須將這些規則與當您啟用工作區複寫時由 Azure 監視器建立的系統資料收集端點 (DCE) (英文) 建立關聯。 工作區數據收集端點的名稱與您的工作區標識符相同。 只有您與工作區數據收集端點建立關聯的數據收集規則,才能進行復寫和切換。 此行為可讓您指定一組要複寫的記錄資料流,以協助您控制複寫成本。
若要使用資料收集規則複寫您收集的數據,請將資料收集規則與工作區數據收集端點產生關聯:
在 Azure 入口網站中,選取 [資料收集規則]。
從 [資料收集規則] 畫面中,選取會將資料傳送至主要 Log Analytics 工作區的資料收集規則。
在 [資料收集規則 概觀 ] 頁面上,選取 [ 設定 DCE ],然後從可用的清單中選取工作區數據收集端點:
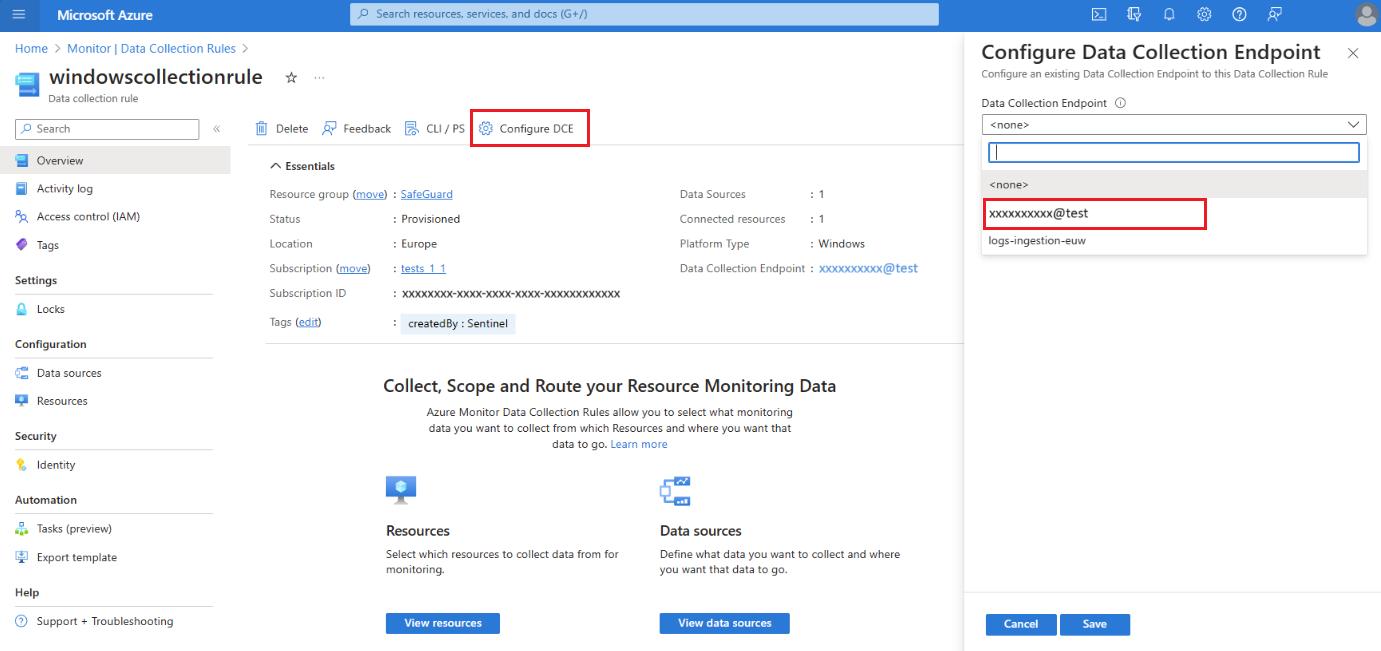 如需有關系統 DCE 的詳細資料,請檢查工作區物件屬性。
如需有關系統 DCE 的詳細資料,請檢查工作區物件屬性。

重要
連接到工作區數據收集端點的數據收集規則只能以該特定工作區為目標。 資料收集規則不得以其他目的地為目標,例如其他工作區或 Azure 儲存體帳戶。
停用工作區複寫
若要停用工作區的複寫,請使用這個 PUT 命令:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": false
}
},
"location": "<primary_region>"
}
其中:
-
<subscription_id>:與您的工作區相關的訂用帳戶識別碼。 -
<resourcegroup_name>:包含工作區資源的資源群組。 -
<workspace_name>:工作區的名稱。 -
<primary_region>:工作區的主要區域。
PUT 命令是需要一些時間才能完成的長時間執行作業。 呼叫成功會傳回 200 狀態代碼。 您可以追蹤要求的佈建狀態,如檢查要求的佈建狀態所述。
監視工作區和服務健康狀態
擷取延遲或查詢失敗是通常可藉由容錯移轉至次要區域來加以處理之問題的範例。 使用服務健康狀態通知和記錄查詢可以偵測到這類問題。
服務健康狀態通知對於服務相關問題很有用。 若要找出影響特定工作區 (而可能不是整個服務) 的問題,您可以使用其他措施:
- 根據工作區資源健康狀態建立警示 (英文)
- 為工作區健康狀態計量 (英文) 設定您自己的閾值
- 建立您自己的監視查詢來作為工作區的自訂健康狀態指標 (如使用查詢來監視工作區效能所述),以便:
- 測量每個資料表的擷取延遲
- 識別延遲的來源是收集代理程式還是擷取管線
- 監視每個資料表和資源的擷取量異常
- 監視每個資料表、使用者或資源的查詢成功率
- 根據您的查詢建立警示
注意
您也可以使用記錄查詢來監視次要工作區,但請記住,記錄複寫會在批次作業中進行。 測量到的延遲可能會變動,而且不表示次要工作區有任何健康狀態問題。 如需詳細資訊,請參閱稽核非使用中工作區。
切換至次要工作區
在轉換期間,大部分作業的運作情況會與使用主要工作區和區域時相同。 不過,某些作業的行為會稍有不同,或是會遭到封鎖。 如需詳細資訊,請參閱 部署考慮。
何時應該切換過去?
請根據進行中的效能和狀況監控以及系統標準和需求,決定何時要切換到次要工作區以及何時要切換回主要工作區。
您的轉換計劃有幾點需要考量,如下列幾個小節所述。
問題類型和範圍
轉換流程會將擷取和查詢要求路由傳送至次要區域,這通常會略過造成主要區域延遲或失敗的任何錯誤元件。 因此,遇到以下情況時,轉換可能沒有多大幫助:
- 基礎資源發生跨區域問題。 例如,如果主要區域和次要區域中的相同資源類型都失敗。
- 您遇到與工作區管理相關的問題,例如變更工作區保留期。 工作區管理作業一律會在主要區域中處理。 在轉換期間,工作區管理作業會遭到封鎖。
問題持續期間
轉換不會瞬間完成。 重新路由要求的流程需要仰賴 DNS 更新,有些用戶端在幾分鐘內便能取得更新,有些用戶端則可能需要更多時間才能取得。 因此,了解問題是否可以在幾分鐘內解決會很有用。 如果發現到的問題是一致的或連續的,請勿等著切換過去。 以下列出一些範例:
擷取:主要區域中的擷取管線問題可能會影響將資料複寫到次要工作區的行為。 在轉換期間,記錄會改為傳送至次要區域中的擷取管線。
查詢:如果主要工作區中的查詢失敗或逾時,記錄搜尋警示可能會受到影響。 在此案例中,請切換到次要工作區,以確定系統會正確觸發所有警示。
次要工作區資料
在啟用複寫前擷取至主要工作區的記錄不會複製到次要工作區。 如果您在三小時前啟用工作區複寫,現在切換到次要工作區,則查詢只能傳回過去三個小時的資料。
在轉換期間切換區域之前,次要工作區必須包含有用的記錄量。 建議您在啟用複寫後至少等候一週,再觸發轉換。 七天的時間可讓次要區域中有足夠的資料可供使用。
觸發轉換
在切換過去之前,請先確認工作區複寫作業已成功完成。 只有在次要工作區設定正確時,轉換才會成功。
若要切換到次要工作區,請使用這個 POST 命令:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/locations/<secondary_region>/workspaces/<workspace_name>/failover?api-version=2023-01-01-preview
其中:
-
<subscription_id>:與您的工作區相關的訂用帳戶識別碼。 -
<resourcegroup_name>:包含工作區資源的資源群組。 -
<secondary_region>:要在轉換期間切換到的區域。 -
<workspace_name>:要在轉換期間切換到之工作區的名稱。
POST 命令是需要一些時間才能完成的長時間執行作業。 呼叫成功會傳回 202 狀態代碼。 您可以追蹤要求的佈建狀態,如檢查要求的佈建狀態所述。
切換回主要工作區
切換回來的流程會把將查詢和記錄擷取要求重新路由至次要工作區的作業取消。 切換回來時,Azure 監視器會變回將查詢和記錄擷取要求路由傳送至主要工作區。
當您切換到次要區域時,Azure 監視器會將次要工作區的記錄複寫到主要工作區。 如果中斷影響到主要區域中的記錄擷取流程,Azure 監視器可能需要一些時間才能完成將複寫的記錄擷取至主要工作區的作業。
何時應該切換回來?
您的切換回來計劃有幾點需要考量,如下列幾個小節所述。
記錄複寫狀態
在切換回來之前,請確認 Azure 監視器已完成轉換至主要區域期間所擷取之所有記錄的複寫。 如果您在所有記錄複寫到主要工作區之前就切換回來,在記錄擷取完成前,您的查詢可能只會傳回部分結果。
您可以在 Azure 入口網站中查詢非使用中區域的主要工作區,如稽核非使用中工作區所述。
主要工作區健康狀態
在準備切換回主要工作區時,有兩個重要的健康狀態項目要檢查:
- 確認主要工作區和區域沒有未完成的服務健康狀態通知。
- 確認主要工作區有如預期般擷取記錄和處理查詢。
如需範例來了解如何在次要工作區處於使用中狀態時查詢主要工作區,以及如何略過將要求重新路由至次要工作區的作業,請參閱稽核非使用中工作區。
觸發切換回來
在切換回來之前,請先確認主要工作區健康狀態,並完成記錄的複寫。
切換回來的流程會更新 DNS 記錄。 在 DNS 記錄更新之後,所有用戶端可能需要一些時間才會收到更新後的 DNS 設定,並繼續路由傳送至主要工作區。
若要切換回主要工作區,請使用這個 POST 命令:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>/failback?api-version=2023-01-01-preview
其中:
-
<subscription_id>:與您的工作區相關的訂用帳戶識別碼。 -
<resourcegroup_name>:包含工作區資源的資源群組。 -
<workspace_name>:要在轉換期間切換回之工作區的名稱。
POST 命令是需要一些時間才能完成的長時間執行作業。 呼叫成功會傳回 202 狀態代碼。 您可以追蹤要求的佈建狀態,如檢查要求的佈建狀態所述。
稽核非使用中工作區
根據預設,工作區的作用中區域是您建立工作區的區域,而非使用中區域是次要區域,其中 Azure 監視器會建立複寫的工作區。
當您觸發容錯移轉時,此參數即次要區域會啟動,而主要區域會變成非使用中。 我們說它是非使用中,因為它不是記錄擷取和查詢要求的直接目標。
在切換區域之前,先查詢非使用中區域,以確認非使用中區域中的工作區具有您預期在那裡會看到的記錄,這非常有用。
查詢非使用中區域
若要查詢非使用中區域中的記錄資料,請使用下列 GET 命令:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=<query>×pan=<timespan-in-ISO8601-format>&overrideWorkspaceRegion=<primary|secondary>
例如,若要在次要區域中針對過去一天執行類似 Perf | count 的簡單查詢,請使用:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=Perf%20|%20count×pan=P1D&overrideWorkspaceRegion=secondary
您可以藉由檢查 LAQueryLogs 資料表中的這些欄位來確認 Azure 監視器有在預定區域中執行查詢 (該資料表是在您啟用 Log Analytics 工作區中的查詢稽核時建立的):
-
isWorkspaceInFailover:指出工作區在查詢期間是否處於轉換模式。 資料類型為布林值 (True、False)。 -
workspaceRegion:查詢的目標工作區所在的區域。 資料類型為字串。
使用查詢來監視工作區效能
建議您使用本節的查詢來建立警示規則,以在可能有工作區健康狀態或效能問題時收到通知。 不過,您需要仔細考慮再做出切換過去的決定,且不應交由系統自動幫您決定。
在查詢規則中,您可以定義條件,以在違規次數超過指定次數後切換到次要工作區。 如需詳細資訊,請參閱建立或編輯記錄搜尋警示規則 (英文)。
工作區效能的兩個重要測量包括「擷取延遲」和「擷取量」。 下列各節會探索這些監視選項。
監視端對端擷取延遲
擷取延遲會測量將記錄擷取到工作區所需的時間。 當初始的記錄事件發生時,就會開始測量時間,當記錄儲存到工作區時,時間的測量就會結束。 擷取延遲總計由兩個部分組成:
- 代理程式延遲:代理程式回報事件所需的時間。
- 擷取管線 (後端) 延遲:擷取管線處理記錄並將記錄寫入工作區所需的時間。
不同的資料類型有不同的擷取延遲。 您可以個別測量每個資料類型的擷取,也可以建立適用於所有類型的泛型查詢,以及對您來說重要性更高的特定類型所適用的更精細查詢。 建議您測量擷取延遲的第 90 個百分位數,因為相較於平均值或第 50 個百分位數 (中位數),這種測量方式會對變化更為敏感。
下列各節說明如何使用查詢來檢查工作區的擷取延遲。
評估特定資料表的基準擷取延遲
一開始,請先判斷特定資料表在幾天時間內的基準延遲。
以下範例查詢會在 Perf 資料表上建立擷取延遲第 90 個百分位數的圖表:
// Assess the ingestion latency baseline for a specific data type
Perf
| where TimeGenerated > ago(3d)
| project TimeGenerated,
IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize LatencyIngestion90Percentile=percentile(IngestionDurationSeconds, 90) by bin(TimeGenerated, 1h)
| render timechart
在執行查詢後,請檢閱結果和所呈現的圖表,以判斷該資料表的預期延遲。
監視目前的擷取延遲並建立警示
在建立特定資料表的基準擷取延遲之後,請根據短時間內的延遲變化,為資料表建立記錄搜尋警示規則 (英文)。
以下查詢會計算過去 20 分鐘內的擷取延遲:
// Track the recent ingestion latency (in seconds) of a specific table
Perf
| where TimeGenerated > ago(20m)
| extend IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize Ingestion90Percent_seconds=percentile(IngestionDurationSeconds, 90)
可以預期的是,延遲一定會有一些波動,因此請建立警示規則條件來檢查查詢所傳回的值是否明顯大於基準。
判斷擷取延遲的來源
當您發現擷取延遲總計在往上攀升時,您可以使用查詢來判斷延遲的來源是代理程式還是擷取管線。
以下查詢會分別繪製代理程式和管線第 90 個百分位數延遲的圖表:
// Assess agent and pipeline (backend) latency
Perf
| where TimeGenerated > ago(1h)
| extend AgentLatencySeconds = (_TimeReceived-TimeGenerated)/1s,
PipelineLatencySeconds=(ingestion_time()-_TimeReceived)/1s
| summarize percentile(AgentLatencySeconds,90), percentile(PipelineLatencySeconds,90) by bin(TimeGenerated,5m)
| render columnchart
注意
雖然圖表會將第 90 個百分位數的資料顯示為堆疊直條,但兩個圖表的資料總和不會等於擷取總計的第 90 個百分位數。
監視擷取量
擷取量測量有助於識別工作區之總計或資料表特定擷取量的未預期變化。 查詢量測量有助於識別記錄擷取的效能問題。 一些實用的數量測量包括:
- 每個資料表的擷取量總計
- 固定不變的擷取量 (停滯)
- 擷取異常 - 擷取量的峰值和谷值
下列各節說明如何使用查詢來檢查工作區的擷取量。
監視每個資料表的擷取量總計
您可以定義查詢來監視工作區中每個資料表的擷取量。 該查詢可以包含警示,以檢查總計或資料表特定擷取量是否有未預期的變化。
以下查詢會以每秒 MB 數為單位來計算每個資料表在過去一小時內的擷取量總計:
// Calculate total ingestion volume over the past hour per table
Usage
| where TimeGenerated > ago(1h)
| summarize BillableDataMB = sum(_BilledSize)/1.E6 by bin(TimeGenerated,1h), DataType
檢查擷取停滯
如果您透過代理程式來擷取記錄,則可以使用代理程式的「活動訊號」來偵測連線。 靜止的活動訊號表示系統已停止將記錄擷取至工作區。 當查詢資料顯示擷取停滯時,您可以定義條件來觸發所需的回應。
下列查詢會檢查代理程式的活動訊號以偵測連線問題:
// Count agent heartbeats in the last ten minutes
Heartbeat
| where TimeGenerated>ago(10m)
| count
監視擷取異常
您可以透過各種方式識別工作區擷取量資料的峰值和谷值。 請使用 series_decompose_anomalies() 函式,從您在工作區中監視的擷取量中擷取異常,或建立您自己的異常偵測器來支援您獨特的工作區案例。
使用 series_decompose_anomalies 來識別異常
series_decompose_anomalies() 函式可識別一系列資料值中的異常。 以下查詢會計算 Log Analytics 工作區中每個資料表的每小時擷取量,並使用 series_decompose_anomalies() 來識別異常:
// Calculate hourly ingestion volume per table and identify anomalies
Usage
| where TimeGenerated > ago(24h)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| summarize
Timestamp=make_list(TimeGenerated),
IngestionVolumeMB=make_list(IngestionVolumeMB)
by DataType
| extend series_decompose_anomalies(IngestionVolumeMB)
| mv-expand
Timestamp,
IngestionVolumeMB,
series_decompose_anomalies_IngestionVolumeMB_ad_flag,
series_decompose_anomalies_IngestionVolumeMB_ad_score,
series_decompose_anomalies_IngestionVolumeMB_baseline
| where series_decompose_anomalies_IngestionVolumeMB_ad_flag != 0
如需如何使用 series_decompose_anomalies() 來偵測記錄資料異常的詳細資訊,請參閱在 Azure 監視器中使用 KQL 機器學習功能來偵測和分析異常 (英文)。
建立您自己的異常偵測器
您可以建立自訂的異常偵測器,以支援您工作區設定的案例需求。 本節會提供範例來示範此流程。
下列查詢會計算:
- 預期的擷取量:每小時,依資料表 (根據數個中位數的中位數,但您可以自訂此邏輯)
- 實際擷取量:每小時,依資料表
為了篩選出預期擷取量與實際擷取量之間的細微差異,此查詢會套用兩個篩選:
- 變動率:每個資料表超過 150% 或低於 66% 的預期量
- 變動量:指出增加或減少的擷取量是否超過該資料表每月擷取量的 0.1%
// Calculate expected vs actual hourly ingestion per table
let TimeRange=24h;
let MonthlyIngestionByType=
Usage
| where TimeGenerated > ago(30d)
| summarize MonthlyIngestionMB=sum(Quantity) by DataType;
// Calculate the expected ingestion volume by median of hourly medians
let ExpectedIngestionVolumeByType=
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionMedian=percentile(Quantity, 50) by bin(TimeGenerated, 1h), DataType
| summarize ExpectedIngestionVolumeMB=percentile(IngestionMedian, 50) by DataType;
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| join kind=inner (ExpectedIngestionVolumeByType) on DataType
| extend GapVolumeMB = round(IngestionVolumeMB-ExpectedIngestionVolumeMB,2)
| where GapVolumeMB != 0
| extend Trend=iff(GapVolumeMB > 0, "Up", "Down")
| extend IngestedVsExpectedAsPercent = round(IngestionVolumeMB * 100 / ExpectedIngestionVolumeMB, 2)
| join kind=inner (MonthlyIngestionByType) on DataType
| extend GapAsPercentOfMonthlyIngestion = round(abs(GapVolumeMB) * 100 / MonthlyIngestionMB, 2)
| project-away DataType1, DataType2
// Determine whether the spike/deep is substantial: over 150% or under 66% of the expected volume for this data type
| where IngestedVsExpectedAsPercent > 150 or IngestedVsExpectedAsPercent < 66
// Determine whether the gap volume is significant: over 0.1% of the total monthly ingestion volume to this workspace
| where GapAsPercentOfMonthlyIngestion > 0.1
| project
Timestamp=format_datetime(todatetime(TimeGenerated), 'yyyy-MM-dd HH:mm:ss'),
Trend,
IngestionVolumeMB,
ExpectedIngestionVolumeMB,
IngestedVsExpectedAsPercent,
GapAsPercentOfMonthlyIngestion
監視查詢的成功和失敗
每個查詢都會傳回指出成功或失敗的回應碼。 當查詢失敗時,回應中也會包含錯誤類型。 錯誤次數遽增可能表示工作區可用性或服務效能有問題。
以下查詢會計算有多少查詢傳回了伺服器錯誤碼:
// Count query errors
LAQueryLogs
| where ResponseCode>=500 and ResponseCode<600
| count