針對 Azure 監視器中的 Prometheus 計量收集進行疑難排解
請遵循本文中的步驟,判斷未如預期在 Azure 監視器中收集到 Prometheus 計量的原因。
複本 Pod 會從 kube-state-metrics、ama-metrics-prometheus-config configmap 中的自訂抓取目標以及自訂資源中定義的自訂抓取目標抓取計量。 DaemonSet Pod 會從其個別節點上的下列目標抓取計量:kubelet、cAdvisor、node-exporter 和 ama-metrics-prometheus-config-node configmap 中的自訂抓取目標。 您要檢視記錄和 Prometheus UI 的 Pod 取決於您正在調查的抓取目標。
使用 PowerShell 指令碼進行疑難排解
如果您在嘗試啟用 AKS 叢集的監視時發生錯誤,請遵循這些指示以執行疑難排解指令碼。 此指令碼旨在對叢集上的任何設定問題進行基本診斷,您可以在建立支援要求時附加產生的檔案,以便更快地解決支援案例。
計量節流
Azure 監視器適用於 Prometheus 的受管理服務具有預設的擷取限制和配額。 當您達到擷取限制時,可能會發生節流。 您可以要求增加這些上限。 如需 Prometheus 計量限制的資訊,請參閱 Azure 監視器服務限制 (部分機器翻譯)。
在 Azure 入口網站中,瀏覽至您的 Azure 監視器工作區。 移至 Metrics,然後選取計量 Active Time Series % Utilization 和 Events Per Minute Received % Utilization。 確認兩者都低於100%。
如需監視和警示擷取計量的詳細資訊,請參閱 監視 Azure 監視器工作區計量擷取。
計量資料收集中的間歇性差距
在節點更新期間,您可能會看到從叢集層級收集器所收集計量數據的度量數據有 1 到 2 分鐘的差距。 發生此差距是因為在一般更新程序中,執行節點正在更新中。 這會影響整個叢集的目標,例如 kube-state-metrics 和指定的自訂應用程式目標。 手動或透過自動更新來更新您的叢集時,就會發生這種情況。 這是預期的行為,發生的原因是執行節點正在更新。 此行為不會影響任何建議的警示規則。
Pod 狀態
使用下列命令來檢查 Pod 狀態:
kubectl get pods -n kube-system | grep ama-metrics
當服務正確執行時,會傳回下列格式 ama-metrics-xxxxxxxxxx-xxxxx 的 Pod 清單:
ama-metrics-operator-targets-*ama-metrics-ksm-*ama-metrics-node-*叢集上每個節點的Pod。
每個 Pod 狀態都應該為 Running,而且重新啟動的次數等於已套用的 configmap 變更次數。 ama-metrics-operator-targets-* Pod 可能會在開始時額外重新啟動,這是預期的:

如果每個 Pod 狀態都是 Running,但一或多個 Pod 具有重新啟動,則請執行下列命令:
kubectl describe pod <ama-metrics pod name> -n kube-system
- 此命令會提供重新啟動的原因。 如果已進行 configmap 變更,則預期會有 Pod 重新啟動。 如果重新啟動的原因為
OOMKilled,則 Pod 無法跟上計量的數量。 請參閱計量數量的規模建議。
如果 Pod 如預期般執行,則下一個檢查位置是容器記錄。
檢查重新標記設定
如果遺漏計量,您也可以檢查是否有重新標記設定。 使用重新標記設定時,請確定重新標記不會篩選出目標,且設定的標籤正確符合目標。 如需詳細資訊,請參閱 Prometheus relabel config 檔。
容器記錄
使用下列命令來檢視容器記錄:
kubectl logs <ama-metrics pod name> -n kube-system -c prometheus-collector
啟動時,會以紅色列印任何初始錯誤,而以黃色列印警告。 (檢視彩色記錄至少需要 PowerShell 第 7 版或 Linux 發行版本。)
- 確認取得驗證權杖時是否發生問題:
- 將會每隔 5 分鐘記錄 [AKS 資源沒有設定] 訊息一次。
- Pod 會每隔 15 分鐘重新啟動一次,以在發生下列錯誤時再試一次:[AKS 資源沒有設定]。
- 如果出現此錯誤,請檢查您的資源群組中是否存在資料收集規則和資料收集端點。
- 另請確認 Azure 監視器工作區是否存在。
- 請確認您沒有私人 AKS 叢集,且未連結到任何其他服務的 Azure 監視器 私人連結範圍。 目前不支援此案例。
設定處理
使用下列命令來檢視容器記錄:
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c config-reader
- 確認剖析 Prometheus 設定、在啟用任何預設抓取目標的情況下合併以及驗證完整設定時未發生任何錯誤。
- 如果您確實包含自訂 Prometheus 設定,請確認已在記錄中辨識出該設定。 如果不是:
- 確認您的 configmap 具有正確的名稱:
kube-system命名空間中的ama-metrics-prometheus-config。 - 確認在 configmap 中,Prometheus 設定位於
data下的區段prometheus-config中,如這裡所示:kind: ConfigMap apiVersion: v1 metadata: name: ama-metrics-prometheus-config namespace: kube-system data: prometheus-config: |- scrape_configs: - job_name: <your scrape job here>
- 確認您的 configmap 具有正確的名稱:
- 如果您確實建立了自訂資源,那麼在建立 Pod/服務監視器期間您應該會看到任何驗證錯誤。 如果您仍然看不到目標中的計量,請確定記錄沒有顯示任何錯誤。
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c targetallocator
- 確認
MetricsExtension中沒有關於使用 [Azure 監視器] 工作區進行驗證的錯誤。 - 確認
OpenTelemetry collector沒有關於抓取目標的錯誤。
執行以下命令:
kubectl logs <ama-metrics pod name> -n kube-system -c addon-token-adapter
- 如果使用 [Azure 監視器] 工作區進行驗證時發生問題,則此命令將會顯示錯誤。 下列範例顯示沒有問題的記錄:
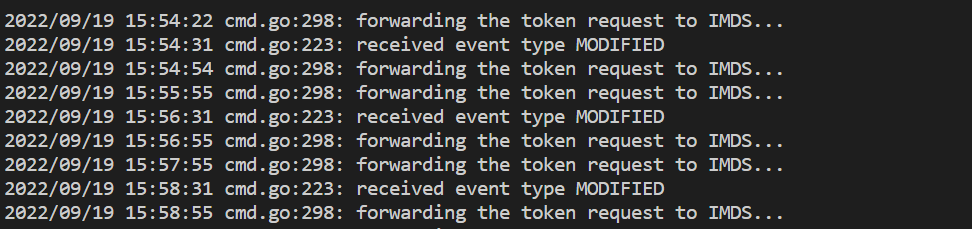

如果記錄中沒有任何錯誤,則可以將 Prometheus 介面用於偵錯,以驗證所要抓取的預期設定和目標。
Prometheus 介面
每個 ama-metrics-* Pod 都有可在連接埠 9090 上使用的 Prometheus 代理程式模式使用者介面。
自訂設定和自訂資源目標由 ama-metrics-* Pod 抓取,而節點目標由 ama-metrics-node-* Pod 抓取。
連接埠轉送至複本 Pod 或其中一個精靈集,以檢查設定、服務探索和目標端點 (如同此處所述),確認自訂設定正確,已探索每個作業的預期目標,以及抓取特定目標未發生錯誤。
執行 kubectl port-forward <ama-metrics pod> -n kube-system 9090 命令。
將瀏覽器開啟至位址
127.0.0.1:9090/config。 此使用者介面有完整的抓取設定。 確認所有作業都包含在設定中。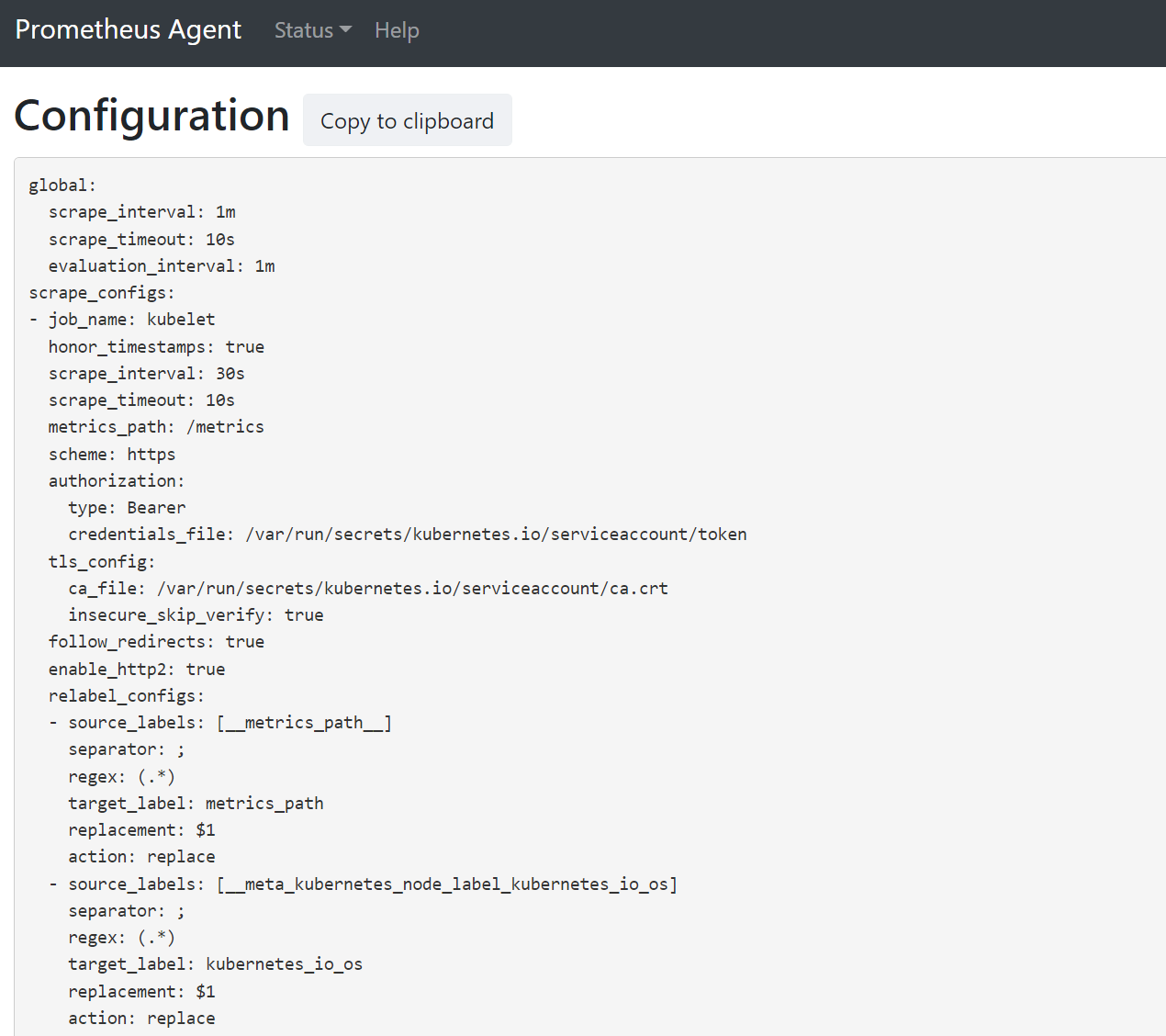
移至
127.0.0.1:9090/service-discovery以檢視所指定服務探索物件所探索到的目標,以及 relabel_configs 已將目標篩選為何。 例如,當遺漏特定 Pod 的計量時,則您可以找出是否已探索到該 Pod 和其 URI 為何。 然後,您可以在查看目標來查看是否發生任何抓取錯誤時使用此 URI。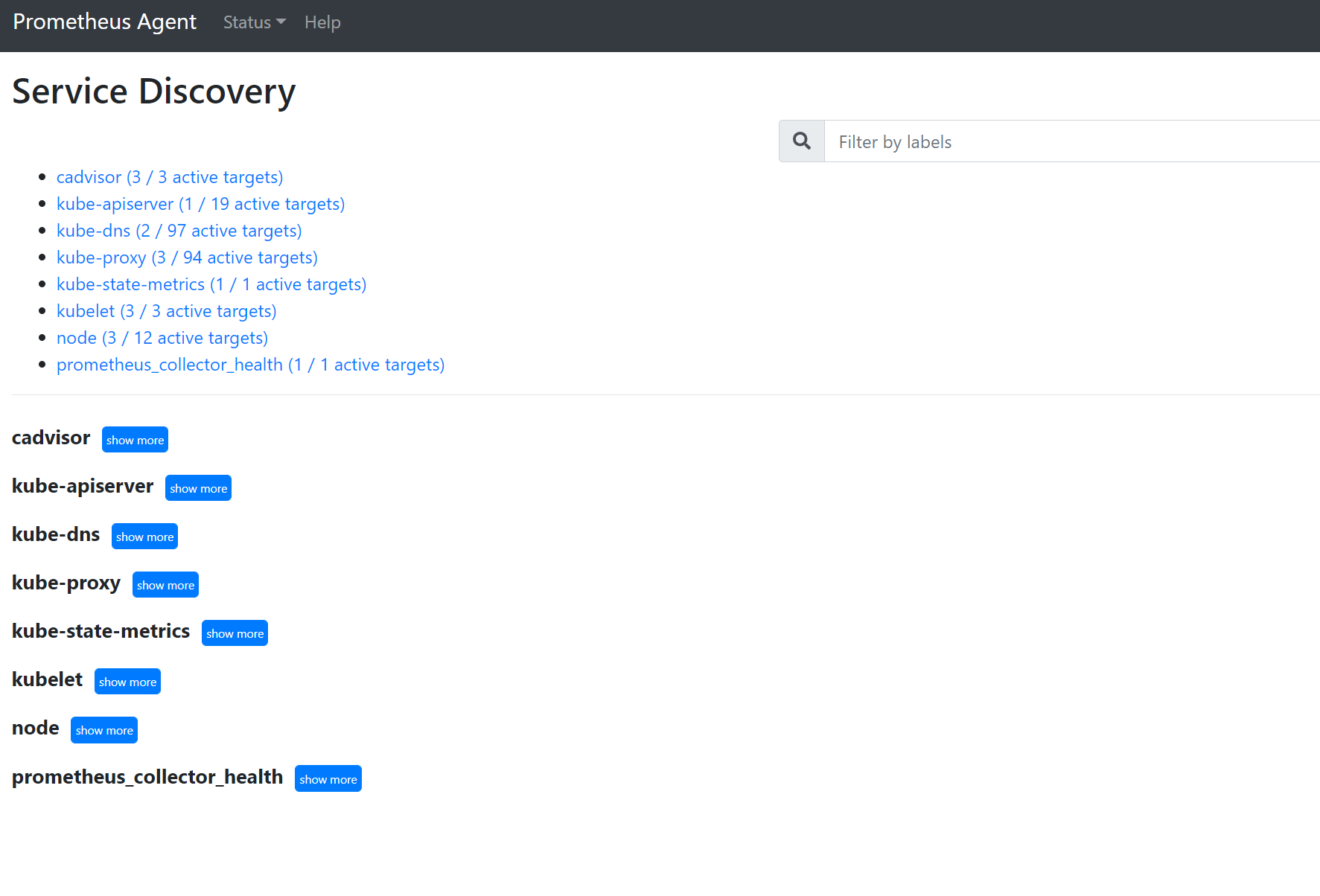
移至
127.0.0.1:9090/targets以檢視所有工作、上次抓取該工作端點的時間,以及任何錯誤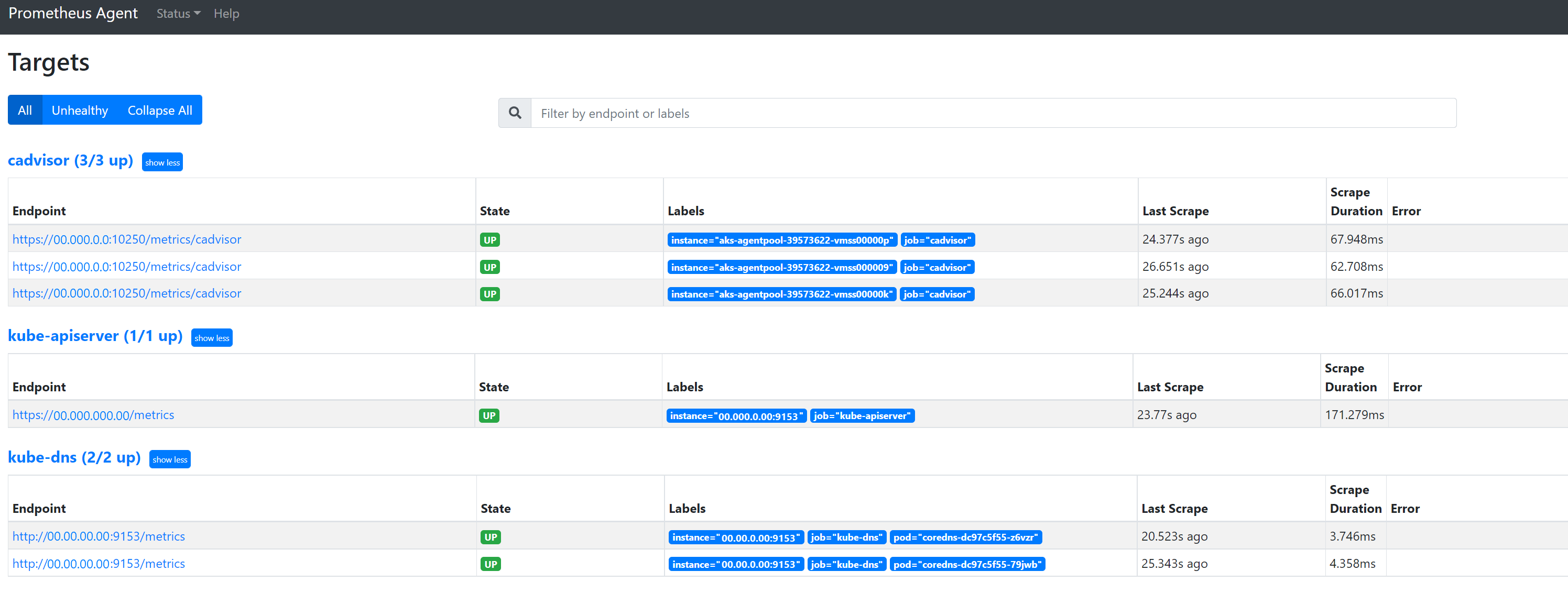



自訂資源
- 如果您確實包含了自訂資源,請確定它們顯示在設定、服務探索和目標下。
組態

服務探索

目標

如果沒有問題,並且正在抓取預定的目標,則您可以啟用偵錯模式來檢視所抓取的確切計量。
偵錯模式
警告
此模式可能會影響效能,而且只應該短時間啟用以進行偵錯。
您可以遵循這裡的指示,將 debug-mode 下的 configmap 設定 enabled 變更為 true,來設定以偵錯模式執行計量附加元件。
啟用時,所有抓取的 Prometheus 計量都會裝載於連接埠 9091。 執行以下命令:
kubectl port-forward <ama-metrics pod name> -n kube-system 9091
在瀏覽器中移至 127.0.0.1:9091/metrics,以查看 OpenTelemetry 收集器是否已抓取計量。 每個 ama-metrics-* Pod 都可存取此使用者介面。 如果沒有計量,則可能是計量或標籤名稱長度或標籤數目發生問題。 另也檢查是否超過本文所指定 Prometheus 計量的擷取配額。
計量名稱、標籤名稱和標籤值
計量抓取目前具有下表中的限制:
| 屬性 | 限制 |
|---|---|
| 標籤名稱長度 | 小於或等於 511 個字元。 工作中的任何時間序列超過此限制時,整個抓取工作將會失敗,而且將會在擷取之前從該工作中卸除計量。 您可以看到該工作的 up=0,而目標 Ux 將會顯示 up=0 的原因。 |
| 標籤值長度 | 小於或等於 1023 個字元。 工作中的任何時間序列超過此限制時,整個抓取將會失敗,而且將會在擷取之前從該工作中卸除計量。 您可以看到該工作的 up=0,而目標 Ux 將會顯示 up=0 的原因。 |
| 每個時間序列的標籤數目 | 小於或等於 63。 工作中的任何時間序列超過此限制時,整個抓取工作將會失敗,而且將會在擷取之前從該工作中卸除計量。 您可以看到該工作的 up=0,而目標 Ux 將會顯示 up=0 的原因。 |
| 度量名稱長度 | 小於或等於 511 個字元。 工作中的任何時間序列超過此限制時,只會卸除該特定系列。 MetricextensionConsoleDebugLog 有已卸除計量的追蹤。 |
| 大小寫不同的標籤名稱 | 相同計量範例內的兩個標籤大小寫不同,視為有重複標籤並在擷取時卸除。 例如,由 ExampleLabel 和 examplelabel 視為相同標籤名稱,因此時間序列 my_metric{ExampleLabel="label_value_0", examplelabel="label_value_1} 會因重複標籤而卸除。 |
檢查 Azure 監視器工作區上的擷取配額
如果您看到計量遺失,可以先檢查看看是否已超過 Azure 監視器工作區的擷取限制。 在 Azure 入口網站中,您可以檢查任何 Azure 監視器工作區的目前使用量。 您可以在 Azure 監視器工作區的 Metrics 功能表下查看目前的使用計量。 下列使用率計量可作為每個 Azure 監視器工作區的標準計量。
- 使用中時間序列 - 過去 12 小時內最近擷取至工作區的唯一時間序列數目
- 使用中時間序列限制 - 可主動擷取至工作區的唯一時間序列數目限制
- 使用中時間序列使用率 % - 目前正在使用的使用中時間序列的百分比
- 每分鐘擷取的事件數 - 最近收到的每分鐘事件數 (範例)
- 每分鐘擷取的事件數限制 - 進行節流前每分鐘可擷取的事件數目上限
- 每分鐘擷取的事件使用率 % - 目前正在使用的計量擷取速率限制百分比
若要避免計量擷取節流,您可以監視和設定對擷取限制的警示。 請參閱監視擷取限制。
請參閱服務配額和限制以瞭解預設配額,以及根據您的使用量可以增加哪些計量。 您可以使用 Azure 監視器工作區的 Support Request 功能表,要求增加 Azure 監視器工作區配額。 請確定您在支援要求中包含 Azure 監視器工作區的識別碼、內部識別碼和位置/區域,您可以在 Azure 入口網站 中 Azure 監視器工作區的 [屬性] 選單中找到。
因 Azure 原則評估而導致建立 Azure 監視器工作區失敗
如果建立 Azure 監視器工作區失敗並出現「原則不允許資源 'resource-name-xyz'」的錯誤,則可能存在阻止建立資源的 Azure 原則。 如果有原則會針對 Azure 資源或資源群組強制執行命名慣例,您必須為建立 Azure 監視器工作區的命名慣例建立豁免。
當您建立 Azure 監視器工作區時,預設會在資源群組 (格式為 "MA_azure-monitor-workspace-name_location_managed") 中自動建立資料收集規則和資料收集端點 (格式為 "azure-monitor-workspace-name")。 目前無法變更這些資源的名稱,您必須在 Azure 原則 上設定豁免,以免除上述資源不受原則評估的影響。 請參閱 Azure 原則豁免結構。