Kubernetes 叢集的建議警示規則
Azure 監視器中的警示會主動識別與 Azure 資源的健康情況和效能有關的問題。 本文說明如何啟用及編輯一組為您的 Kubernetes 叢集預先定義的建議計量警示規則。
啟用建議的警示規則
使用下列其中一種方法,為您的叢集啟用建議的警示規則。 您可以為相同的叢集同時啟用 Prometheus 和平台計量警示規則。
注意
ARM 範本是唯一支援在已啟用 Arc 的 Kubernetes 叢集上啟用建議警示的方法。
使用 Azure 入口網站時,將會在與叢集相同的區域中建立 Prometheus 規則群組。
從叢集的 [警示] 功能表中,選取 [設定建議]。
![AKS 叢集的螢幕擷取畫面,其中顯示 [設定建議] 按鈕。](media/kubernetes-metric-alerts/setup-recommendations.png)
可用的 Prometheus 和平台警示規則會一起顯示,且會按 Pod、叢集和節點層級來彙整 Prometheus 規則。 您可以切換 Prometheus 規則群組,以啟用該組規則。 展開群組可查看個別規則。 您可以保留預設值或停用個別規則,以及編輯其名稱和嚴重性。
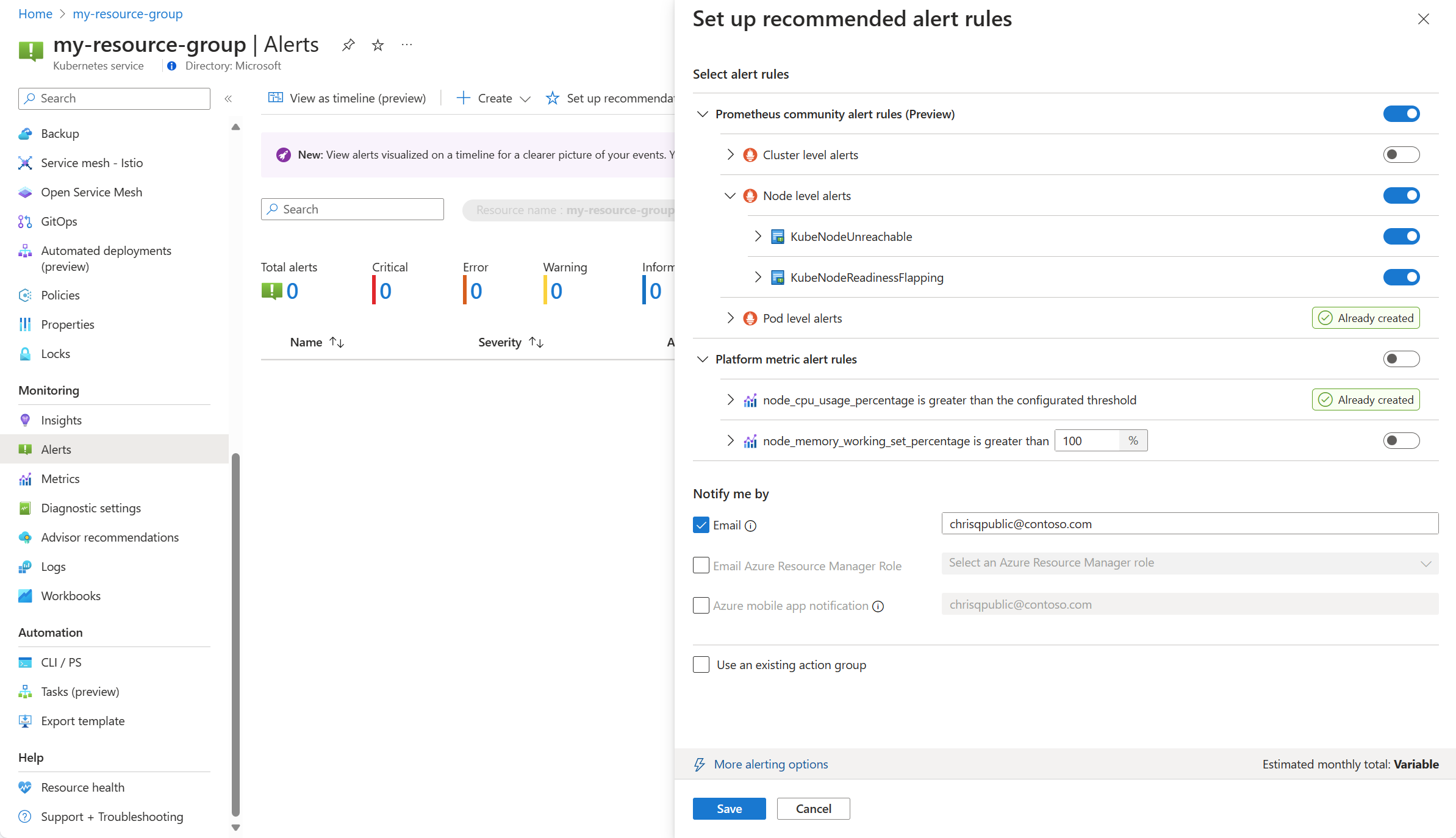
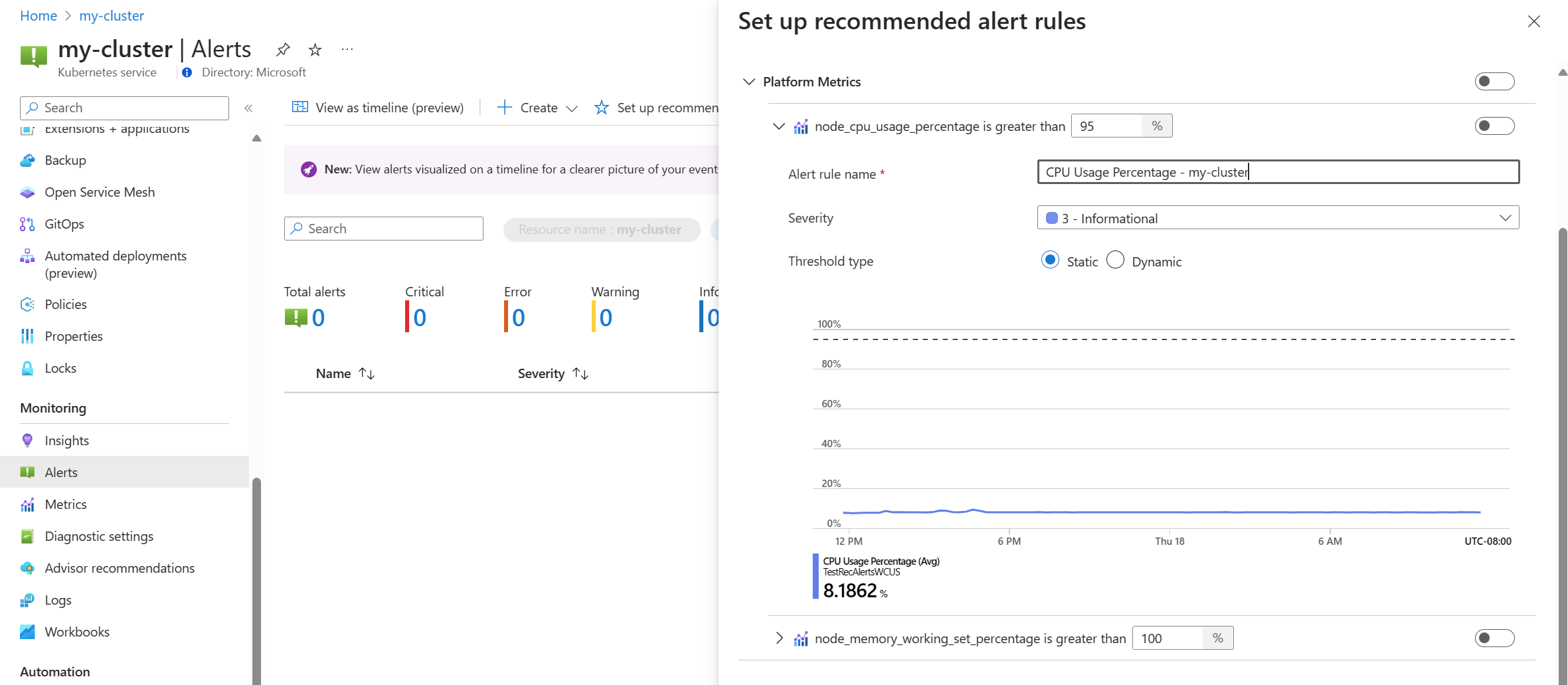
切換某個平台計量規則,可啟用該規則。 您可以展開規則以修改其詳細資料,例如名稱、嚴重性和閾值。
選取一或多個通知方法以建立新的動作群組,或選取具有這組警示規則的通知詳細資料的現有動作群組。
按一下 [儲存] 以儲存規則群組。
![AKS 叢集的螢幕擷取畫面,其中顯示 [設定建議] 按鈕。](media/kubernetes-metric-alerts/setup-recommendations.png#lightbox)


編輯建議的警示規則
規則群組建立後,您無法在入口網站中使用相同頁面來編輯規則。 對於 Prometheus 計量,您必須編輯規則群組才能修改其中的任何規則,包括啟用任何尚未啟用的規則。 對於平台計量,您可以編輯每個警示規則。



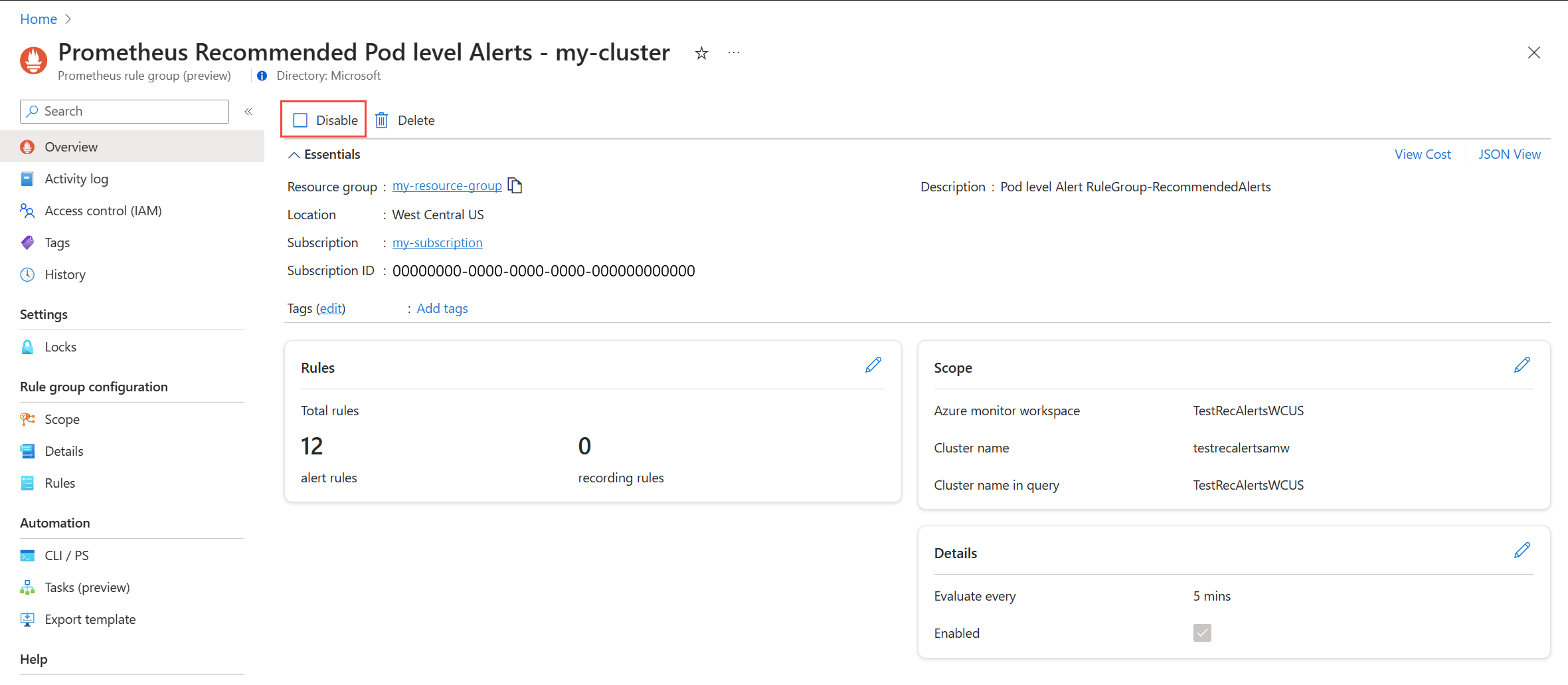
停用警示規則群組
停用規則群組,會停止接收群組中所含規則的警示。
檢視 Prometheus 警示規則群組或平台計量警示規則,如編輯建議的警示規則中所述。
從 [概觀] 功能表中,選取 [停用]。

建議的警示規則詳細資料
下表列出每個建議警示規則的詳細資料。 GitHub 中提供了每個規則的原始程式碼,以及來自 Prometheus 社群的疑難排解指南。
Prometheus 社群警示規則
叢集層級警示
| 警示名稱 | 描述 | 預設閾值 | 時間範圍 (分鐘) |
|---|---|---|---|
| KubeCPUQuotaOvercommit | 在過去 5 分鐘內,配置給命名空間的 CPU 資源配額超過叢集節點上可用的 CPU 資源 50% 以上。 | >1.5 | 5 |
| KubeMemoryQuotaOvercommit | 在過去 5 分鐘內,配置給命名空間的記憶體資源配額超過叢集節點上可用的記憶體資源 50% 以上。 | >1.5 | 5 |
| KubeContainerOOMKilledCount | 在過去 5 分鐘內,Pod 內的一或多個容器因記憶體不足 (OOM) 事件而遭到終止。 | >0 | 5 |
| KubeClientErrors | 在過去 15 分鐘內,Kubernetes API 要求中的用戶端錯誤率 (以 5xx 開頭 HTTP 狀態碼) 超過 API 總要求率的 1%。 | >0.01 | 15 |
| KubePersistentVolumeFillingUp | 根據可用空間比率、已使用的空間,以及可用空間過去 6 小時的預測線性趨勢來評估,永續性磁碟區即將滿溢,且預計可用空間將會用盡。 這些條件是在過去 60 分鐘內評估的。 | N/A | 60 |
| KubePersistentVolumeInodesFillingUp | 在過去 15 分鐘內,永續性磁碟區內可用的 Inode 少於 3%。 | <0.03 | 15 |
| KubePersistentVolumeErrors | 在過去 5 分鐘內,有一或多個永續性磁碟區處於失敗或擱置階段。 | >0 | 5 |
| KubeContainerWaiting | 在過去 60 分鐘內,Kubernetes Pod 內有一或多個容器處於等候狀態。 | >0 | 60 |
| KubeDaemonSetNotScheduled | 在過去 15 分鐘內,有一或多個 Pod 未排程於任何節點上。 | >0 | 15 |
| KubeDaemonSetMisScheduled | 在過去 15 分鐘內,有一或多個 Pod 錯誤地排程於叢集中。 | >0 | 15 |
| KubeQuotaAlmostFull | 在過去 15 分鐘內,Kubernetes 資源配額的使用率達到硬性限制的 90% 到 100% 之間。 | >0.9 <1 | 15 |
節點層級警示
| 警示名稱 | 描述 | 預設閾值 | 時間範圍 (分鐘) |
|---|---|---|---|
| KubeNodeUnreachable | 在過去 15 分鐘內,節點無法連線。 | 1 | 15 |
| KubeNodeReadinessFlapping | 在過去 15 分鐘內,節點的整備狀態變更了 2 次以上。 | 2 | 15 |
Pod 層級警示
| 警示名稱 | 描述 | 預設閾值 | 時間範圍 (分鐘) |
|---|---|---|---|
| KubePVUsageHigh | 在過去 15 分鐘內,Pod 上的永續性磁碟區 (PV) 平均使用量超過 80%。 | >0.8 | 15 |
| KubeDeploymentReplicasMismatch | 在過去 10 分鐘內,所需的複本數目與可用的複本數目不相符。 | N/A | 10 |
| KubeStatefulSetReplicasMismatch | 在過去 15 分鐘內,StatefulSet 中就緒的複本數目與 StatefulSet 中的複本總數不相符。 | N/A | 15 |
| KubeHpaReplicasMismatch | 在過去 15 分鐘內,叢集中的水平 Pod 自動調整程式與所需的複本數目不相符。 | N/A | 15 |
| KubeHpaMaxedOut | 在過去 15 分鐘內,叢集中的水平 Pod 自動調整程式 (HPA) 均以最大複本數執行。 | N/A | 15 |
| KubePodCrashLooping | 在過去 15 分鐘內,有一或多個 Pod 處於 CrashLoopBackOff 狀況,Pod 持續在啟動後當機,且無法成功復原。 | >=1 | 15 |
| KubeJobStale | 在過去 6 小時內,至少有一個作業執行個體未順利完成。 | >0 | 360 |
| KubePodContainerRestart | 在過去一小時內,Kubernetes 叢集中的 Pod 內有一或多個容器至少重新啟動了一次。 | >0 | 15 |
| KubePodReadyStateLow | 在過去 5 分鐘內,Kubernetes 叢集中任何部署或 DaemonSet 處於就緒狀態的 Pod 百分比低於 80%。 | <0.8 | 5 |
| KubePodFailedState | 在過去 5 分鐘內,有一或多個 Pod 處於失敗狀態。 | >0 | 5 |
| KubePodNotReadyByController | 在過去 15 分鐘內,有一或多個 Pod 未處於就緒狀態 (亦即處於「擱置」或「未知」階段)。 | >0 | 15 |
| KubeStatefulSetGenerationMismatch | 在過去 15 分鐘內,觀察到的 Kubernetes StatefulSet 產生與其中繼資料產生不相符。 | N/A | 15 |
| KubeJobFailed | 在過去 15 分鐘內,有一或多個 Kubernetes 作業失敗。 | >0 | 15 |
| KubeContainerAverageCPUHigh | 在過去 5 分鐘內,每個容器的平均 CPU 使用率超過 95%。 | >0.95 | 5 |
| KubeContainerAverageMemoryHigh | 在過去 5 分鐘內,每個容器的平均記憶體使用量超過 95%。 | >0.95 | 10 |
| KubeletPodStartUpLatencyHigh | 在過去 10 分鐘內,Pod 啟動延遲的第 99 個百分位數超過 60 秒。 | >60 | 10 |
平台計量警示規則
| 警示名稱 | 描述 | 預設閾值 | 時間範圍 (分鐘) |
|---|---|---|---|
| 節點 CPU 百分比大於 95% | 在過去 5 分鐘內,節點 CPU 百分比大於 95%。 | 95 | 5 |
| 節點記憶體工作集百分比大於 100% | 在過去 5 分鐘內,節點記憶體工作集百分比大於 100%。 | 100 | 5 |
舊版容器深入解析計量警示 (預覽)
容器深入解析中的計量規則已於 2024 年 5 月 31 日淘汰。 這些規則處於公開預覽狀態,但日後將逕行淘汰而不正式發行,因為現已推出本文所述的新建議計量警示。
如果您已啟用這些舊版警示規則,您應加以停用,並啟用新的體驗。
停用計量警示規則
- 在叢集的 [深入解析] 功能表中,選取 [建議的警示 (預覽)]。
- 將每個警示規則的狀態變更為 [已停用]。
舊版警示對應
下表會將每個舊版容器深入解析計量警示對應至其對等的建議 Prometheus 計量警示。
| 自訂計量建議警示 | 對等的 Prometheus/平台計量建議警示 | Condition |
|---|---|---|
| 已完成的作業計數 | KubeJobStale (Pod 層級警示) | 在過去 6 小時內,至少有一個作業執行個體未順利完成。 |
| 容器 CPU % | KubeContainerAverageCPUHigh (Pod 層級警示) | 在過去 5 分鐘內,每個容器的平均 CPU 使用率超過 95%。 |
| 容器工作集記憶體 % | KubeContainerAverageMemoryHigh (Pod 層級警示) | 在過去 5 分鐘內,每個容器的平均記憶體使用量超過 95%。 |
| 失敗的 Pod 計數 | KubePodFailedState (Pod 層級警示) | 在過去 5 分鐘內,有一或多個 Pod 處於失敗狀態。 |
| 節點 CPU % | 節點 CPU 百分比大於 95% (平台計量) | 在過去 5 分鐘內,節點 CPU 百分比大於 95%。 |
| 節點磁碟使用率 % | N/A | 節點的平均磁碟使用率大於 80%。 |
| 叢集 NotReady 狀態 | KubeNodeUnreachable (節點層級警示) | 在過去 15 分鐘內,節點無法連線。 |
| 節點工作集記憶體 % | 節點記憶體工作集百分比大於 100% | 在過去 5 分鐘內,節點記憶體工作集百分比大於 100%。 |
| 因 OOM 而終止的容器 | KubeContainerOOMKilledCount (叢集層級警示) | 在過去 5 分鐘內,Pod 內的一或多個容器因記憶體不足 (OOM) 事件而遭到終止。 |
| 永續性磁碟區使用率 % | KubePVUsageHigh (Pod 層級警示) | 在過去 15 分鐘內,Pod 上的永續性磁碟區 (PV) 平均使用量超過 80%。 |
| Pod 就緒 % | KubePodReadyStateLow (Pod 層級警示) | 在過去 5 分鐘內,Kubernetes 叢集中任何部署或 DaemonSet 處於就緒狀態的 Pod 百分比低於 80%。 |
| 重新啟動的容器計數 | KubePodContainerRestart (Pod 層級警示) | 在過去一小時內,Kubernetes 叢集中的 Pod 內有一或多個容器至少重新啟動了一次。 |
舊版計量對應
下表會將每個舊版 Container insights 自定義計量對應至其相等的 Prometheus 計量。
| 自訂計量 | 對等 Prometheus 計量 |
|---|---|
| cpuUsageMillicores | rate(container_cpu_usage_seconds_total[5m]) * 1000 |
| cpuUsagePercentage | 100 * rate(container_cpu_usage_seconds_total{cluster=“$cluster”}[5m]) |
| cpuUsageAllocatablePercentage | 100 * (sum by (cluster) (node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate{cluster=“$cluster”}) / sum by (cluster) (instance:node_num_cpu:sum{cluster=“$cluster”}) ) |
| memoryRssByte | container_memory_rss{cluster=“$cluster”} |
| memoryRssPercentage | 100 * (sum by (instance, cluster) (container_memory_rss{job=“cadvisor”, cluster=“$cluster”}) / sum by (instance, cluster) (machine_memory_bytes{job=“cadvisor”, cluster=“$cluster”}) ) |
| memoryRssAllocatablePercentage | 100 * (加總 by (node, cluster) (container_memory_rss{cluster=“$cluster”}) / sum by (node, cluster) (node_memory_MemTotal_bytes{cluster=“$cluster”}) ) |
| memoryWorkingSetBytes | container_memory_working_set_bytes{cluster=“$cluster”} |
| memoryWorkingSetPercentage | 100 * (加總 by (node, cluster) (container_memory_working_set_bytes{cluster=“$cluster”}) / sum by (node, cluster) (node_memory_MemTotal_bytes{cluster=“$cluster”}) ) |
| nodesCount | count(kube_node_status_condition{condition=“Ready”, status=“true”, cluster=“$cluster”}) |
| diskUsedPercentage | 100 * (node_filesystem_size_bytes{cluster=“$cluster”} - node_filesystem_free_bytes{cluster=“$cluster”}) / node_filesystem_size_bytes{cluster=“$cluster”} |
| podCount | count(count by (pod, namespace, cluster) (kube_pod_info{cluster=“$cluster”})) |
| completedJobsCount | count(kube_job_status_succeeded{status=“true”, cluster=“$cluster”} and time() - kube_job_status_start_time > 6 * 3600) |
| restartingContainerCount | sum by(container, namespace, cluster) (rate(kube_pod_container_status_restarts_total{cluster=“$cluster”}[5m])) |
| oomKilledContainerCount | sum by(container, namespace, cluster) (kube_pod_container_status_terminated_reason{reason=“OOMKilled”, cluster=“$cluster”}) |
| podReadyPercentage | 100 * (sum(kube_pod_status_phase{phase=“Running”, cluster=“$cluster”}) by (namespace, cluster) / sum(kube_pod_status_phase{phase!=“Succeeded”, cluster=“$cluster”}) by (namespace, cluster)) |
下一步
- 閱讀 Azure 監視器中不同的警示規則類型的相關資訊。
- 閱讀適用於 Prometheus 的 Azure 監視器受管理服務中的警示規則群組的相關資訊。