教學課程:使用 Azure Cache for Redis 對 Azure OpenAI 內嵌執行向量相似度搜尋
在本教學課程中,您將逐步了解基本向量相似度使用案例。 您將使用 Azure OpenAI 服務所產生的內嵌和 Azure Cache for Redis Enterprise 層的內建向量搜尋功能,藉此查詢電影資料集以尋找最相關的比對。
本教學課程使用維基百科電影情節資料集,其中提供維基百科涵蓋 1901 年至 2017 年超過 35,000 部電影的情節說明。 資料集包含每部電影的情節摘要及中繼資料,例如電影發行年份、導演、主要演員和電影類型。 您將遵循教學課程的步驟,根據情節摘要來產生內嵌並使用其他中繼資料以執行混合式查詢。
在本教學課程中,您會了解如何:
- 建立向量搜尋設定的 Azure Cache for Redis 執行個體
- 安裝 Azure OpenAI 和其他必要 Python 程式庫。
- 下載電影資料集並準備進行分析。
- 使用 text-embedding-ada-002 (第 2 版本) 模型以產生內嵌。
- 在 Azure Cache for Redis 中建立向量索引
- 使用 餘弦相似度 來排名搜尋結果。
- 透過 RediSearch 使用混合式查詢功能以預先篩選資料,並增強向量搜尋。
重要
本教學課程將逐步引導您建立 Jupyter Notebook。 您可遵循本教學課程並使用 Python 程式碼檔案 (.py),取得相似結果,但您將必須將本教學課程中的所有程式碼區塊新增至 .py 檔案並執行一次以察看結果。 換句而言,Jupyter Notebook 會在執行儲存格時提供中繼結果,但這不是在使用 Python 程式碼檔案時應預期的行為。
重要
如果您要改為遵循完成的 Jupyter Notebook,請下載名為 tutorial.ipynb 的 Jupyter Notebook 檔案並將其儲存至 redis-vector 資料夾。
必要條件
- Azure 訂用帳戶 - 建立免費帳戶
- 在所需的 Azure 訂用帳戶中授與 Azure OpenAI 的存取權。目前,您必須申請 Azure OpenAI 的存取權。 您可以填妥 https://aka.ms/oai/access 的表單,以申請 Azure OpenAI 的存取權。
- Python 3.7.1 或更新版本
- Jupyter Notebooks (選擇性)
- 已部署 text-embedding-ada-002 (第 2 版) 模型的 Azure OpenAI 資源。 此模型目前僅適用於 特定區域。 如需如何部署模型的指示,請參閱資源部署指南。
建立 Azure Cache for Redis 執行個體
請遵循快速入門:建立 Redis Enterprise 快取指南。 在 [進階] 頁面上,確認您已新增 RediSearch 模組並選擇 Enterprise 叢集原則。 所有其他設定都可符合快速入門中所述的預設值。
需要幾分鐘的時間,才能建立快取。 您可以同時繼續下一個步驟。
![顯示已填入 [企業層基本] 索引標籤的螢幕擷取畫面。](media/cache-create/enterprise-tier-basics.png)
設定開發環境
在本機電腦的通常儲存專案的位置中建立名為 redis-vector 的資料夾。
在資料夾中建立新的 Python 檔案 (tutorial.py) 或 Jupyter Notebook (tutorial.ipynb)。
安裝必要 Python 套件:
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
下載資料集
在網頁瀏覽器中,巡覽至 https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plots。
登入或註冊 Kaggle。 必須註冊,才能下載檔案。
選取 Kaggle 上的 [下載] 連結以下載 archive.zip 檔案。
擷取 archive.zip 檔案並將 wiki_movie_plots_deduped.csv 移至 redis-vector 資料夾。
匯入程式庫並設定連線資訊
若要成功對 Azure OpenAI 進行呼叫,您需要端點和金鑰。 您也需要端點和金鑰,才能連線至 Azure Cache for Redis。
在 Azure 入口網站中前往 Azure OpenAI 資源。
在 [資源管理] 區段中找到 [端點和金鑰]。 複製您的端點和存取金鑰,因為您需要這兩者才能驗證 API 呼叫。 範例端點為:
https://docs-test-001.openai.azure.com。 您可以使用KEY1或KEY2。在 Azure 入口網站中,移至 Azure Cache for Redis 資源的 [概觀] 頁面。 複製您的端點。
在 [設定] 區段中,找到 [存取金鑰]。 複製您的存取金鑰。 您可以使用
Primary或Secondary。將下列程式碼新增至新的程式碼儲存格:
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"使用 Azure OpenAI 部署中的金鑰和端點值以更新
API_KEY和RESOURCE_ENDPOINT的值。 使用text-embedding-ada-002 (Version 2)內嵌模型,將DEPLOYMENT_NAME設定為部署的名稱,MODEL_NAME應是使用特定的內嵌模型。使用 Azure Cache for Redis 執行個體中的端點和金鑰值以更新
REDIS_ENDPOINT和REDIS_PASSWORD。重要
強烈建議使用環境變數或祕密管理員 (例如 Azure Key Vault) 以傳入 API 金鑰、端點和部署名稱資訊。 為了簡單起見,會以純文字在此設定這些變數。
執行程式碼儲存格 2。
將資料集匯入至 pandas 並處理資料
接下來,您會將 CSV 檔案讀取至 pandas DataFrame。
將下列程式碼新增至新的程式碼儲存格:
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) df執行程式碼儲存格 3。 您應該會看見下列輸出:
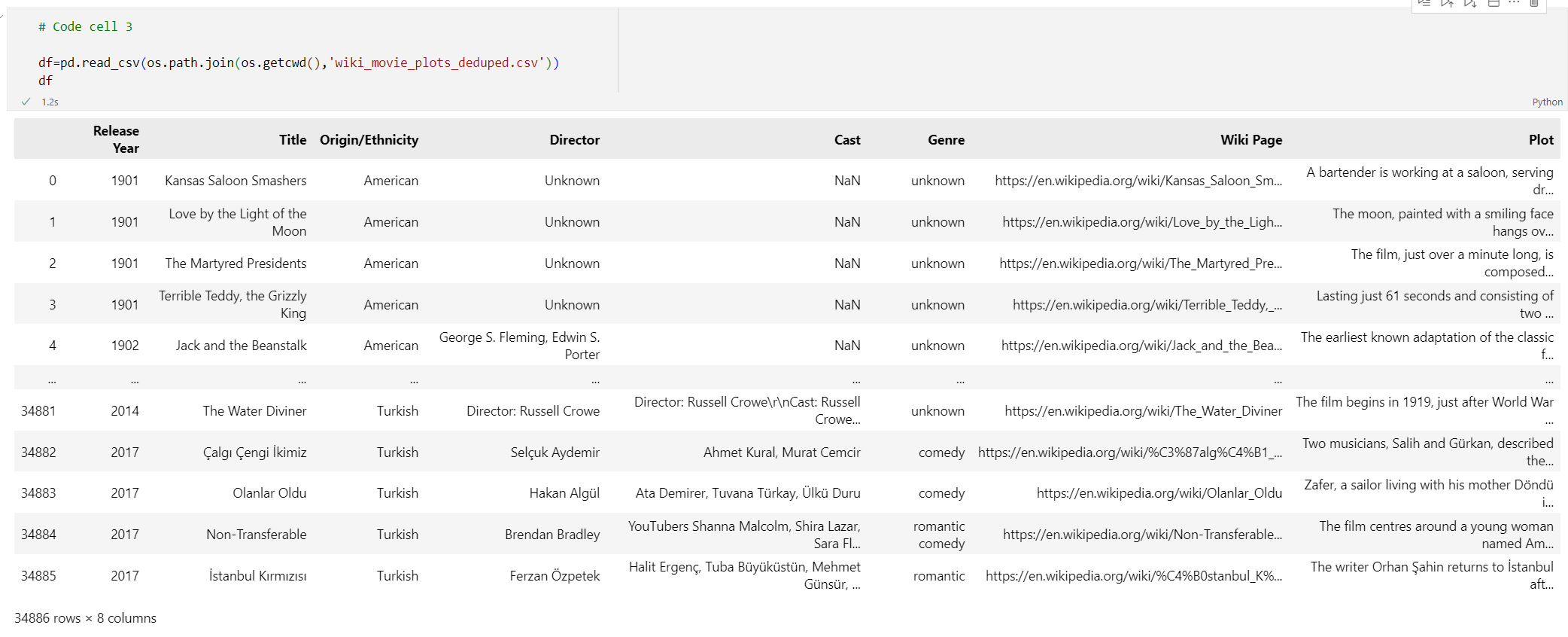
接下來,藉由新增
id索引、從數據行標題移除空格,以及篩選電影,只接受 1970 年之後和從英語國家/地區製作的電影來處理數據。 此篩選步驟可減少資料集中的電影數目,進而降低產生內嵌所需的成本和時間。 您可根據偏好設定自行變更或移除篩選參數。若要篩選資料,請將下列程式碼新增至新的程式碼儲存格:
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema df執行程式碼儲存格 4。 您應該會看見下列結果:
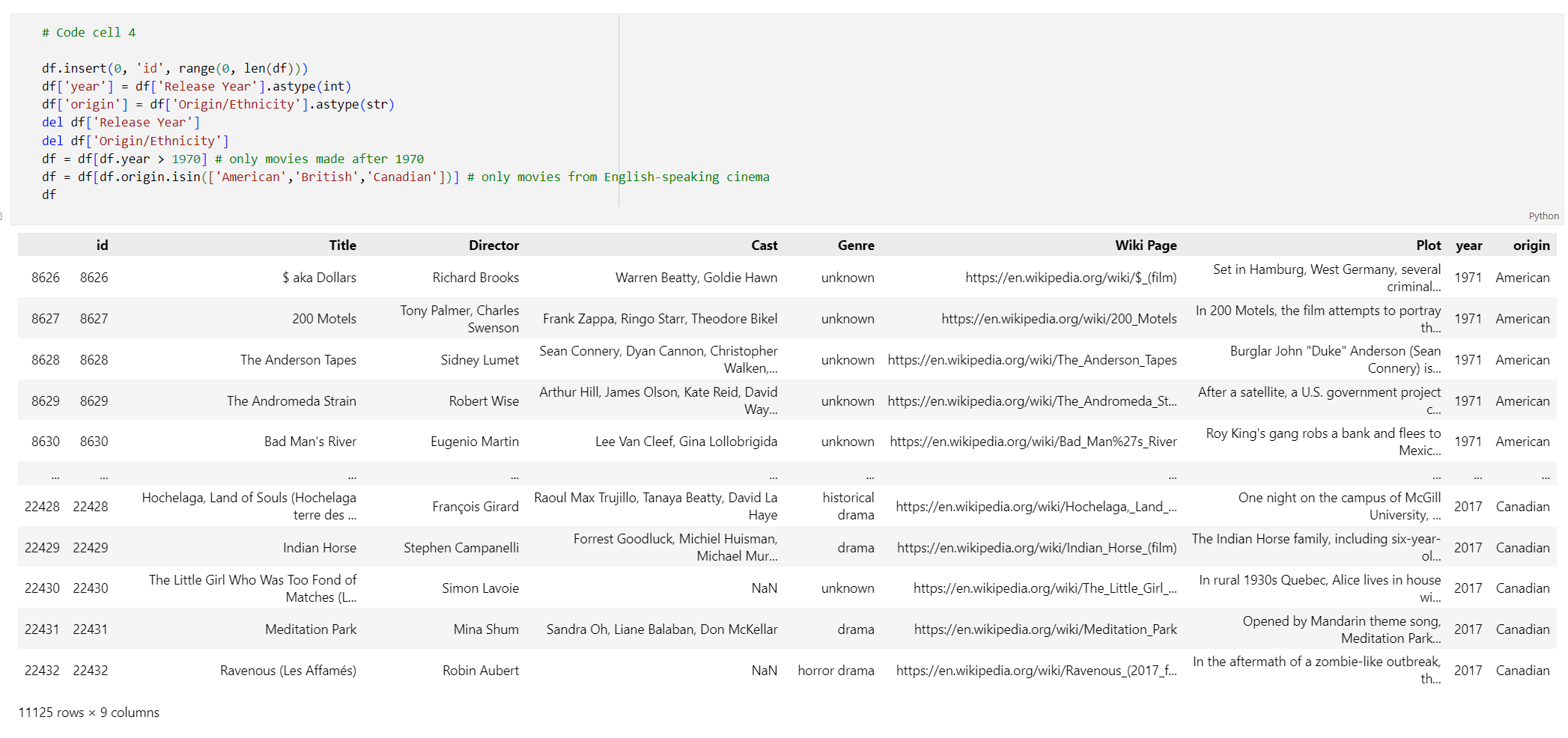
移除空白字元和標點符號來建立函式以清除資料,接著對包含情節的 Dataframe 使用。
將下列程式碼新增至新的程式碼儲存格並執行:
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))最後,移除對於內嵌模型過長的情節說明項目。 (換句而言,這些項目的權杖超過 8192 權杖限制。) 接下來,計算產生內嵌所需的權杖數目。 這也會影響內嵌產生的價格。
將下列程式碼新增至新的程式碼儲存格:
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))執行程式碼儲存格 6。 您應該會看見下列輸出:
Number of movies: 11125 Number of tokens required:7044844重要
請參閱 Azure OpenAI 服務定價,根據所需的令牌數目計算產生內嵌的成本。


將 DataFrame 載入至 LangChain
使用 DataFrameLoader 類別將 DataFrame 載入至 LangChain。 資料位於 LangChain 文件後,便可更輕鬆使用 LangChain 程式庫來產生內嵌並執行相似度搜尋。 將 Plot 設定為 page_content_column,以便可在此資料行上產生內嵌。
將下列程式碼新增至新的程式碼儲存格並執行:
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
產生內嵌並將其載入至 Redis
現在已篩選資料並載入至 LangChain,您將建立內嵌以便可查詢每個電影的情節。 下列程式碼會設定 Azure OpenAI、產生內嵌,並將內嵌向量載入至 Azure Cache for Redis。
將下列程式碼新增至新的程式碼儲存格:
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")執行程式碼儲存格 8。 這項作業可能需要超過 30 分鐘的時間來完成。 也會產生
redis_schema.yaml檔案。 若要連線至 Azure Cache for Redis 執行個體中的索引而不需要重新產生內嵌,此檔案可提供幫助。
重要
產生內嵌的速度取決於 Azure OpenAI 模型可用的配額。 若配額為每分鐘 240k 權杖,則將需要大約 30 分鐘的時間處理資料集中的 7M 權杖。
執行向量搜尋查詢
現在已設定資料集、Azure OpenAI 服務 API 和 Redis 執行個體,您可使用向量進行搜尋。 在此範例中,會傳回指定查詢的前 10 個結果。
將下列程式碼新增至 Python 程式碼檔案:
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')執行程式碼儲存格 9。 您應該會看見下列輸出:
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)相似度分數及按相似度的電影序數排名將一併傳回。 請注意,更多特定查詢有相似度分數,在清單中下降也會更快。
混合式查詢
由於 RediSearch 也提供向量搜尋以外的豐富搜尋功能,因此可按資料集中的中繼資料 (例如電影類型、角色、發行年份或導演) 來篩選結果。 在此案例中,根據類型
comedy進行篩選。將下列程式碼新增至新的程式碼儲存格:
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')執行程式碼儲存格 10。 您應該會看見下列輸出:
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
透過 Azure Cache for Redis 和 Azure OpenAI 服務,您可使用內嵌和向量搜尋以將強大搜尋功能新增至您的應用程式。
清除資源
如果您想要繼續使用在本文中建立的資源,請保留該資源群組。
否則,若已完成資源使用,則可刪除您建立的 Azure 資源群組,以避免衍生費用。
重要
刪除資源群組是無法回復的動作。 當您刪除資源群組時,其中包含的所有資源都將永久刪除。 請確定您不會不小心刪除錯誤的資源群組或資源。 如果您是在包含需保留資源的現有資源群組內部建立資源,則可以個別刪除每個資源,而不必刪除整個資源群組。
刪除資源群組
登入 Azure 入口網站,然後選取 [資源群組]。
選取您想要刪除的資源群組。
如果有許多資源群組,請使用 [篩選任何欄位] 方塊,並輸入您針對本文所建立資源群組的名稱。 選取結果清單中的資源群組。
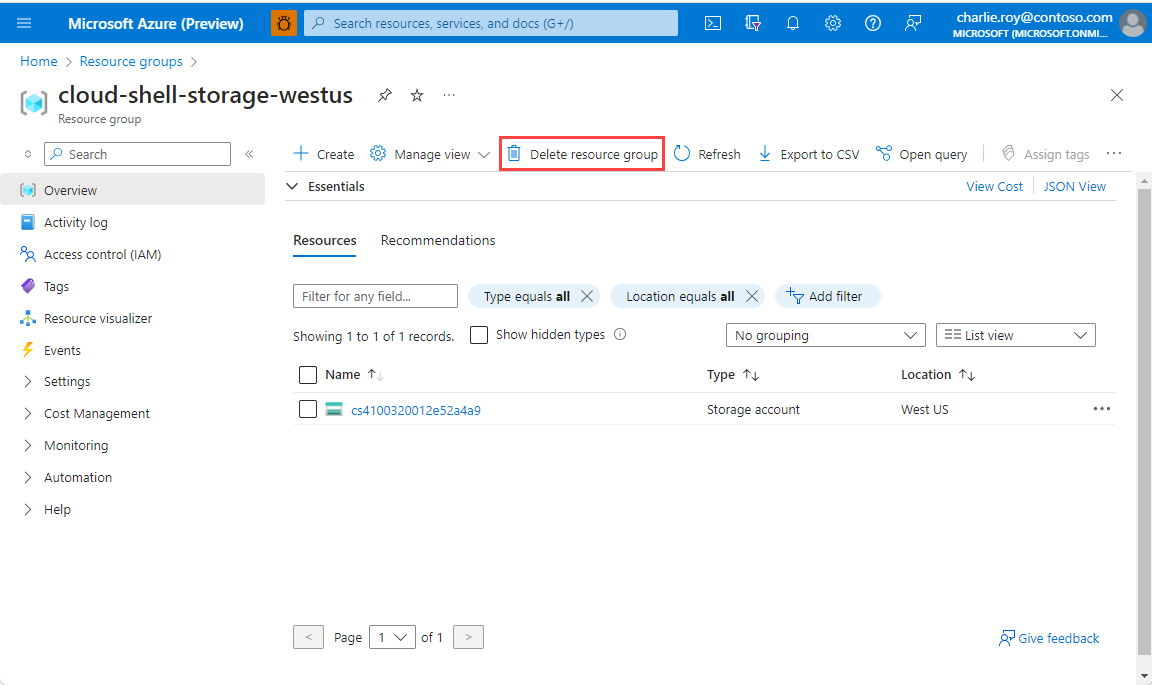
選取 [刪除資源群組]。
系統將會要求您確認是否刪除資源群組。 輸入您的資源群組名稱以進行確認,然後選取 [刪除]。
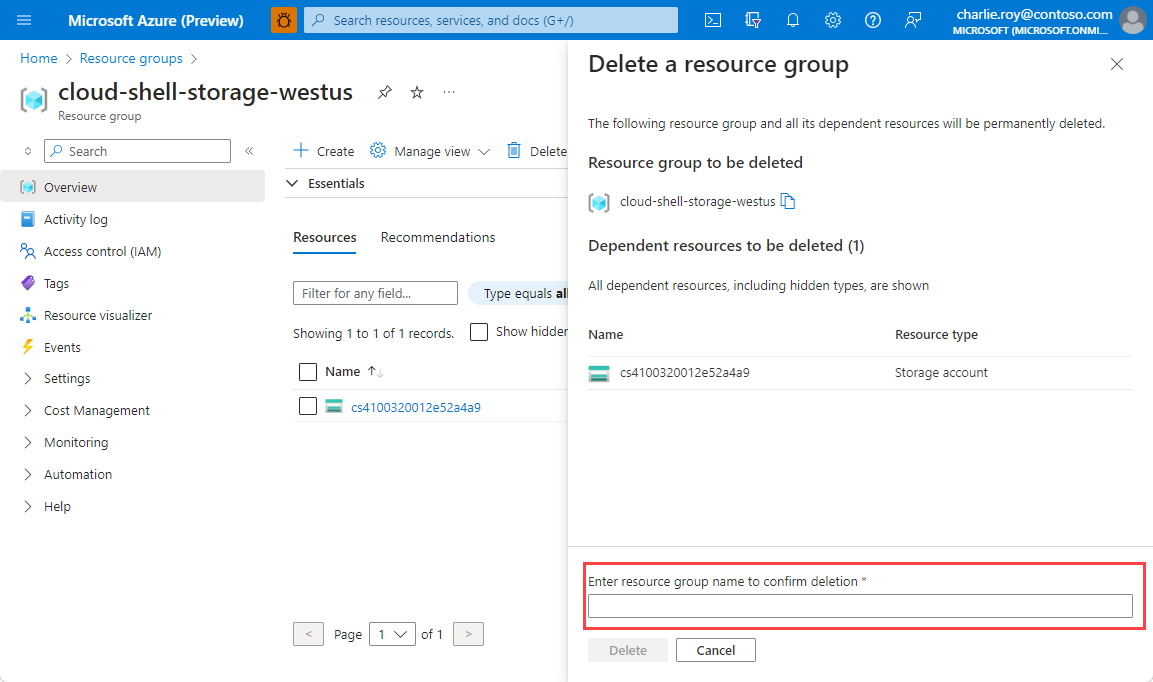
不久後,系統便會刪除該資源群組及其所有的資源。
相關內容
- 深入了解 Azure Cache for Redis
- 深入了解 Azure Cache for Redis 向量搜尋功能
- 深入了解 Azure OpenAI 服務產生的內嵌
- 深入了解餘弦相似度
- 了解如何使用 OpenAI 和 Redis 建立 AI 支援的應用程式
- 建立具有語意答案的 Q&A 應用程式