本文說明開發小組如何使用計量來尋找瓶頸,並改善分散式系統的效能。 本文是以我們針對範例應用程式所做的實際負載測試為基礎。 應用程式來自微服務Azure Kubernetes Service (AKS) 基準。
本文是系列文章的其中一篇。 請 在這裡閱讀第一個部分。
案例:用戶端應用程式會起始涉及多個步驟的商務交易。
此案例牽涉到在 AKS 上執行的無人機遞送應用程式。 客戶會使用 Web 應用程式來排程無人機的遞送。 每個交易都需要由後端上的個別微服務執行的多個步驟:
- 傳遞服務會管理傳遞。
- 無人機排程器服務會排程無人機進行取貨。
- 封裝服務會管理封裝。
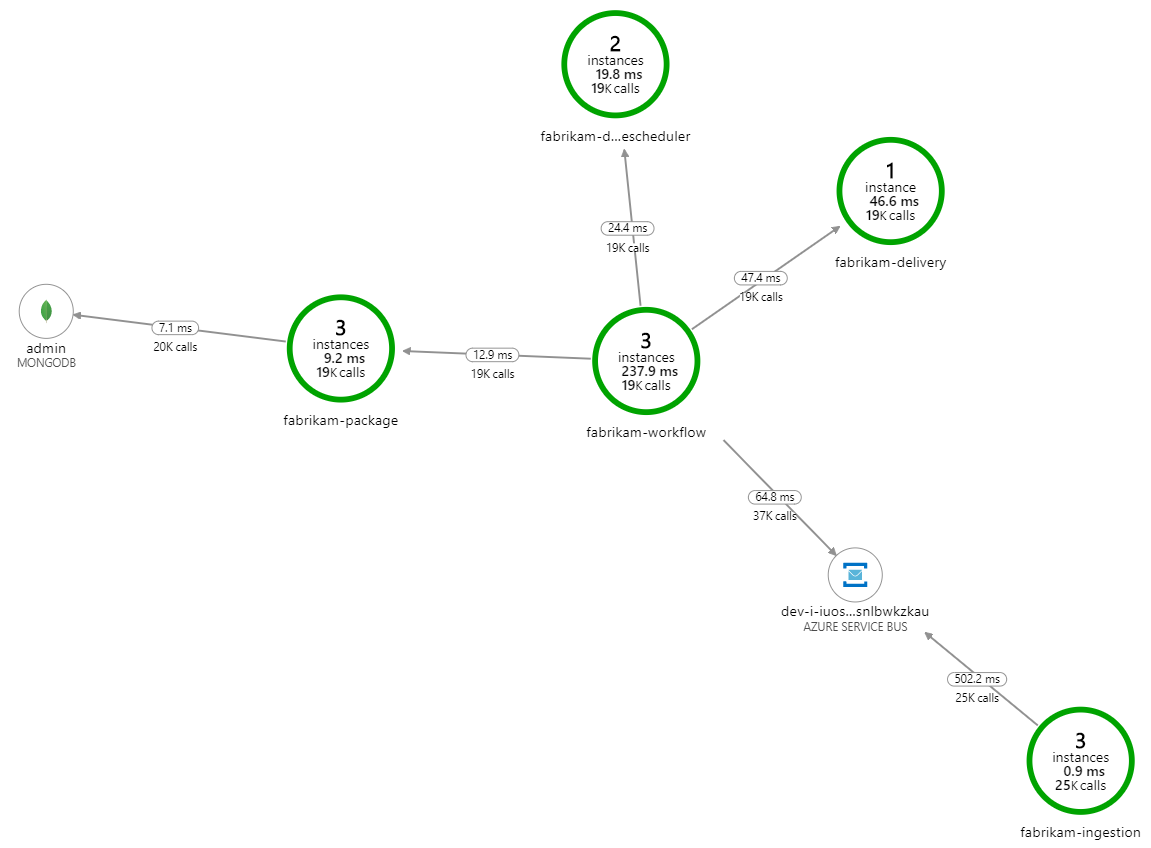
還有其他兩項服務:擷取服務可接受用戶端要求,並將它們放在佇列進行處理,以及協調工作流程中步驟的工作流程服務。
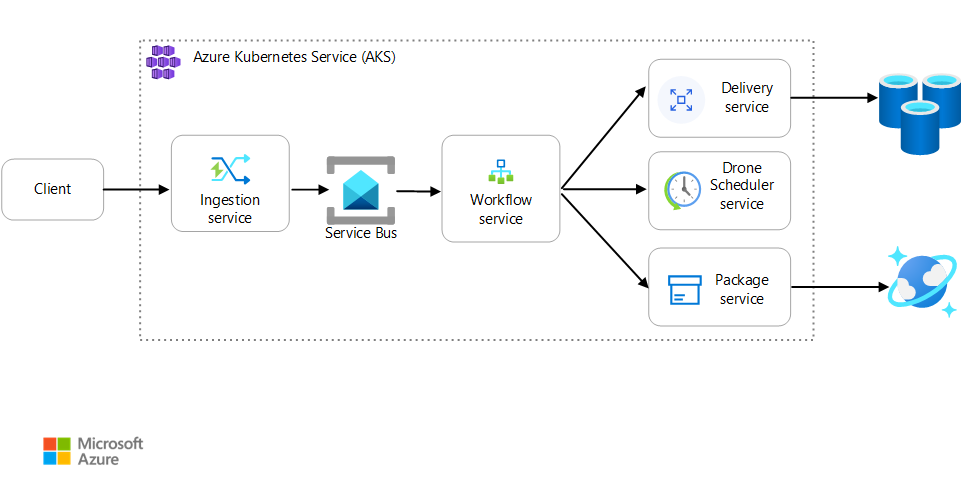
如需此案例的詳細資訊,請參閱 設計微服務架構。
測試 1:基準
針對第一個負載測試,小組建立了六個節點的 AKS 叢集,並部署每個微服務的三個複本。 負載測試是一項步驟負載測試,從兩個模擬使用者開始,最多增加 40 個模擬使用者。
| 設定 | 值 |
|---|---|
| 叢集節點 | 6 |
| Pod | 每個服務 3 個 |
下圖顯示負載測試的結果,如 Visual Studio 所示。 紫色線條繪製使用者載入,而橙色線條繪製總要求。
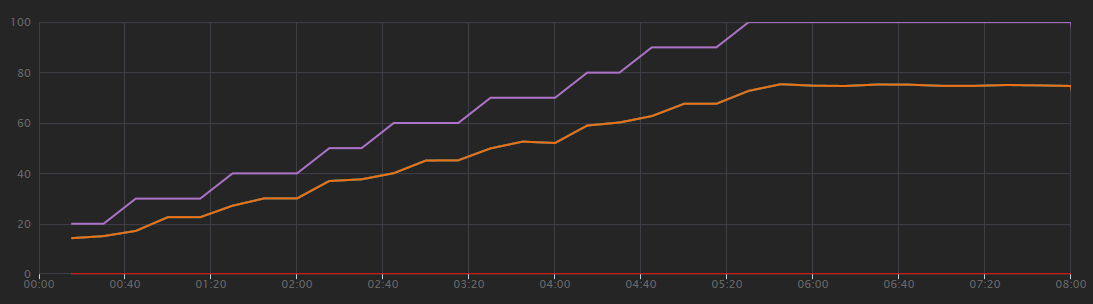
瞭解此案例的第一件事是每秒用戶端要求不是實用的效能計量。 這是因為應用程式會以非同步方式處理要求,因此用戶端會立即取得回應。 回應碼一律為 HTTP 202 (已接受) ,這表示已接受要求,但處理未完成。
我們真正想要知道的是後端是否跟上要求速率。 服務匯流排佇列可以吸收尖峰,但如果後端無法處理持續負載,處理將會進一步和進一步落後。
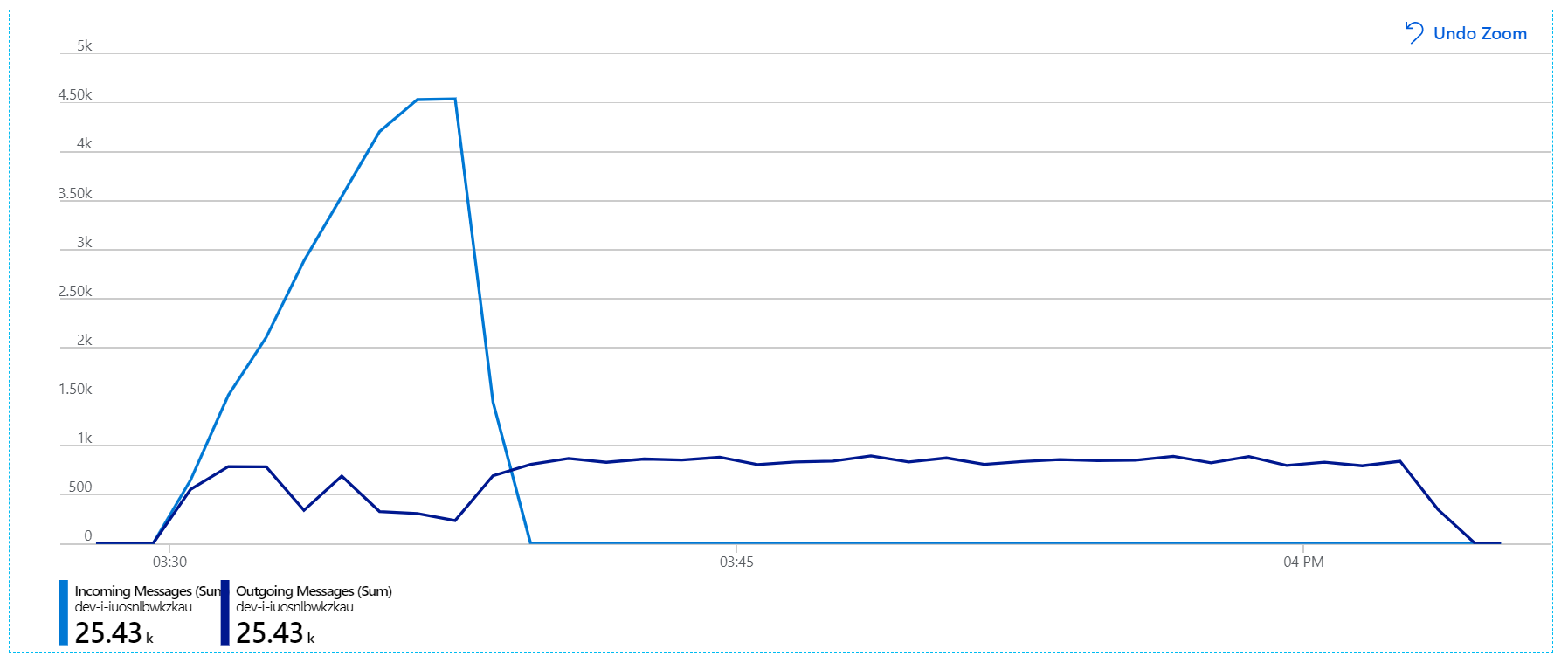
以下是更具資訊性的圖表。 它會繪製服務匯流排佇列上的傳入和傳出訊息數目。 傳入訊息會以淺藍色顯示,而傳出訊息則會以深藍色顯示:
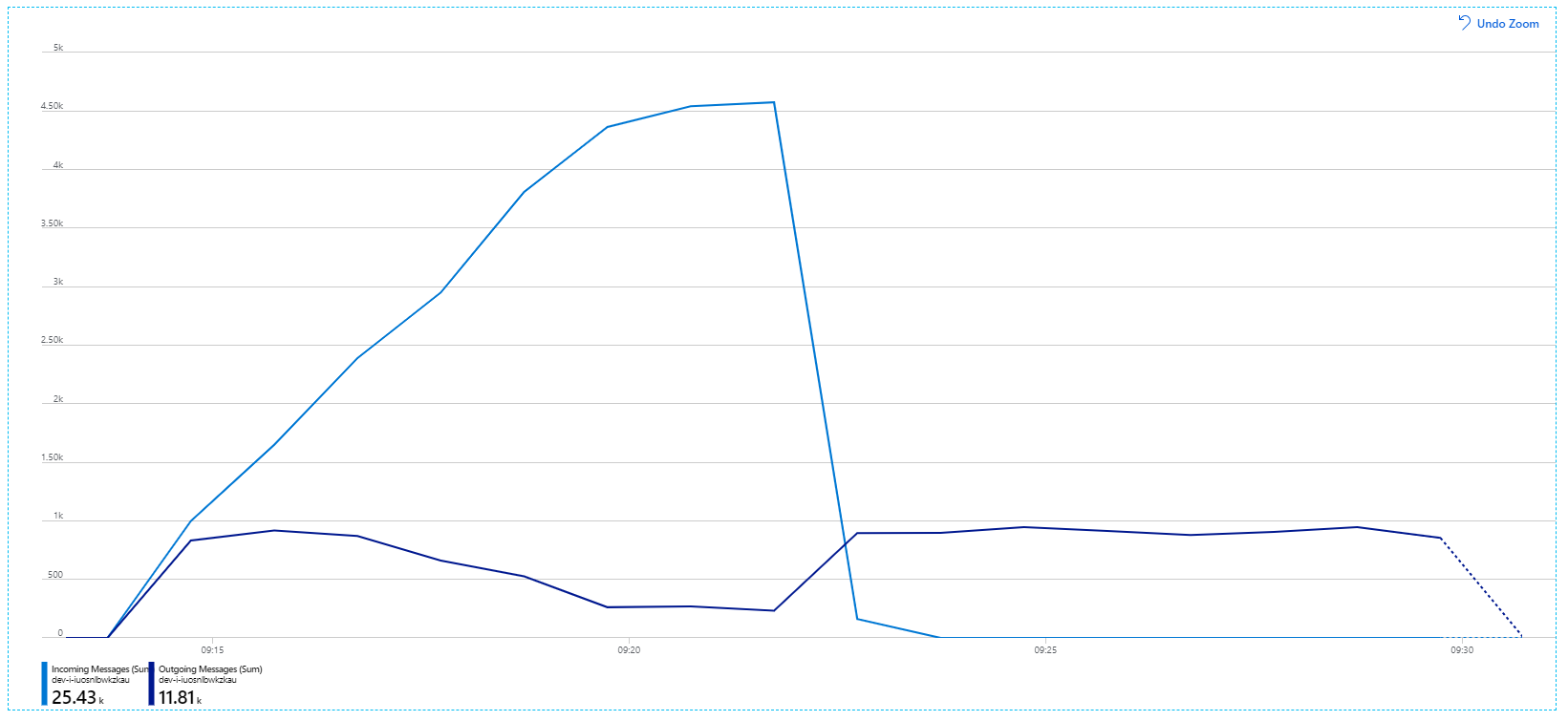
此圖表顯示傳入訊息的速率增加、到達尖峰,然後在負載測試結束時回復為零。 但傳出訊息的數目會提早在測試中尖峰,然後實際下降。 這表示無法跟上處理要求的工作流程服務。 即使負載測試在圖形上結束 (大約 9:22) ,工作流程服務仍會處理訊息,因為工作流程服務會繼續清空佇列。
處理速度變慢了什麼? 要尋找的第一件事是可能表示系統問題的錯誤或例外狀況。 Azure 監視器中的 應用程式對應 會顯示元件之間的呼叫圖表,而且是找出問題的快速方式,然後按一下以取得更多詳細資料。
確定應用程式對應顯示工作流程服務從傳遞服務收到錯誤:
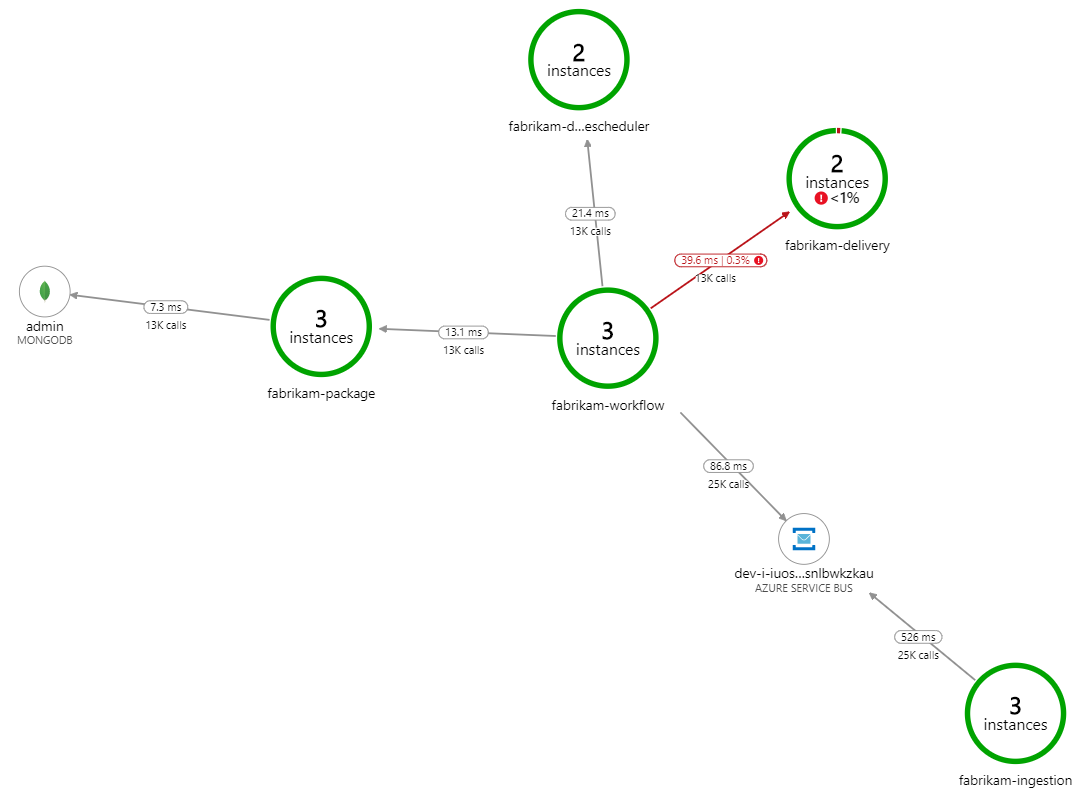
若要查看更多詳細資料,您可以在圖形中選取節點,然後按一下端對端交易檢視。 在此情況下,它會顯示傳遞服務正在傳回 HTTP 500 錯誤。 錯誤訊息表示因為記憶體限制Azure Cache for Redis而擲回例外狀況。
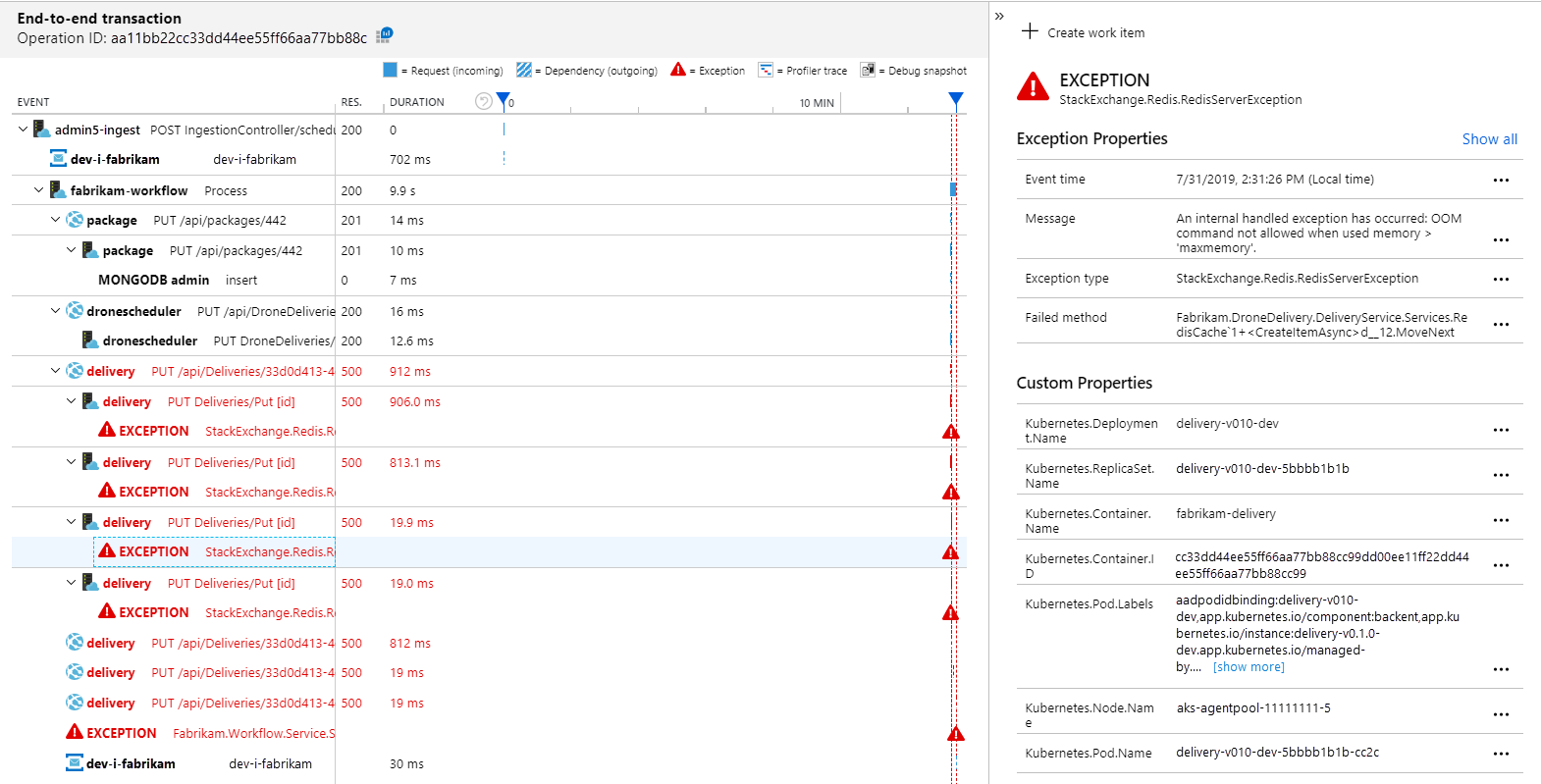
您可能會注意到這些 Redis 呼叫不會出現在應用程式對應中。 這是因為 Application Insights 的 .NET 程式庫沒有內建支援將 Redis 追蹤為相依性。 (如需現成支援的清單,請參閱 相依性自動收集。) 作為後援,您可以使用 TrackDependency API 來追蹤任何相依性。 負載測試通常會在遙測中顯示這些類型的間距,可以加以補救。
測試 2:增加快取大小
針對第二個負載測試,開發小組會以 Azure Cache for Redis 增加快取大小。 (請參閱如何調整 Azure Cache for Redis.) 這項變更已解決記憶體不足例外狀況,而應用程式對應現在會顯示零錯誤:
不過,處理訊息仍有顯著的延遲。 在負載測試的尖峰,傳入訊息速率超過 5×傳出速率:
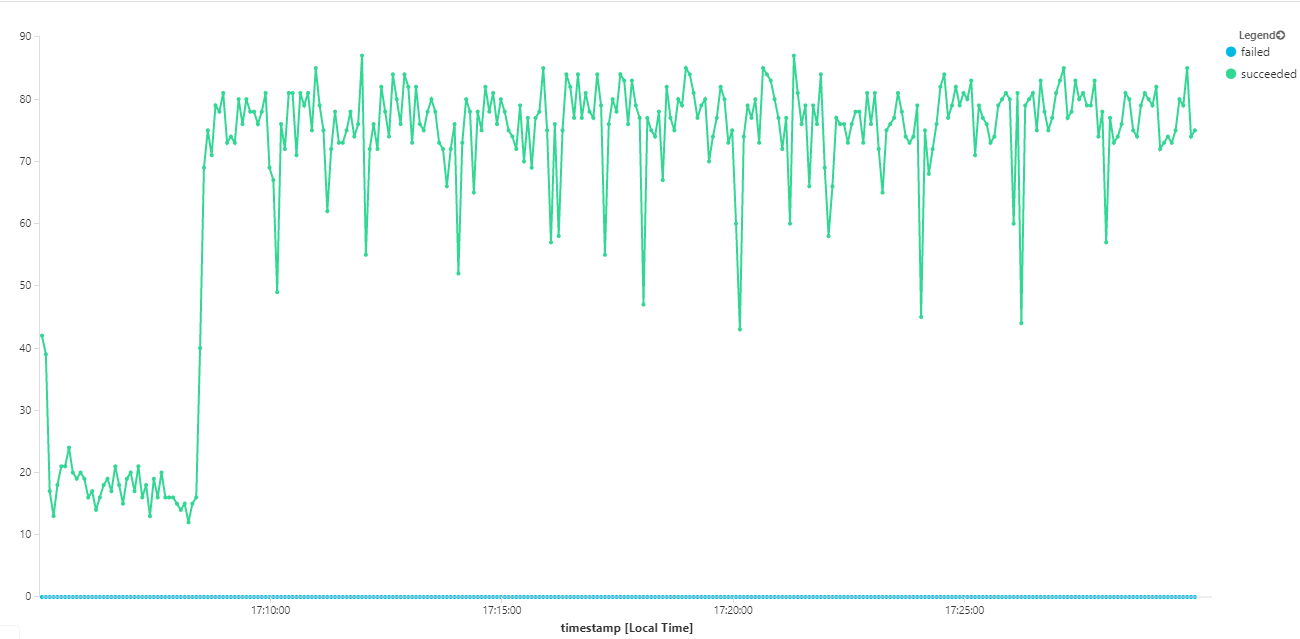
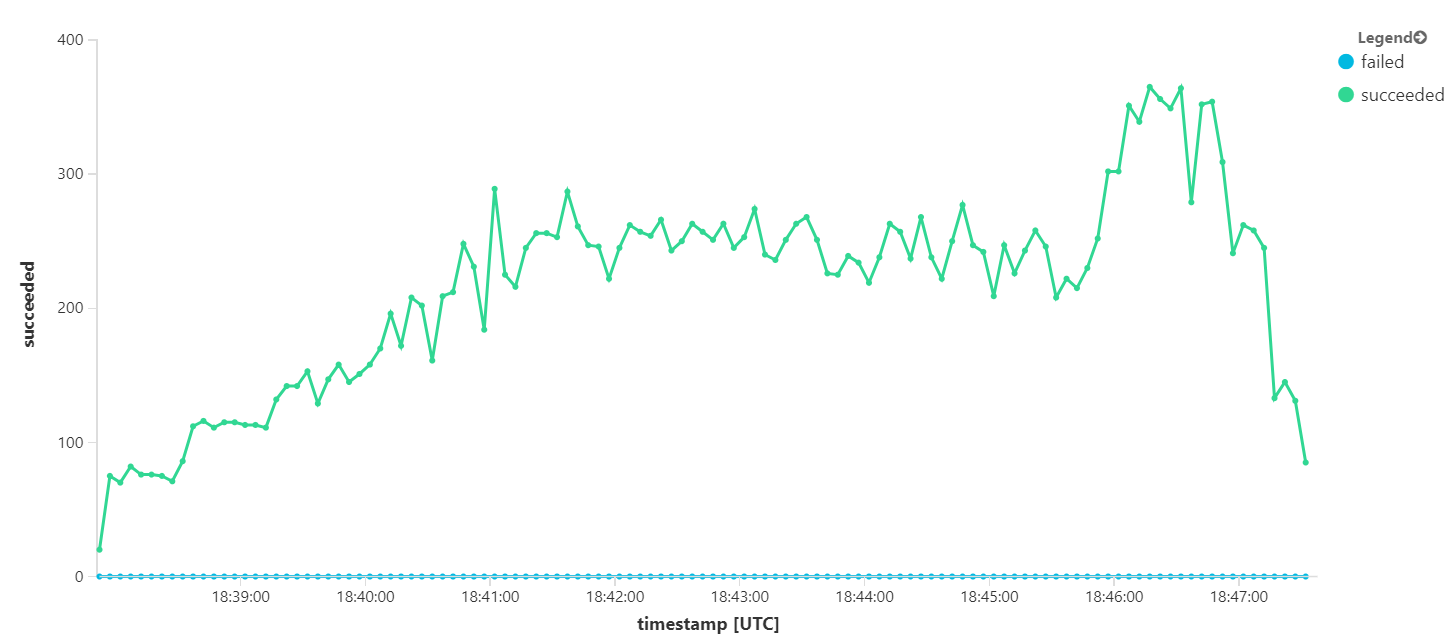
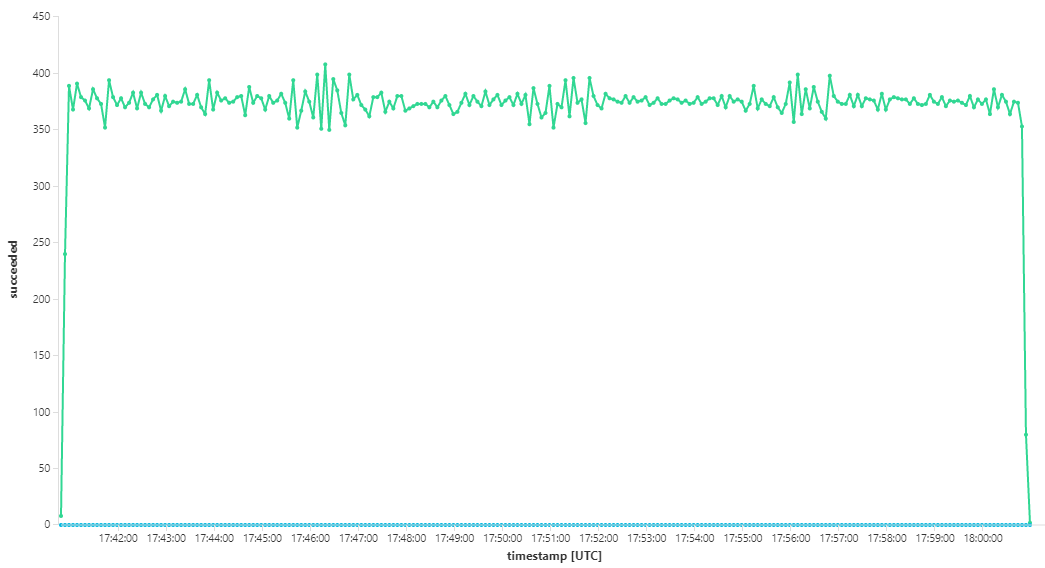
下圖會測量訊息完成時的輸送量,也就是工作流程服務將服務匯流排訊息標示為已完成的速率。 圖形上的每個點都代表 5 秒的資料,顯示 ~16/秒的最大輸送量。
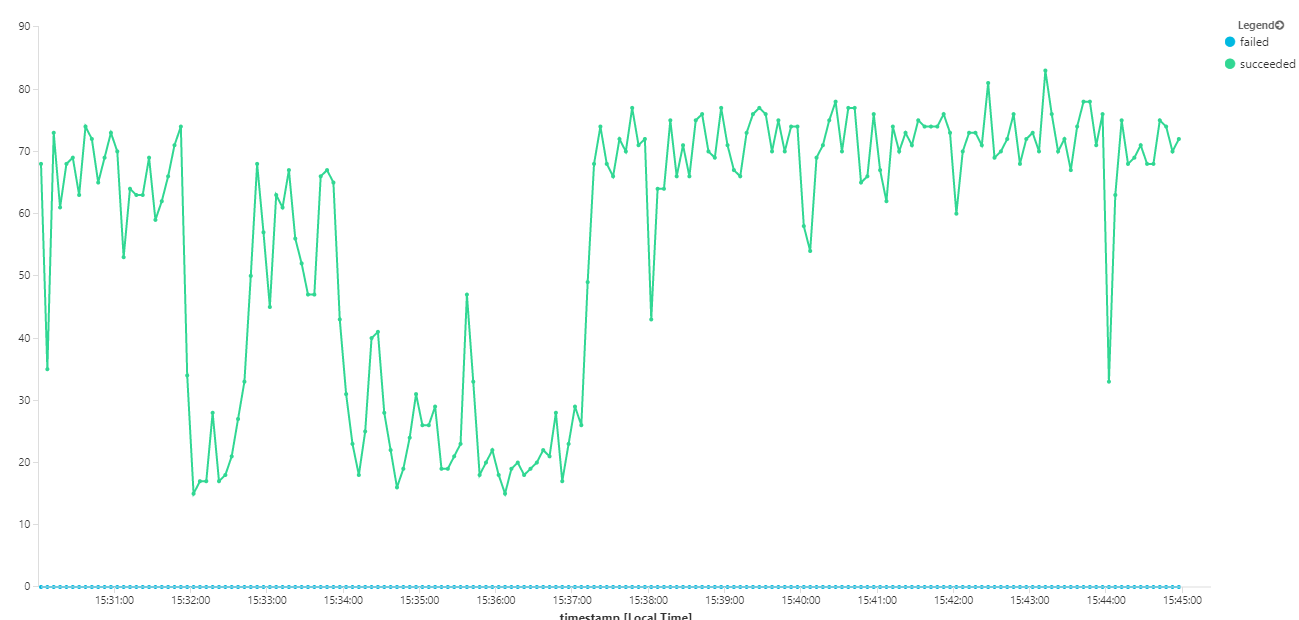
此圖表是由使用 Kusto 查詢語言在 Log Analytics 工作區中執行查詢所產生:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
dependencies
| where cloud_RoleName == 'fabrikam-workflow'
| where timestamp > start and timestamp < end
| where type == 'Azure Service Bus'
| where target has 'https://dev-i-iuosnlbwkzkau.servicebus.windows.net'
| where client_Type == "PC"
| where name == "Complete"
| summarize succeeded=sumif(itemCount, success == true), failed=sumif(itemCount, success == false) by bin(timestamp, 5s)
| render timechart
測試 3:相應放大後端服務
後端似乎是瓶頸。 下一個步驟是將商務服務相應放大 (套件、遞送和無人機排程器) ,並查看輸送量是否改善。 針對下一個負載測試,小組會將這些服務從三個複本相應放大至六個複本。
| 設定 | 值 |
|---|---|
| 叢集節點 | 6 |
| 擷取服務 | 3 個複本 |
| 工作流程服務 | 3 個複本 |
| 封裝、遞送、無人機排程器服務 | 每個複本 6 個複本 |
不幸的是,此負載測試只會顯示適度的改進。 傳出訊息仍然無法跟上傳入訊息:
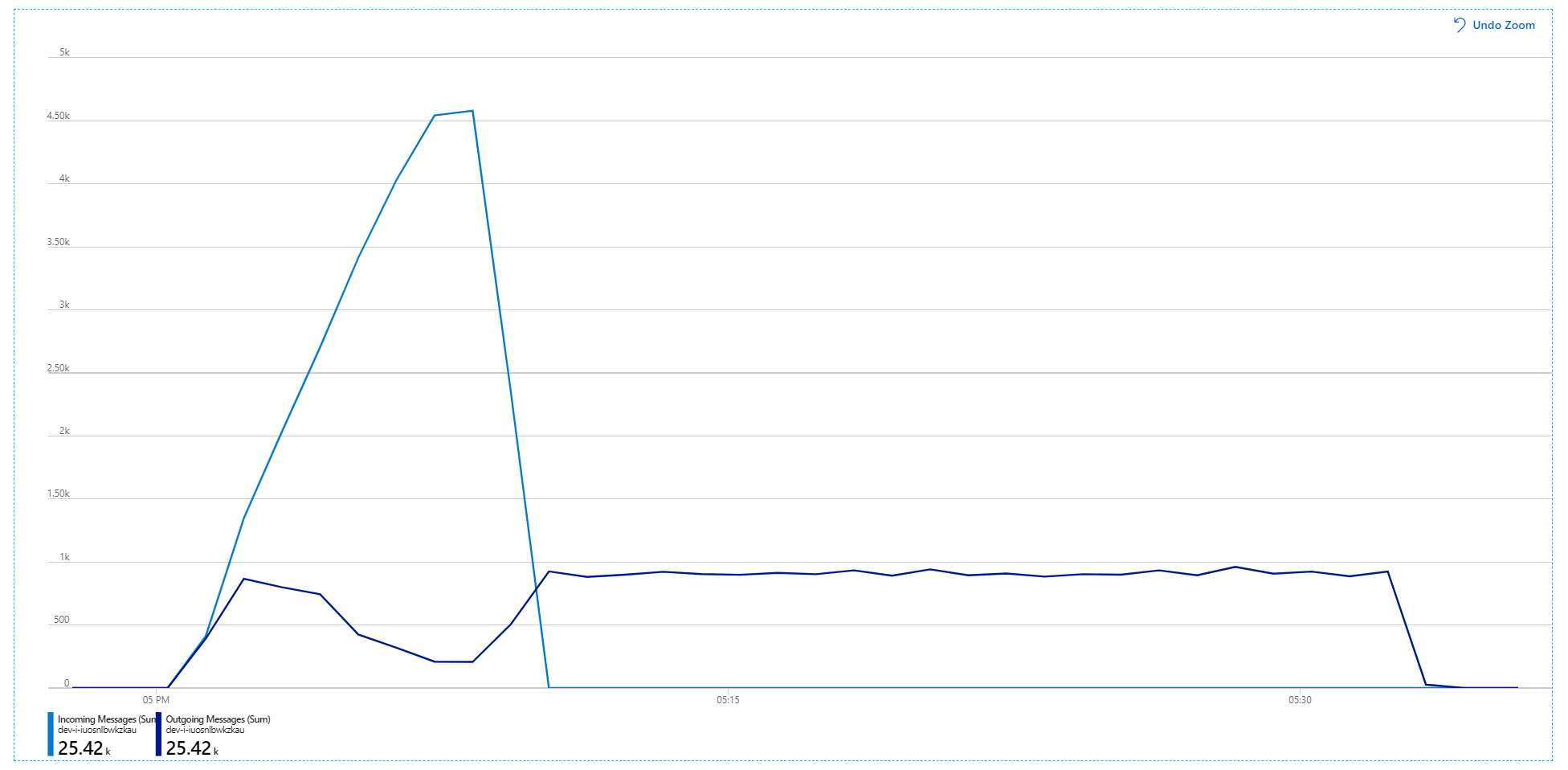
輸送量比較一致,但達到的最大值與先前的測試相同:
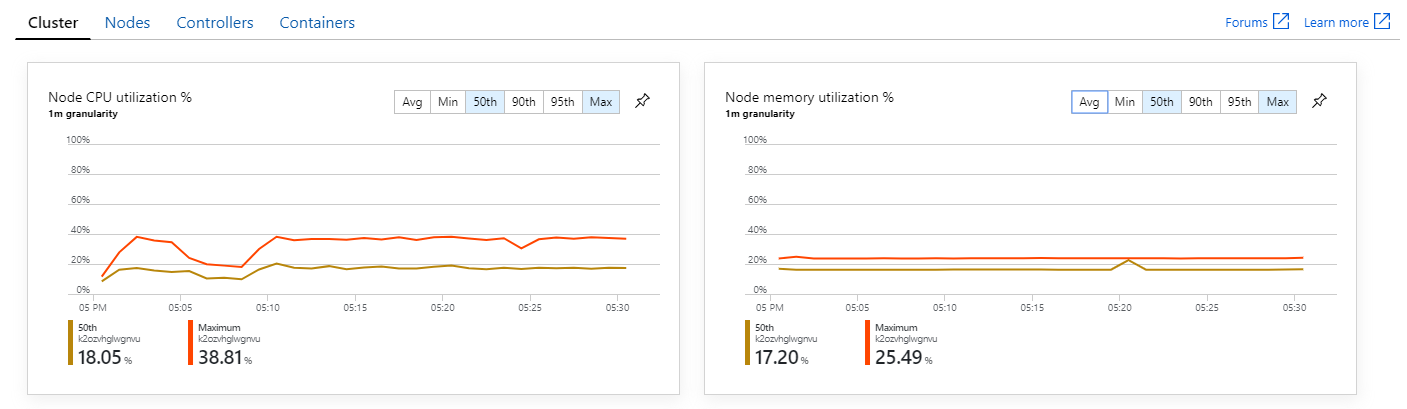
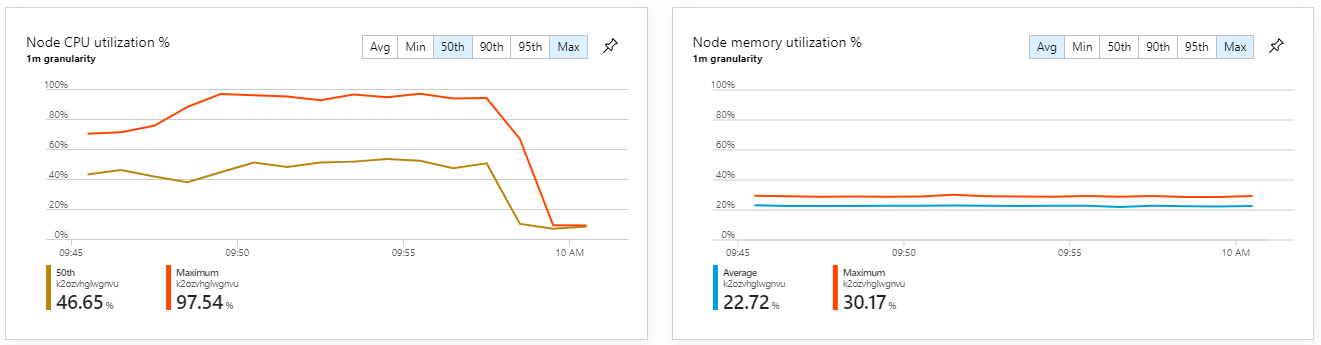
此外,查看 Azure 監視器容器深入解析,似乎問題不是因為叢集內的資源耗盡所造成。 首先,節點層級計量顯示即使在第 95 個百分位數,CPU 使用率仍維持在 40% 之下,記憶體使用率大約是 20%。
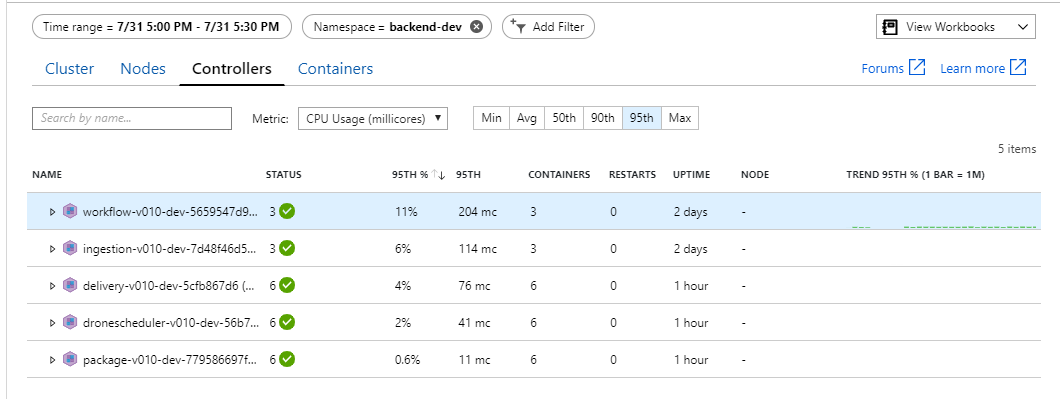
在 Kubernetes 環境中,即使節點不是,個別 Pod 還是可能會受到資源限制。 但 Pod 層級檢視會顯示所有 Pod 狀況良好。
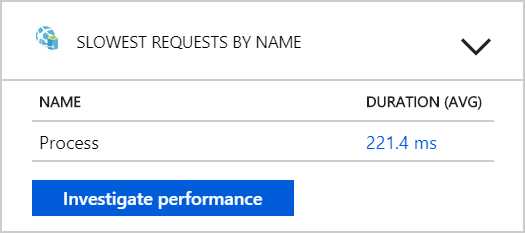
從這項測試中,似乎只將更多 Pod 新增至後端並無説明。 下一個步驟是更仔細地查看工作流程服務,以瞭解處理訊息時發生的情況。 Application Insights 顯示工作流程服務 Process 作業的平均持續時間為 246 毫秒。
我們也可以執行查詢,以取得每個交易內個別作業的計量:
| 目標 | percentile_duration_50 | percentile_duration_95 |
|---|---|---|
https://dev-i-iuosnlbwkzkau.servicebus.windows.net/ | dev-i-iuosnlbwkzkau |
86.66950203 | 283.4255578 |
| 偵錯 | 37 | 57 |
| 套件 | 12 | 17 |
| dronescheduler | 21 | 41 |
此表格中的第一個資料列代表服務匯流排佇列。 其他資料列是後端服務的呼叫。 如需參考,以下是此資料表的 Log Analytics 查詢:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
let dataset=dependencies
| where timestamp > start and timestamp < end
| where (cloud_RoleName == 'fabrikam-workflow')
| where name == 'Complete' or target in ('package', 'delivery', 'dronescheduler');
dataset
| summarize percentiles(duration, 50, 95) by target
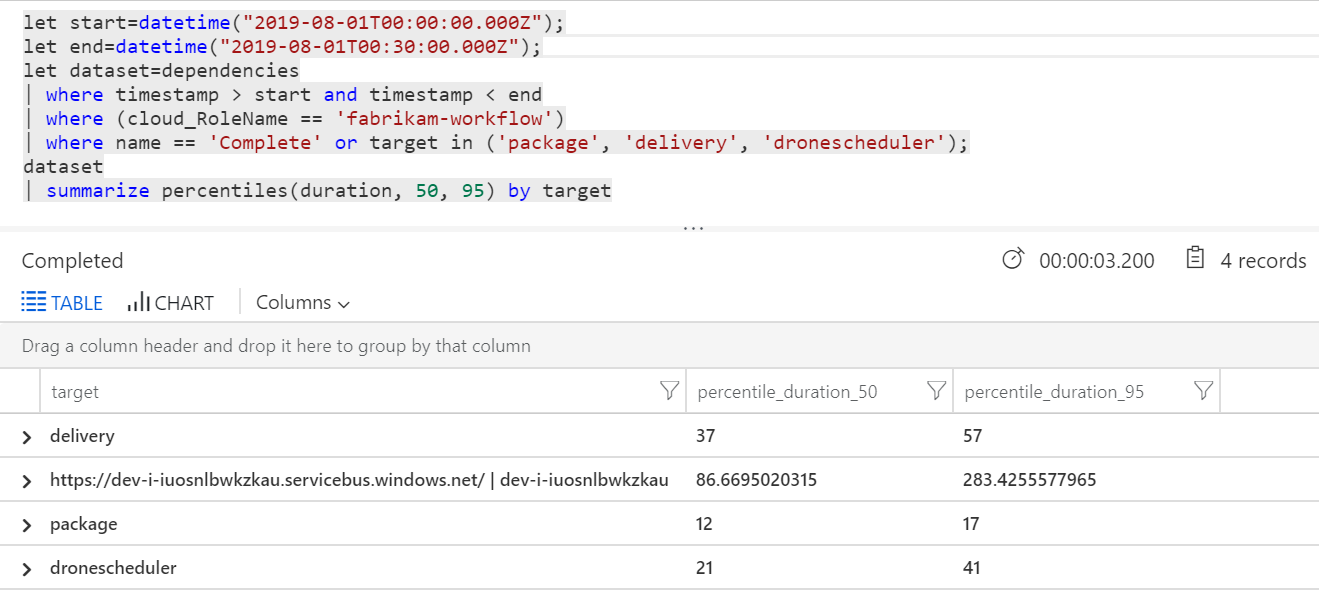
這些延遲看起來很合理。 但以下是關鍵深入解析:如果作業時間總計為 ~250 毫秒,則會在序列中處理訊息的速度設定嚴格的上限。 因此,改善輸送量的關鍵是更大的平行處理原則。
在此情況下應該可以這麼做,原因有兩個:
- 這些是網路呼叫,因此大部分時間都花在等候 I/O 完成
- 訊息是獨立的,不需要依序處理。
測試 4:增加平行處理原則
在此測試中,小組著重于增加平行處理原則。 若要這樣做,他們會調整工作流程服務所使用的服務匯流排用戶端上的兩個設定:
| 設定 | 描述 | 預設 | 新值 |
|---|---|---|---|
MaxConcurrentCalls |
要同時處理的訊息數目上限。 | 1 | 20 |
PrefetchCount |
用戶端會事先擷取多少個訊息到其本機快取。 | 0 | 3000 |
如需這些設定的詳細資訊,請參閱 使用服務匯流排傳訊改善效能的最佳做法。 使用這些設定執行測試會產生下列圖表:
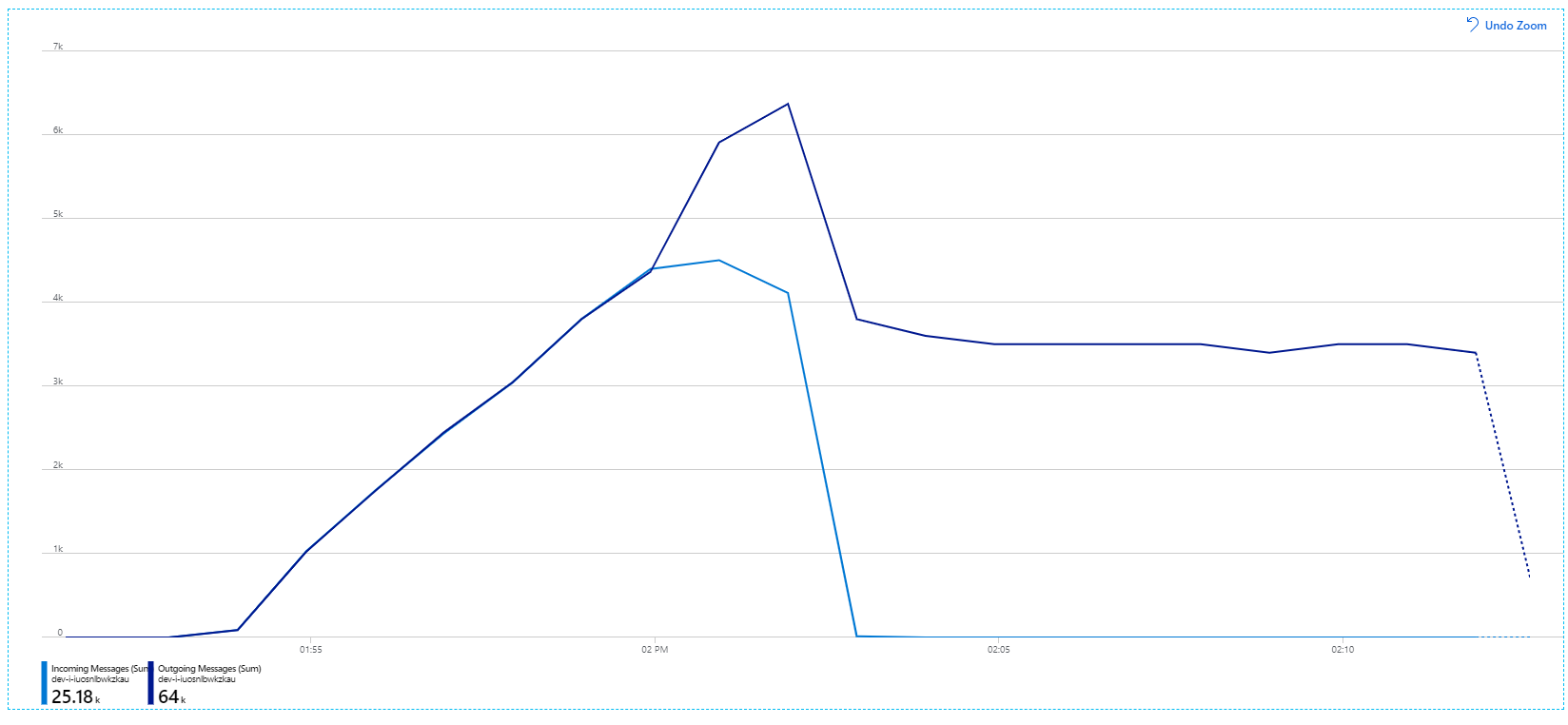
回想一下,傳入訊息會以淺藍色顯示,而傳出訊息則會以深藍色顯示。
第一眼,這是非常奇怪的圖表。 一段時間,傳出訊息速率會確切追蹤傳入速率。 但是,大約在 2:03 標記時,傳入訊息的速率會關閉,而傳出訊息的數目會持續增加,實際上超過傳入訊息的總數。 這似乎不可能。
您可以在 Application Insights 的 [ 相依性 ] 檢視中找到此秘密的線索。 此圖表摘要說明工作流程服務對服務匯流排所做的所有呼叫:
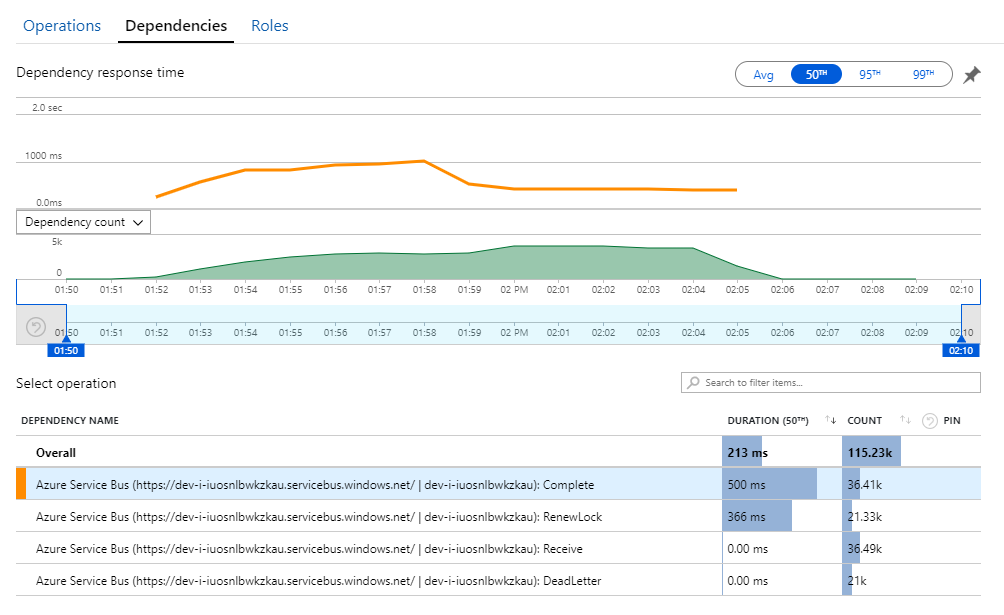
請注意, 的專案。 DeadLetter 該呼叫表示訊息進入服務匯流排 寄不出的信件佇列。
若要瞭解發生什麼情況,您必須瞭解服務匯流排中的 Peek-Lock 語意。 當用戶端使用 Peek-Lock 時,服務匯流排會以不可部分完成的方式擷取和鎖定訊息。 保留鎖定時,保證不會將訊息傳遞至其他接收者。 如果鎖定過期,訊息就會變成可供其他接收者使用。 在) 可設定的傳遞嘗試次數上限 (之後,服務匯流排會將訊息放入 寄不出的信件佇列,以供稍後檢查。
請記住,工作流程服務會預先擷取大量訊息,一次擷取 3000 則訊息) 。 這表示處理每個訊息的總時間較長,這會導致訊息逾時、回到佇列,最後進入寄不出的信件佇列。
您也可以在例外狀況中看到此行為,其中會記錄許多 MessageLostLockException 例外狀況:
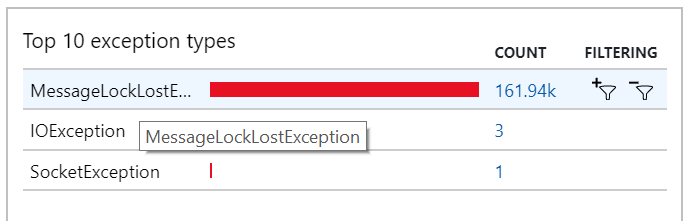
測試 5:增加鎖定持續時間
針對此負載測試,訊息鎖定持續時間設定為 5 分鐘,以防止鎖定逾時。 傳入和傳出訊息的圖表現在顯示系統正在跟上傳入訊息的速率:
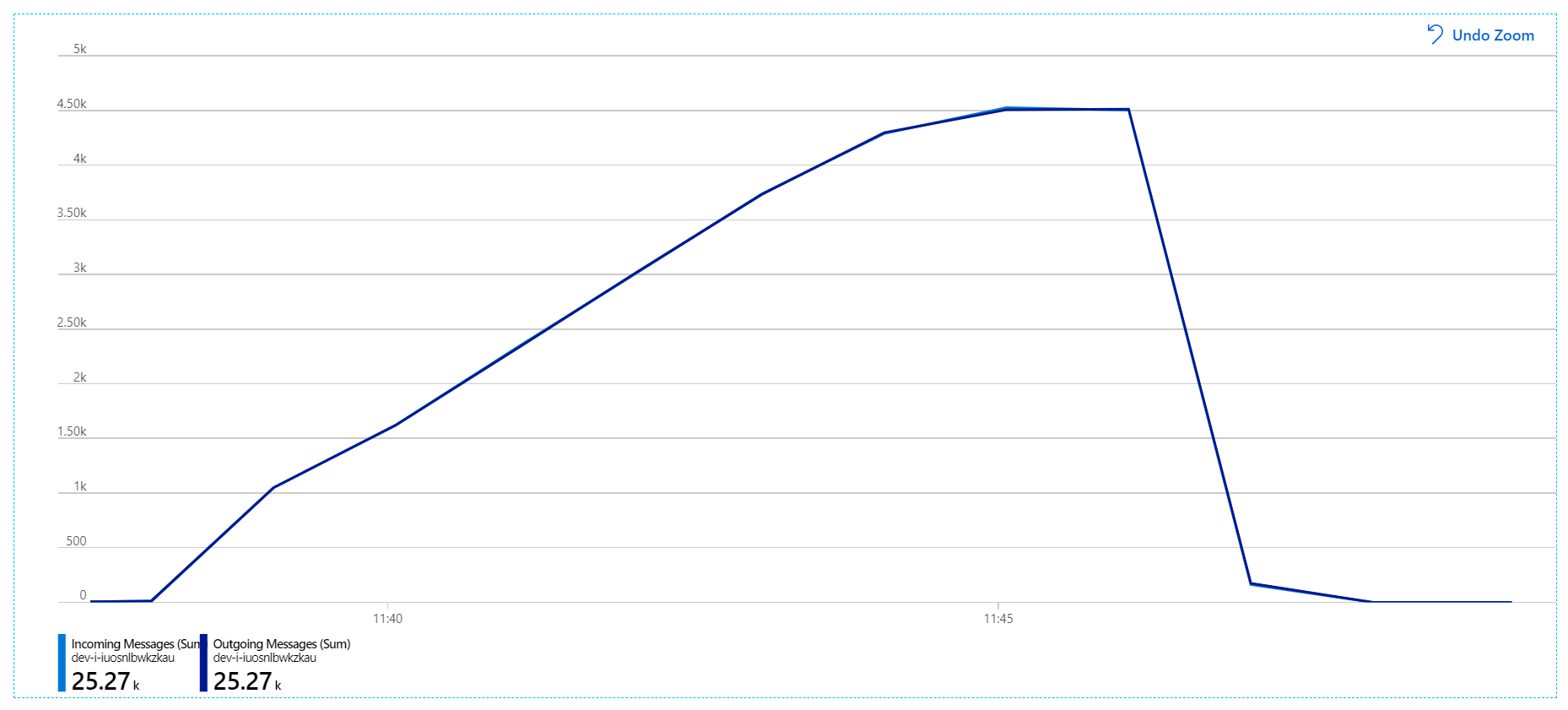
在 8 分鐘負載測試的總持續時間內,應用程式已完成 25 K 作業,尖峰輸送量為 72 個作業/秒,代表最大輸送量的 400%。
不過,執行具有相同持續時間的相同測試,顯示應用程式無法維持此速率:
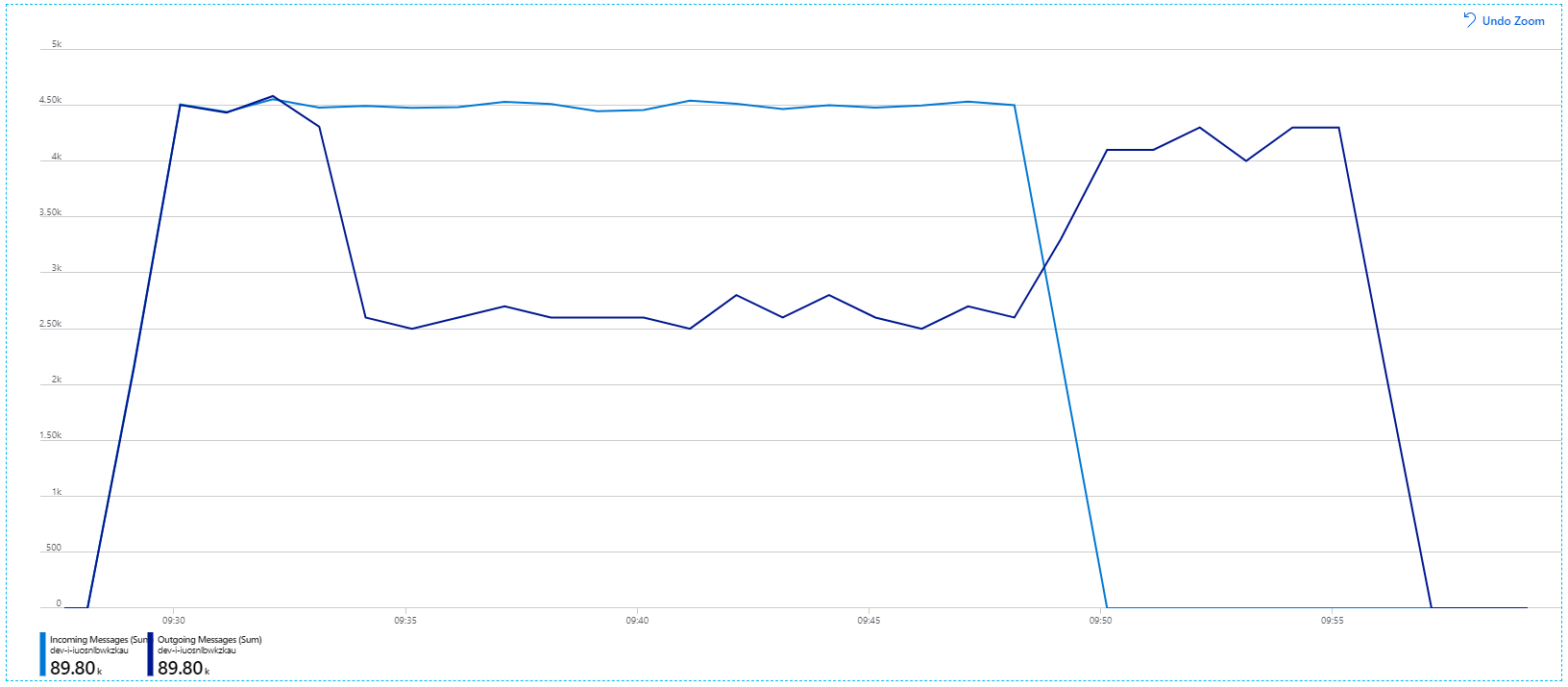
容器計量顯示最大 CPU 使用率接近 100%。 此時,應用程式會顯示為 CPU 系結。 調整叢集現在可能會改善效能,不同于先前的相應放大嘗試。
測試 6:再次相應放大後端服務 ()
針對系列的最終負載測試,小組已相應放大 Kubernetes 叢集和 Pod,如下所示:
| 設定 | 值 |
|---|---|
| 叢集節點 | 12 |
| 擷取服務 | 3 個複本 |
| 工作流程服務 | 6 個複本 |
| 封裝、遞送、無人機排程器服務 | 每個複本各有 9 個複本 |
此測試會產生較高的持續性輸送量,且處理訊息時不會有顯著的延遲。 此外,節點 CPU 使用率維持在 80% 以下。
摘要
在此案例中,已識別下列瓶頸:
- Azure Cache for Redis記憶體不足例外狀況。
- 訊息處理中缺少平行處理原則。
- 訊息鎖定持續時間不足,導致鎖定逾時和寄不出的信件佇列中的訊息。
- CPU 耗盡。
為了診斷這些問題,開發小組依賴下列計量:
- 傳入和傳出服務匯流排訊息的速率。
- Application Insights 中的應用程式對應。
- 錯誤和例外狀況。
- 自訂 Log Analytics 查詢。
- Azure 監視器容器深入解析中的 CPU 和記憶體使用率。
下一步
如需此案例設計的詳細資訊,請參閱 設計微服務架構。