本文說明開發小組如何使用計量來尋找瓶頸,並改善分散式系統的效能。 本文是以範例應用程式所執行的實際負載測試為基礎。 應用程式來自微服務的Azure Kubernetes Service (AKS) 基準,以及用來產生結果的Visual Studio 負載測試專案。
本文是系列文章的其中一篇。 請 在這裡閱讀第一個部分。
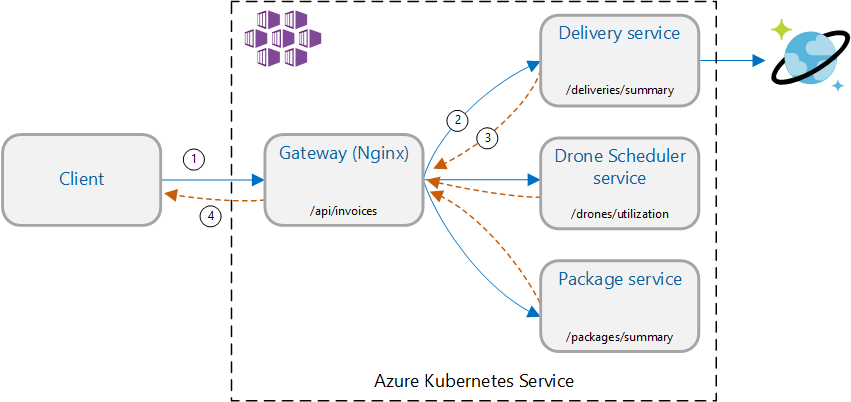
案例:呼叫多個後端服務以擷取資訊,然後匯總結果。
此案例牽涉到無人機遞送應用程式。 用戶端可以查詢 REST API 以取得其最新的發票資訊。 發票包含客戶交付專案、套件和無人機使用量總計的摘要。 此應用程式會使用在 AKS 上執行的微服務架構,而發票所需的資訊會分散到數個微服務。
應用程式會實作 閘道匯總 模式,而不是直接呼叫每個服務的用戶端。 使用此模式,用戶端會對閘道服務提出單一要求。 閘道接著會平行呼叫後端服務,然後將結果匯總成單一回應承載。
測試 1:基準效能
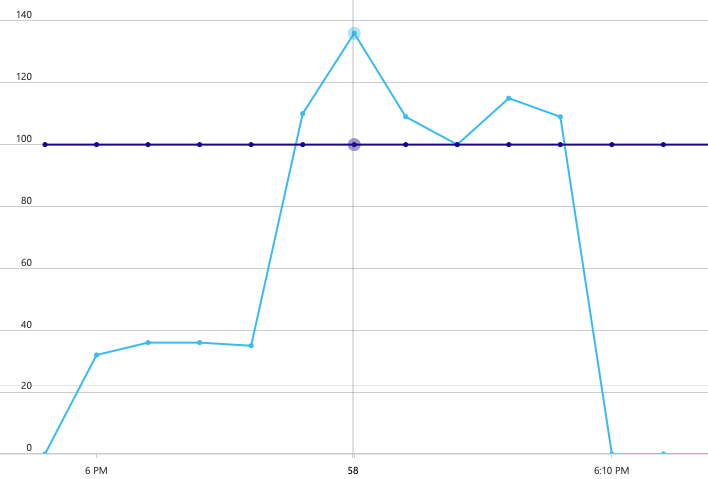
為了建立基準,開發小組從一個模擬使用者到最多 40 位使用者的負載,從一位模擬使用者開始進行逐步負載測試,總持續時間為 8 分鐘。 下圖取自 Visual Studio,顯示結果。 紫色線條會顯示使用者負載,而橙色線會顯示每秒平均要求的輸送量 () 。
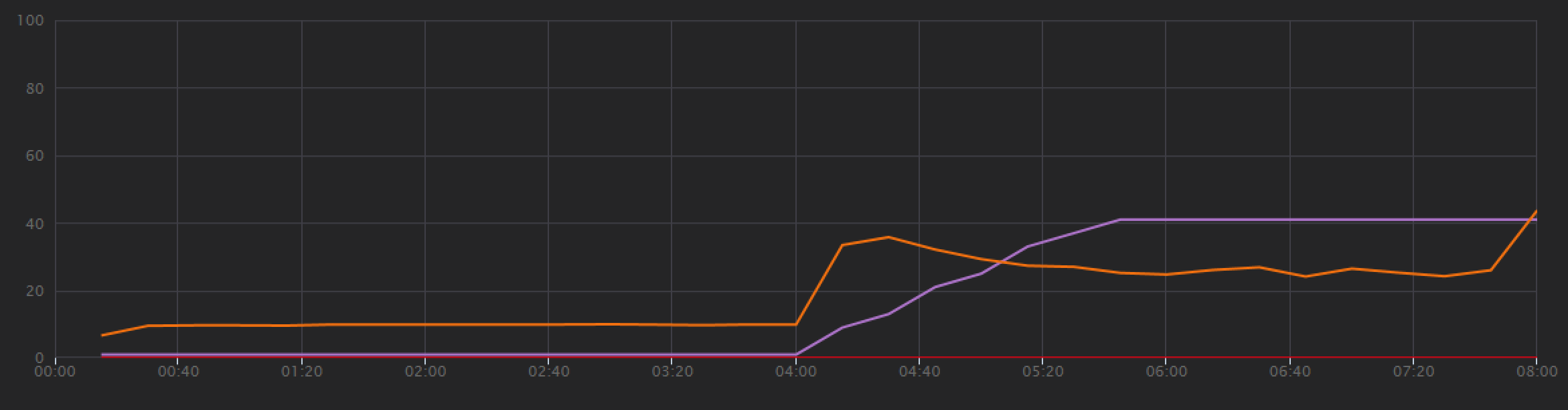
圖表底部的紅色線條顯示未將任何錯誤傳回給用戶端,這是鼓勵的。 不過,平均輸送量尖峰大約是測試的一半,然後捨棄其餘部分,即使負載持續增加也一樣。 這表示後端無法跟上。 當系統開始達到資源限制時,這裡所見的模式很常見,在達到最大值之後,輸送量實際上會大幅下降。 資源爭用、暫時性錯誤,或例外狀況率增加,都可能導致此模式。
讓我們深入探討監視資料,以瞭解系統內發生的情況。 下一張圖表取自 Application Insights。 它會顯示從閘道到後端服務之 HTTP 呼叫的平均持續時間。
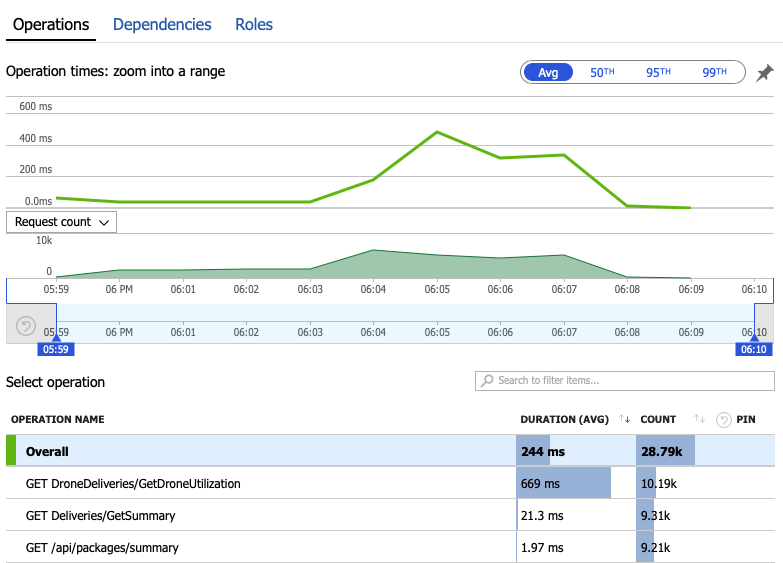
此圖表顯示一個作業,特別是 GetDroneUtilization ,平均花費較長的時間,依大小順序而定。 閘道會平行進行這些呼叫,因此最慢的作業會決定整個要求完成所需的時間。
清楚來說,下一個步驟是深入探討作業, GetDroneUtilization 並尋找任何瓶頸。 其中一個可能性是資源耗盡。 或許這個特定的後端服務已用盡 CPU 或記憶體。 對於 AKS 叢集,這項資訊可透過Azure 監視器容器深入解析功能在Azure 入口網站取得。 下圖顯示叢集層級的資源使用率:
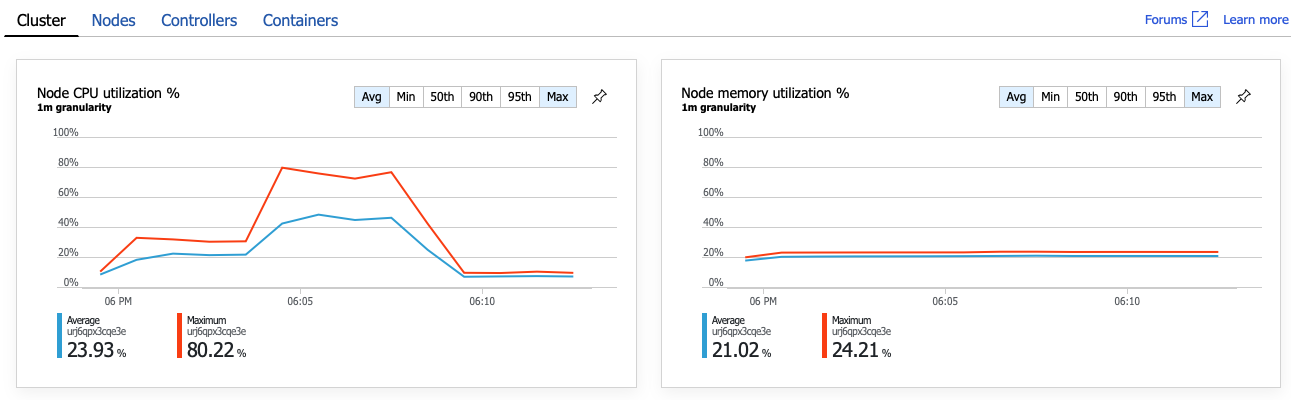
在此螢幕擷取畫面中,會顯示平均值和最大值。 請務必查看不只是平均值,因為平均值可以隱藏資料的尖峰。 在這裡,平均 CPU 使用率會維持低於 50%,但有數個尖峰至 80%。 這接近容量,但仍在容錯範圍內。 其他專案會造成瓶頸。
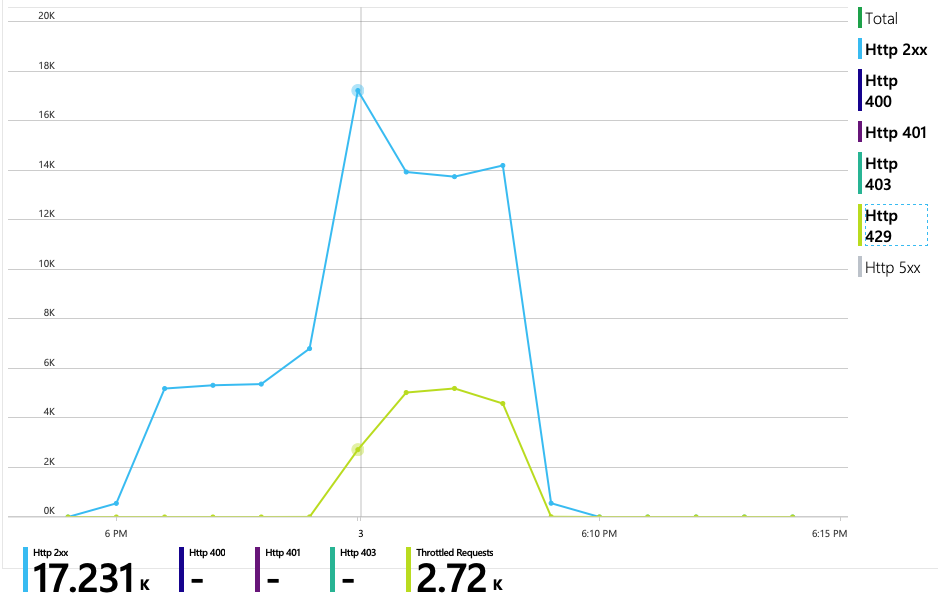
下一張圖表會顯示真正的原因。 此圖表顯示來自傳遞服務後端資料庫的 HTTP 回應碼,在此案例中為 Azure Cosmos DB。 藍色線條代表 HTTP 2xx) (成功碼,而綠色線條則代表 HTTP 429 錯誤。 HTTP 429 傳回碼表示 Azure Cosmos DB 會暫時節流要求,因為呼叫端耗用的資源 (單位比布建的 RU) 還要多。
為了取得進一步的深入解析,開發小組使用 Application Insights 來檢視代表要求範例的端對端遙測。 以下是一個實例:
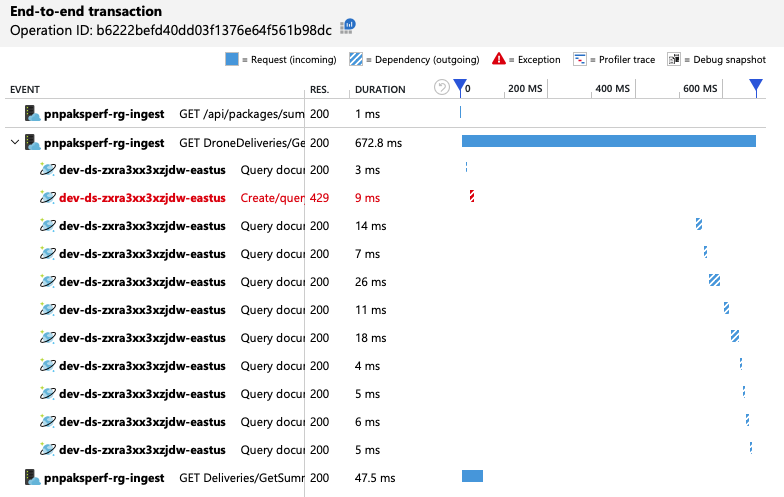
此檢視會顯示與單一用戶端要求相關的呼叫,以及計時資訊和回應碼。 最上層呼叫是從閘道到後端服務。 的呼叫 GetDroneUtilization 會展開以顯示對外部相依性的呼叫,在此案例中為對 Azure Cosmos DB 的呼叫。 紅色的呼叫傳回 HTTP 429 錯誤。
請注意 HTTP 429 錯誤與下一個呼叫之間的大間距。 當 Azure Cosmos DB 用戶端程式庫收到 HTTP 429 錯誤時,它會自動回復並等候重試作業。 此檢視顯示,在 672 毫秒期間,此作業花費的時間大部分是等待重試 Azure Cosmos DB。
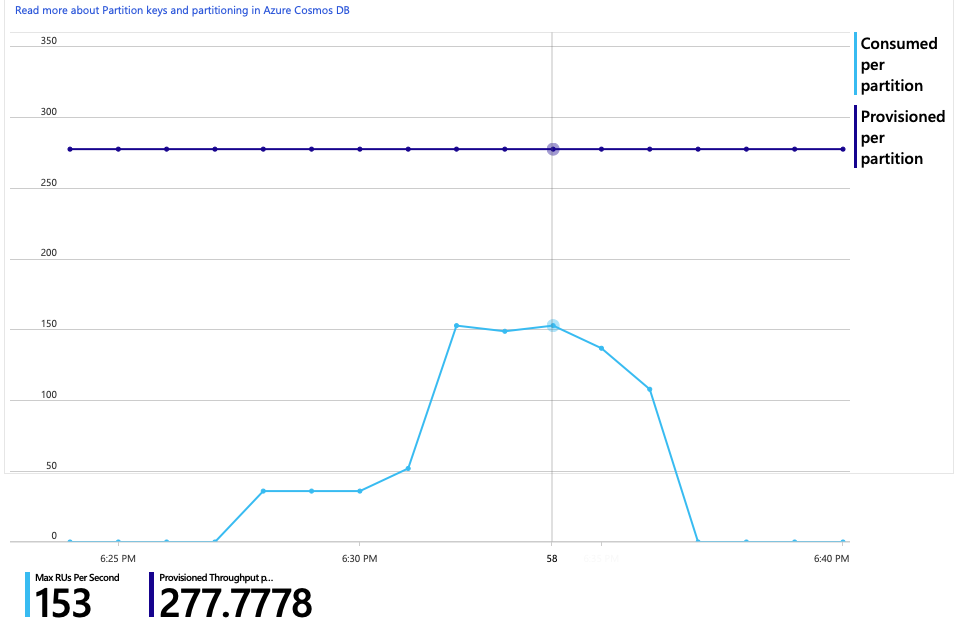
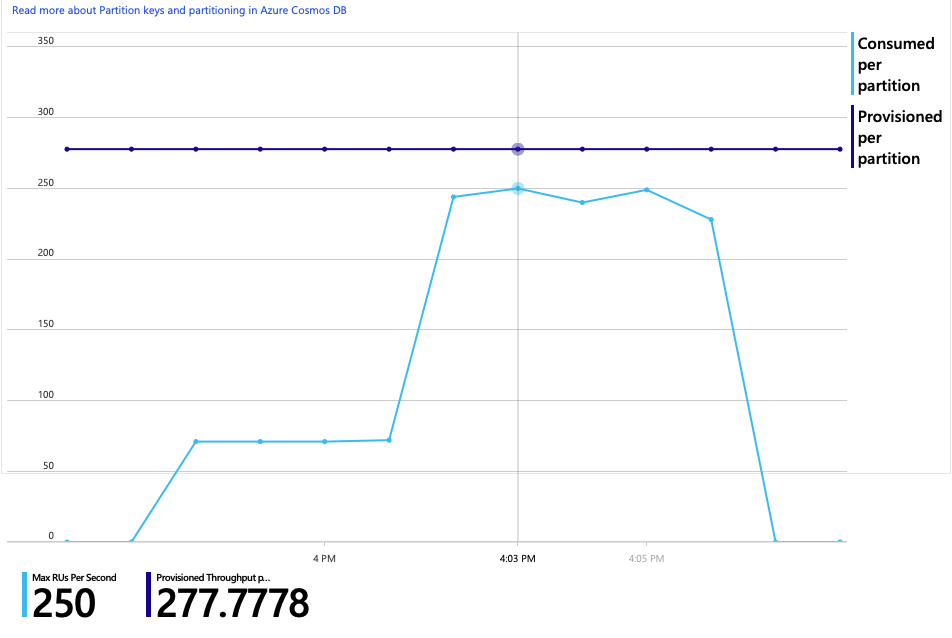
以下是此分析的另一個有趣圖表。 它會顯示每個實體分割區與每個實體分割區布建 RU 的 RU 耗用量:
若要瞭解此圖表,您必須瞭解 Azure Cosmos DB 如何管理分割區。 Azure Cosmos DB 中的集合可以有 分割區索引鍵。 每個可能的索引鍵值都會定義集合內資料的邏輯分割區。 Azure Cosmos DB 會將這些邏輯分割區分散到一或多個 實體 分割區。 Azure Cosmos DB 會自動處理實體分割區的管理。 當您儲存更多資料時,Azure Cosmos DB 可能會將邏輯分割區移至新的實體分割區,以便將負載分散到實體分割區。
針對此負載測試,Azure Cosmos DB 集合已布建 900 RU。 圖表顯示每個實體分割區 100 RU,這表示總共九個實體分割區。 雖然 Azure Cosmos DB 會自動處理實體分割區的分區化,但瞭解分割區計數可以深入瞭解效能。 開發小組稍後會使用這項資訊,因為它們會繼續優化。 其中藍色線條跨越紫色水平線,RU 耗用量已超過布建的 RU。 這就是 Azure Cosmos DB 開始節流呼叫的點。
測試 2:增加資源單位
針對第二個負載測試,小組將 Azure Cosmos DB 集合從 900 RU 相應放大至 2500 RU。 輸送量從 19 個要求/秒增加到 23 個要求/秒,平均延遲從 669 毫秒減少到 569 毫秒。
| 計量 | 測試 1 | 測試 2 |
|---|---|---|
| 輸送量 (req/sec) | 19 | 23 |
| 平均延遲 (毫秒) | 669 | 569 |
| 成功的要求 | 9.8 K | 11 K |
這些並非大幅提升,但查看一段時間的圖表會顯示更完整的圖片:
雖然先前的測試顯示初始尖峰,後面接著尖峰下降,但此測試會顯示更一致的輸送量。 不過,最大輸送量不明顯較高。
對 Azure Cosmos DB 的所有要求都傳回 2xx 狀態,而 HTTP 429 錯誤已消失:
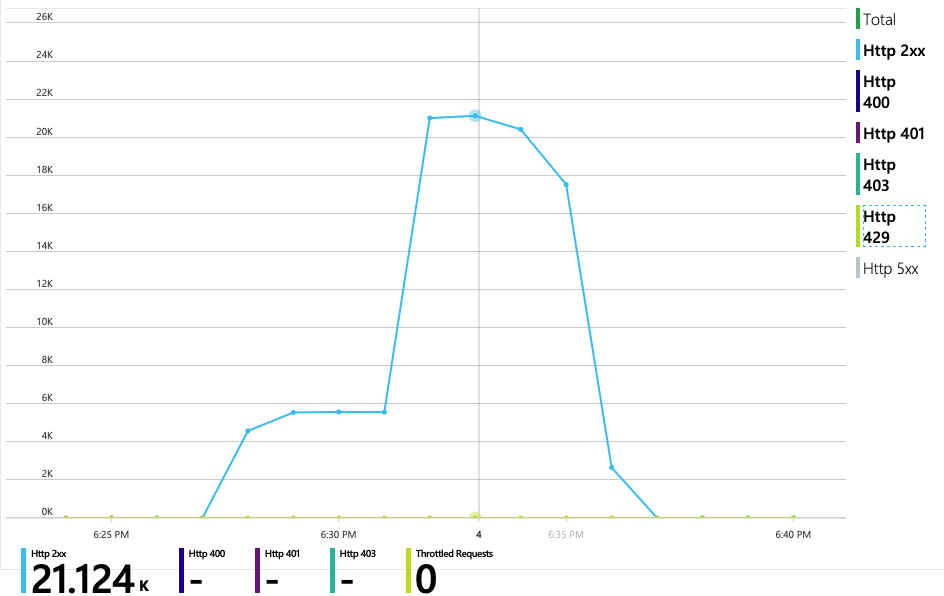
RU 耗用量與布建 RU 的圖表顯示有許多前端。 每個實體分割區大約有 275 個 RU,負載測試尖峰為每秒大約 100 RU。
另一個有趣的計量是每個成功作業對 Azure Cosmos DB 的呼叫次數:
| 計量 | 測試 1 | 測試 2 |
|---|---|---|
| 每個作業的呼叫 | 11 | 9 |
假設沒有錯誤,呼叫數目應該符合實際的查詢計劃。 在此情況下,作業牽涉到會叫用所有九個實體分割區的跨分割區查詢。 第一個負載測試中的較高值反映傳回 429 錯誤的呼叫數目。
執行自訂 Log Analytics 查詢來計算此計量:
let start=datetime("2020-06-18T20:59:00.000Z");
let end=datetime("2020-07-24T21:10:00.000Z");
let operationNameToEval="GET DroneDeliveries/GetDroneUtilization";
let dependencyType="Azure DocumentDB";
let dataset=requests
| where timestamp > start and timestamp < end
| where success == true
| where name == operationNameToEval;
dataset
| project reqOk=itemCount
| summarize
SuccessRequests=sum(reqOk),
TotalNumberOfDepCalls=(toscalar(dependencies
| where timestamp > start and timestamp < end
| where type == dependencyType
| summarize sum(itemCount)))
| project
OperationName=operationNameToEval,
DependencyName=dependencyType,
SuccessRequests,
AverageNumberOfDepCallsPerOperation=(TotalNumberOfDepCalls/SuccessRequests)
總而言之,第二個負載測試會顯示改善。 不過, GetDroneUtilization 作業仍需要超過下一個最慢作業的大小順序。 查看端對端交易有助於說明原因:
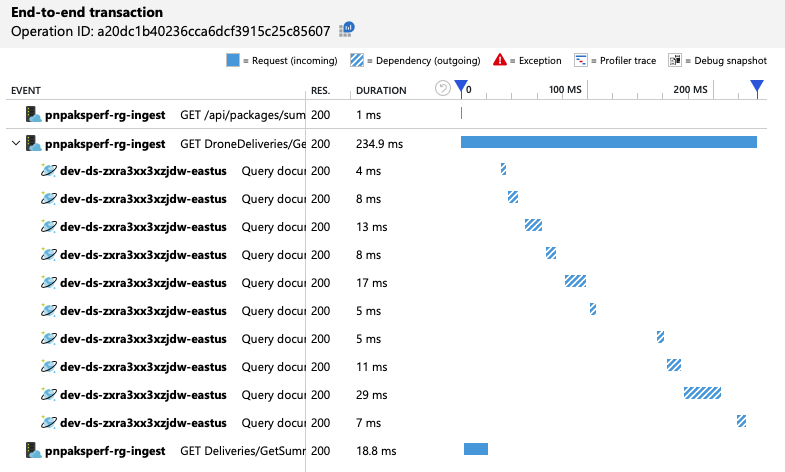
如先前所述,作業 GetDroneUtilization 牽涉到 Azure Cosmos DB 的跨分割區查詢。 這表示 Azure Cosmos DB 用戶端必須向每個實體分割區展開查詢,並收集結果。 當端對端交易檢視顯示時,這些查詢會以序列方式執行。 只要所有查詢的總和,這項作業就只會隨著資料的大小成長而增加更多實體分割區而變差。
測試 3:平行查詢
根據先前的結果,減少延遲的明顯方式是平行發出查詢。 Azure Cosmos DB 用戶端 SDK 具有可控制平行處理原則最大程度的設定。
| 值 | 描述 |
|---|---|
| 0 | 預設) 沒有平行處理原則 ( |
| > 0 | 平行呼叫數目上限 |
| -1 | 用戶端 SDK 會選取最佳的平行處理原則程度 |
針對第三個負載測試,此設定已從 0 變更為 -1。 下表摘要說明結果:
| 計量 | 測試 1 | 測試 2 | 測試 3 |
|---|---|---|---|
| 輸送量 (req/sec) | 19 | 23 | 42 |
| 平均延遲 (毫秒) | 669 | 569 | 215 |
| 成功的要求 | 9.8 K | 11 K | 20 K |
| 節流要求 | 2.72 K | 0 | 0 |
從負載測試圖表中,不僅在橙色線) (整體輸送量更高,輸送量也會隨著負載 (紫色線條) 保持步調。
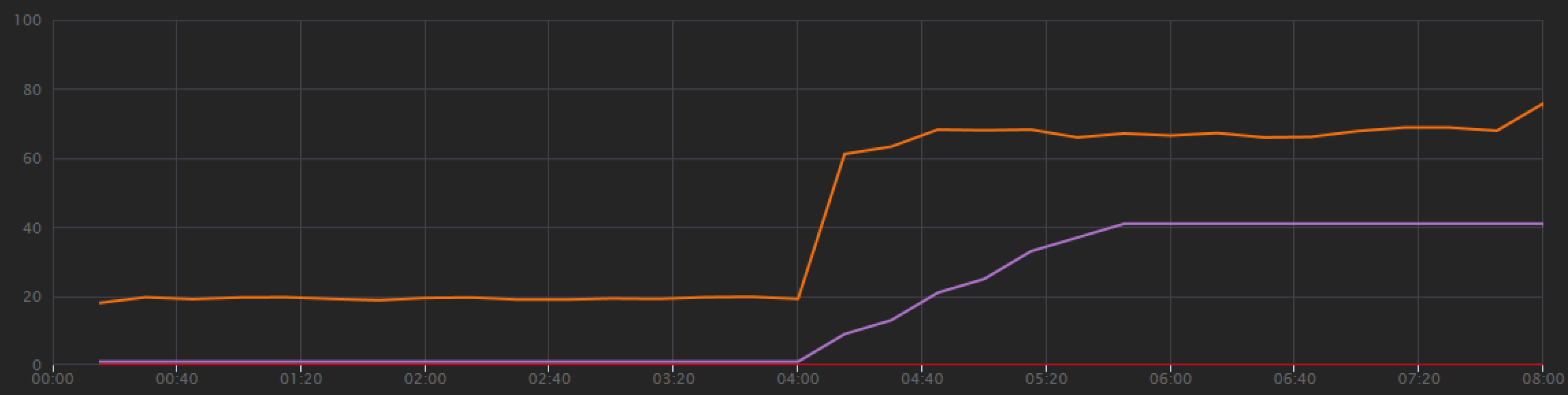
我們可以查看端對端交易檢視,確認 Azure Cosmos DB 用戶端正在平行進行查詢:
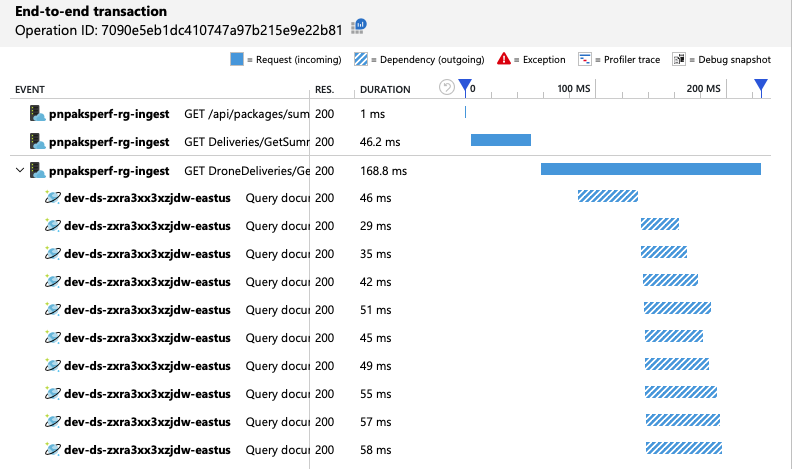
有趣的是,增加輸送量的副作用是每秒耗用的 RU 數目也會增加。 雖然 Azure Cosmos DB 未在此測試期間節流任何要求,但耗用量接近布建的 RU 限制:
此圖表可能是進一步相應放大資料庫的訊號。 不過,我們發現我們可以改為優化查詢。
步驟 4:優化查詢
先前的負載測試在延遲和輸送量方面顯示更好的效能。 平均要求延遲減少 68%,輸送量增加 220%。 不過,跨分割區查詢是一個考慮。
跨分割區查詢的問題在於,您會針對每個分割區支付 RU 的費用。 如果查詢偶爾只會執行,例如,一小時一次,就不重要。 但是,每當看到牽涉到跨分割區查詢的大量讀取工作負載時,您應該會看到查詢是否可以藉由包含分割區索引鍵來優化。 (您可能需要重新設計集合,才能使用不同的分割區索引鍵。)
以下是此特定案例的查詢:
SELECT * FROM c
WHERE c.ownerId = <ownerIdValue> and
c.year = <yearValue> and
c.month = <monthValue>
此查詢會選取符合特定擁有者識別碼和月份/年份的記錄。 在原始設計中,這些屬性都不是分割區索引鍵。 這需要用戶端向每個實體分割區展開查詢,並收集結果。 為了改善查詢效能,開發小組已變更設計,讓擁有者識別碼是集合的資料分割索引鍵。 如此一來,查詢就可以以特定實體分割區為目標。 (Azure Cosmos DB 會自動處理此情況;您不需要管理分割區索引鍵值與實體 partitions 之間的對應。)
將集合切換至新的分割區索引鍵之後,RU 耗用量大幅改善,這可直接轉換成較低的成本。
| 計量 | 測試 1 | 測試 2 | 測試 3 | 測試 4 |
|---|---|---|---|---|
| 每個作業的 RU | 29 | 29 | 29 | 3.4 |
| 每個作業的呼叫 | 11 | 9 | 10 | 1 |
端對端交易檢視會顯示為預測,查詢只會讀取一個實體分割區:
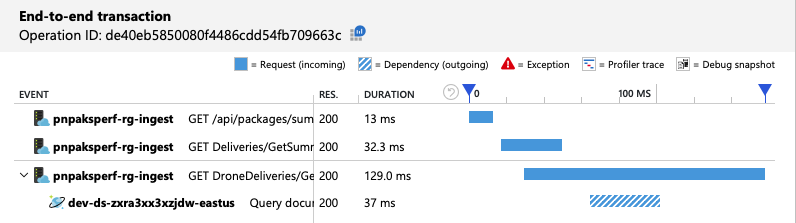
負載測試會顯示改善的輸送量和延遲:
| 計量 | 測試 1 | 測試 2 | 測試 3 | 測試 4 |
|---|---|---|---|---|
| 輸送量 (req/sec) | 19 | 23 | 42 | 59 |
| 平均延遲 (毫秒) | 669 | 569 | 215 | 176 |
| 成功的要求 | 9.8 K | 11 K | 20 K | 29 K |
| 節流要求 | 2.72 K | 0 | 0 | 0 |
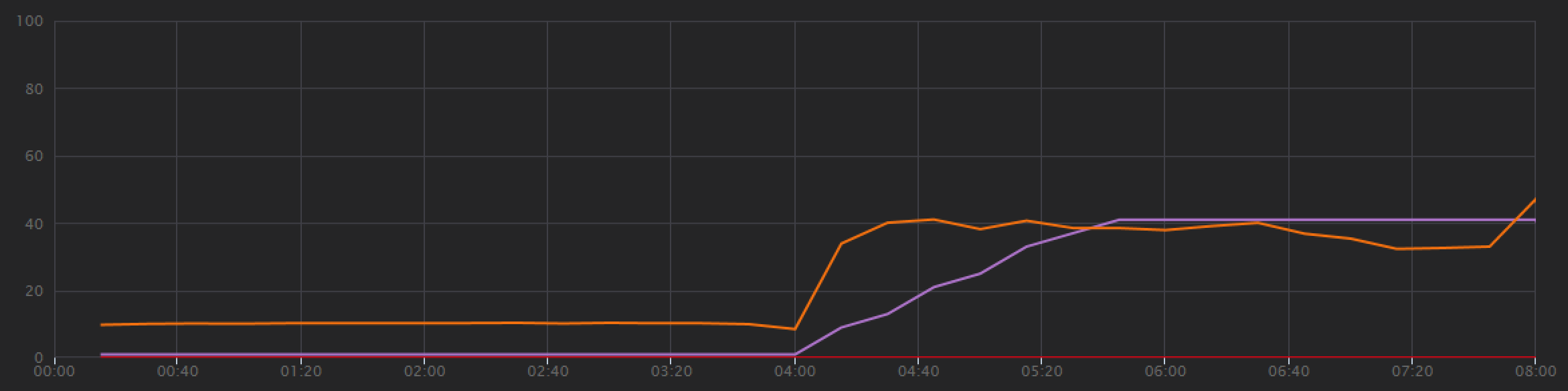
改善效能的結果是節點 CPU 使用率變得非常高:
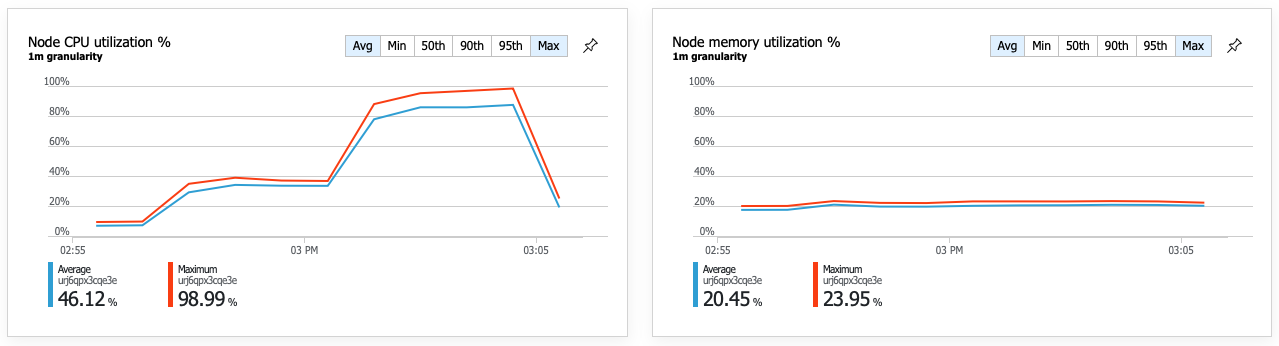
在負載測試結束時,平均 CPU 達到約 90%,最大 CPU 達到 100%。 此計量表示 CPU 是系統中的下一個瓶頸。 如果需要較高的輸送量,下一個步驟可能會將傳遞服務相應放大至更多實例。
摘要
在此案例中,已識別下列瓶頸:
- Azure Cosmos DB 節流要求,因為布建的 RU 不足。
- 查詢序列中多個資料庫分割區所造成的高延遲。
- 無效率的跨分割區查詢,因為查詢未包含資料分割索引鍵。
此外,CPU 使用率已識別為較高規模的潛在瓶頸。 為了診斷這些問題,開發小組已查看:
- 負載測試的延遲和輸送量。
- Azure Cosmos DB 錯誤和 RU 耗用量。
- Application Insight 中的端對端交易檢視。
- Azure 監視器容器深入解析中的 CPU 和記憶體使用率。
下一步
檢閱 效能反模式