了解數據存放區模型
新式商務系統會管理越來越多的異質數據。 這種異質性表示單一數據存放區通常不是最佳方法。 相反地,最好將不同類型的數據儲存在不同的數據存放區中,每個數據都著重於特定工作負載或使用模式。 多語言持久性 一詞用來描述使用混合資料儲存技術的解決方案。 因此,請務必瞭解主要記憶體模型及其取捨。
為您的需求選取正確的數據存放區是重要的設計決策。 在 SQL 和 NoSQL 資料庫之間有數百個實作可供選擇。 數據存放區通常會依數據的結構和其支援的作業類型來分類。 本文說明數個最常見的記憶體模型。 請注意,特定數據存放區技術可能支援多個記憶體模型。 例如,關係資料庫管理系統 (RDBMS) 也可能支援索引鍵/值或圖形記憶體。 事實上,在所謂的 多模型 支持中,有一個普遍的趨勢,即單一資料庫系統支持多個模型。 但是,在高層級瞭解不同的模型仍然很有用。
並非指定類別中的所有數據存放區都提供相同的功能集。 大部分的數據存放區都提供伺服器端功能來查詢和處理數據。 有時候這項功能會內建於數據儲存引擎中。 在其他情況下,數據儲存和處理功能會分開,而且可能有數個選項可用來處理和分析。 數據存放區也支援不同的程序設計和管理介面。
一般而言,您應該從考慮最適合您需求的記憶體模型開始。 然後,根據功能集、成本和易於管理等因素,考慮該類別內的特定數據存放區。
注意
若要深入瞭解如何識別和檢閱雲端採用的數據服務需求,請參閱 azure
關係資料庫管理系統
關係資料庫會將數據組織成一系列具有數據列和數據行的二維數據表。 大部分廠商都會提供結構化查詢語言 (SQL) 的方言來擷取和管理數據。 RDBMS 通常會實作一套符合 ACID(原子性、一致性、隔離性、持久性)模型的交易一致性機制,以更新資訊。
RDBMS 通常支援架構寫入模型,其中數據結構會事先定義,而且所有讀取或寫入作業都必須使用架構。
當強式一致性保證非常重要時,此模型非常有用,其中所有變更都是具備原子性的,而交易總是會讓資料保持一致狀態。 不過,RDBMS 通常無法水平擴展,若不以某種方式將數據分片。 此外,RDBMS 中的數據必須正規化,這不適用於每個數據集。
Azure 服務
- Azure SQL Database | (安全性基準)
- 適用於 MySQL 的 Azure 資料庫 | (安全性基準)
- 適用於 PostgreSQL 的 Azure 資料庫 | (安全性基準)
- 適用於 MariaDB 的 Azure 資料庫 | (安全性基準)
工作量
- 記錄經常建立和更新。
- 單一交易中必須完成多個作業。
- 關係是利用資料庫約束條件被強化的。
- 索引可用來優化查詢效能。
數據類型
- 數據會高度正規化。
- 需要並強制執行資料庫架構。
- 資料庫中數據實體之間的多對多關聯性。
- 條件約束定義於架構中,並強加於資料庫中的任何數據。
- 數據需要高完整性。 索引和關聯性必須正確維護。
- 數據需要強式一致性。 交易的運作方式是確保所有數據對於所有使用者和進程都是 100% 一致的。
- 個別數據項的大小是小型到中型。
例子
- 清查管理
- 訂單管理
- 報告資料庫
- 會計學
鍵-值儲存
索引鍵/值存放區會將每個數據值與唯一索引鍵產生關聯。 大部分的索引鍵/值存放區只支援簡單的查詢、插入和刪除作業。 若要修改值(部分或完全修改),應用程式必須覆寫整個值的現有數據。 在大部分的實作情況下,讀取或寫入單一值是一個原子操作。
應用程式可以將任意數據儲存為一組值。 應用程式必須提供任何架構資訊。 索引鍵/值存放區只會依索引鍵擷取或儲存值。
鍵值存儲系統圖表 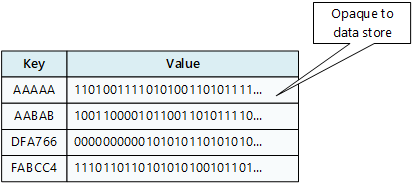
索引鍵/值存放區針對執行簡單查閱的應用程式進行高度優化,但如果您需要跨不同的索引鍵/值存放區查詢數據,則較不適合。 鍵值儲存也未針對值查詢進行優化。
單一鍵值儲存區具有極高的擴展性,因為資料儲存區可以輕鬆地將資料分散到不同機器的多個節點。
Azure 服務
- 適用於數據表 的 Azure Cosmos DB 和 適用於 NoSQL 的 Azure Cosmos DB | (Azure Cosmos DB 安全性基準)
- Azure Cache for Redis | (安全性基準)
- Azure 資料表記憶體 | (安全性基準)
工作量
- 數據是使用單一索引鍵來存取,例如字典。
- 不需要連接、鎖定或合併。
- 不會使用匯總機制。
- 通常不會使用次要索引。
數據類型
- 每個鍵都會與單一值相關聯。
- 沒有結構規範控制。
- 實體之間沒有關聯性。
例子
- 數據快取
- 會話管理
- 用戶喜好設定和個人檔案管理
- 產品建議和廣告服務
文件資料庫
文件資料庫會儲存 文件集合,其中每個文件都包含具名欄位和數據。 數據可以是簡單的值或複雜的元素,例如清單和子集合。 文件會以唯一鍵值來擷取。
一般而言,檔包含單一實體的數據,例如客戶或訂單。 文件可能包含會分散在 RDBMS 中數個關聯式資料表的資訊。 檔不需要具有相同的結構。 應用程式可以在商務需求變更時,將不同的資料儲存在檔中。
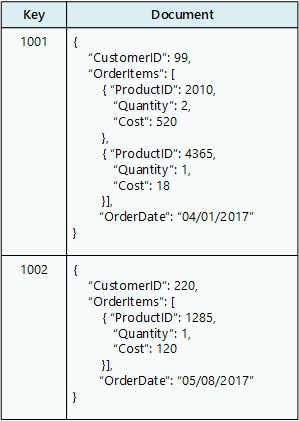
Azure 服務
工作量
- 插入和更新作業很常見。
- 沒有物件關聯阻抗不匹配。 檔可以更符合應用程式程式代碼中使用的物件結構。
- 個別檔會擷取並寫入為單一區塊。
- 數據需要多個字段的索引。
數據類型
- 資料可以以非正規化的方式進行管理。
- 個別文件數據的大小相對較小。
- 每個檔案類型都可以使用自己的架構。
- 檔可以包含選擇性欄位。
- 文件數據是半結構化的,這表示不會嚴格定義每個欄位的數據類型。
例子
- 產品目錄
- 內容管理
- 清查管理
圖形資料庫
圖形資料庫會儲存兩種類型的信息、節點和邊緣。 邊緣會指定節點之間的關聯性。 節點和邊緣可以有屬性,可提供該節點或邊緣的相關信息,類似於數據表中的數據行。 邊緣也可以有指示關聯性本質的方向。
圖形資料庫可以有效率地跨節點和邊緣網路執行查詢,並分析實體之間的關聯性。 下圖顯示結構化為圖表的組織人員資料庫。 實體是員工和部門,邊緣表示報告關聯性,以及員工工作所在的部門。
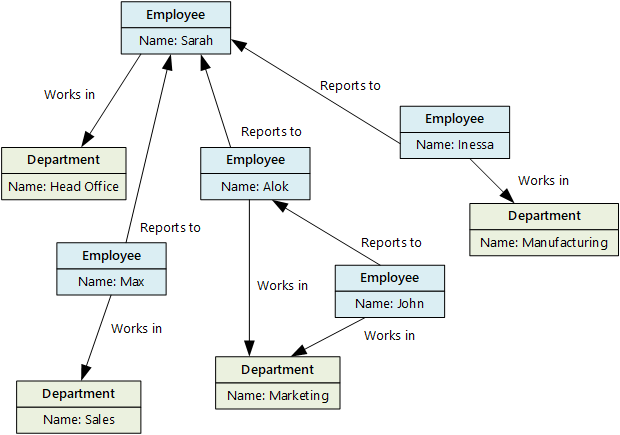
此結構可讓您直接執行查詢,例如「尋找直接或間接向 Sarah 回報的所有員工」或「誰在與 John 同一個部門工作?對於具有許多實體和關聯性的大型圖表,您可以非常快速地執行非常複雜的分析。 許多圖形資料庫都提供查詢語言,可讓您用來有效率地周遊關聯性網路。
Azure 服務
工作量
- 涉及多個相關數據項之間存在許多跳躍的複雜關係。
- 數據項之間的關聯性是動態的,而且會隨著時間而變更。
- 對象之間的關聯性是一流的公民,不需要外鍵和聯結才能周遊。
數據類型
- 節點和關聯性。
- 節點類似於數據表數據列或 JSON 檔。
- 關係與節點一樣重要,而且會直接在查詢語言中公開。
- 複合物件,例如具有多個電話號碼的人,通常會被分成個別且較小的節點,並結合可遍歷的關聯性。
例子
- 組織結構
- 社交圖表
- 詐騙偵測
- 建議引擎
數據分析
數據分析存放區提供大規模並行方案,用來引入、儲存以及分析資料。 數據會分散到多部伺服器,以最大化延展性。 大型數據檔格式,例如分隔符檔案(CSV)、parquet和 ORC,都廣泛使用在數據分析中。 歷程記錄數據通常會儲存在 Blob 記憶體或 Azure Data Lake Storage Gen2等數據存放區中,然後 Azure Synapse、Databricks 或 HDInsight 會以外部數據表的形式存取。 在一篇標題為 使用外部數據表搭配 Synapse SQL的文章中,描述了如何使用儲存為 parquet 檔案的數據來提升效能的一般情況。
Azure 服務
- Azure Synapse Analytics | (安全性基準)
- Azure Data Lake | (安全性基準)
- Azure 資料總管 | (安全性基準)
- Azure Analysis Services
- HDInsight | (安全性基準)
- Azure Databricks | (安全性基準)
工作量
- 數據分析
- 企業 BI
數據類型
- 來自多個來源的歷程記錄數據。
- 通常以「星形」或「雪花」架構反正規化,其中包含事實和維度數據表。
- 通常會以排程方式載入新數據。
- 維度數據表通常包含實體的多個歷史版本,稱為 緩時變更維度。
例子
- 企業數據倉儲
列族資料庫
數據列系列資料庫會將數據組織成數據列和數據行。 以最簡單的形式,列族資料庫至少在概念上顯得相當相似於關係資料庫。 列族資料庫的真正威力在於其針對稀疏數據的反正規化結構化方法。
您可以將數據行系列資料庫視為使用數據列和數據行來存放表格式數據,但是數據行會分成稱為 數據行系列的群組。 每個欄位族都會保存一組具有邏輯相關性的欄位,通常作為一個單位來擷取或操作。 其他個別存取的數據可以儲存在個別的數據行系列中。 在數據行系列中,可以動態加入新的數據行,而且數據列可能比較疏鬆(也就是說,每個數據行不需要有值)。
下圖顯示兩個列族 Identity 和 Contact Info的範例。 單一實體的數據在每個數據行系列中都有相同的數據列索引鍵。 這個結構,其中數據行系列中任何指定對象的數據列可以動態變化,是數據行系列方法的重要優點,因此這種數據存放區非常適合儲存結構化、揮發性數據。
列族資料庫圖表 
與索引鍵/值存放區或文件資料庫不同,大部分的數據行系列資料庫會以索引鍵順序儲存數據,而不是藉由計算哈希。 許多實作可讓您在數據行系列中建立特定數據行的索引。 索引可讓您依據列值擷取數據,而不是依據行鍵。
一個行的讀取和寫入操作通常是單一列族的原子性,儘管某些實作提供整個行的原子性,跨越多個列族。
Azure 服務
工作量
- 大部分的數據行系列資料庫都會非常快速地執行寫入作業。
- 更新和刪除作業很少見。
- 專為提供高輸送量和低延遲存取而設計。
- 支援對於大型記錄中的特定欄位集進行輕鬆的查詢存取。
- 具大規模擴展性。
數據類型
- 數據會儲存在由索引鍵數據行和一或多個數據行系列組成的數據表中。
- 特定數據行可能會因個別數據列而有所不同。
- 個別儲存格可透過 get 和 put 命令來存取
- 使用掃描命令傳回多個數據列。
例子
- 建議
- 個人化
- 感測器數據
- 遙測
- 訊息傳送
- 社交媒體分析
- Web 分析
- 活動監視
- 天氣和其他時間序列數據
搜尋引擎資料庫
搜尋引擎資料庫可讓應用程式搜尋外部資料存放區中保留的資訊。 搜尋引擎資料庫可以編製大量數據的索引,並提供這些索引的近乎即時存取。
索引可以是多維度的,並且可支援跨大量文字資料的全文搜尋。 您可以使用由搜尋引擎資料庫觸發的提取模型,或使用外部應用程式程式代碼所起始的推送模型來執行索引編製。
搜尋可以是精確或模糊的。 模糊搜尋會尋找符合一組字詞的檔,並計算其相符程度。 有些搜尋引擎也支援語言分析,可以根據同義字返回匹配項目、類型擴展(例如,將 dogs 與 pets進行匹配),以及詞幹分析(匹配同根詞)。
Azure 服務
工作量
- 來自多個來源和服務的數據索引。
- 查詢是臨機操作的,而且可能很複雜。
- 必須進行全文搜尋。
- 需要即時自助查詢。
數據類型
- 半結構化或非結構化文字
- 具有結構化數據的參考文字
例子
- 產品目錄
- 網站搜尋
- 伐木
時間序列資料庫
時間序列數據是依時間組織的一組值。 時間序列資料庫通常會從大量來源即時收集大量數據。 更新很少見,而且刪除通常以大量作業進行。 雖然寫入時間序列資料庫的記錄通常很小,但通常會有大量的記錄,而且數據大小總計可能會快速成長。
Azure 服務
工作量
- 記錄通常會依時間順序循序附加。
- 壓倒性比例(95-99%)的操作是寫入。
- 更新很少見。
- 批量刪除會針對連續的區塊或記錄進行。
- 數據會依序以遞增或遞減的時間順序讀取,通常是平行讀取。
數據類型
- 時間戳會當做主鍵和排序機制使用。
- 標籤可以定義有關類型、來源和其他相關資訊的附加信息。
例子
- 監視和事件遙測。
- 感測器或其他IoT數據。
物件記憶體
物件儲存已針對儲存和擷取大型二進位物件優化(影像、檔案、視訊和音訊數據流、大型應用程式數據物件和檔、虛擬機磁碟映像)。 此模型中也經常使用大型資料檔,例如分隔符檔案 (CSV)、parquet,以及 ORC。 物件存放區可以管理極其大量的非結構化數據。
Azure 服務
工作量
- 依鑰匙識別。
- 內容通常是資產,例如分隔符、影像或視訊檔案。
- 內容必須持久且外部於任何應用層。
數據類型
- 數據大小很大。
- 價值是不透明的。
例子
- 影像、影片、辦公室檔、PDF
- 靜態 HTML、JSON、CSS
- 日誌和稽核檔案
- 資料庫備份
共用檔案
有時候,使用簡單的一般檔案是儲存和擷取資訊最有效的方法。 使用檔案共用可讓檔案透過網路存取。 基於適當的安全性和並行訪問控制機制,以這種方式共用數據可讓分散式服務提供高度可調整的數據存取,以執行基本、低階的作業,例如簡單的讀取和寫入要求。
Azure 服務
工作量
- 從與檔案系統互動的現有應用程式移轉。
- 需要SMB介面。
數據類型
- 階層式資料夾中的檔案。
- 可透過標準 I/O 鏈接庫存取。
例子
- 舊版檔案
- 一些 VM 或應用程式實例之間可存取的共享內容
為了瞭解不同的數據儲存模型,下一個步驟是評估您的工作負載和應用程式,並決定哪些數據存放區符合您的特定需求。 使用 資料儲存判定樹 來協助此過程。
後續步驟
- Azure 雲端記憶體解決方案和服務
- 檢閱您的記憶體選項
- Azure 儲存體
簡介 - Azure 資料探索者 簡介