使用 LangChain 和 Azure AI Foundry 開發應用程式
LangChain 是一種開發生態系統,可讓開發人員盡可能輕鬆地建置原因的應用程式。 生態系統是由多個元件所組成。 大部分都可供自己使用,讓您挑選並選擇您最喜歡的元件。
部署至 Azure AI Foundry 的模型可以搭配 LangChain 使用兩種方式:
使用 Azure AI 模型推斷 API: 部署至 Azure AI Foundry 的所有模型都支援 Azure AI 模型推斷 API,其提供一組常見的功能,可用於目錄中大部分的模型。 此 API 的優點是,由於對所有模型來說都相同,因此從一個模型變更為另一個模型,就像變更正在使用的模型部署一樣簡單。 程式碼中不需要進一步的變更。 使用 LangChain 時,請安裝延伸模組
langchain-azure-ai。使用模型的提供者特定 API:部分模型 (例如 OpenAI、Cohere 或 Mistral) 提供一組自己的 API 和 LlamaIndex 延伸模組。 這些延伸模組可能包含模型支援的特定功能,因此您可以視需要加以利用。 使用 LangChain 時,請安裝您要使用之模型的特定擴充功能,例如
langchain-openai或langchain-cohere。
在本教學課程中,您將瞭解如何使用套件 langchain-azure-ai 來使用 LangChain 建置應用程式。
必要條件
若要執行此教學課程,您需要:
支援已部署 Azure AI 模型推斷 API 的模型部署。 在此範例中,我們會在
Mistral-Large-2407Azure AI 模型推斷中使用部署。已安裝 Python 3.9 或更新版本,包括 pip。
已安裝 LangChain。 您可以透過下列方式來完成:
pip install langchain-core在此範例中,我們將使用 Azure AI 模型推斷 API,因此我們安裝下列套件:
pip install -U langchain-azure-ai
設定環境
若要使用部署在 Azure AI Foundry 入口網站中的 LLM,您需要端點和認證才能連線到它。 請遵循下列步驟,從您想要使用的模型取得所需的資訊:
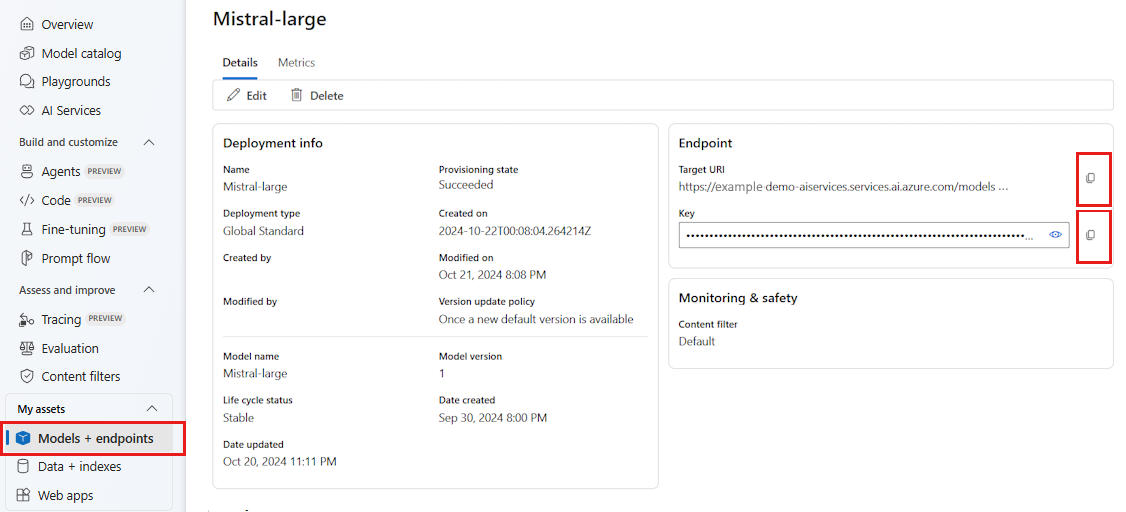
移至 Azure AI Foundry。
如果尚未開啟模型,請開啟部署模型的專案。
移至 [模型 + 端點 ],然後選取您部署的模型,如必要條件中所述。
複製端點 URL 和金鑰。
提示
如果您的模型已使用 Microsoft Entra ID 支援部署,則不需要金鑰。

在此案例中,我們將端點 URL 和金鑰放在下列環境變數中:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
設定好之後,請建立用戶端以連線到端點。 在此情況下,我們會使用聊天完成模型,因此我們會匯入 類別 AzureAIChatCompletionsModel。
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model="mistral-large-2407",
)
提示
針對 Azure OpenAI 模型,請設定用戶端,如使用 Azure OpenAI 模型中所述。
如果您的端點支援 Microsoft Entra ID,您可以使用下列程式代碼來建立用戶端:
import os
from azure.identity import DefaultAzureCredential
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model_name="mistral-large-2407",
)
注意
使用 Microsoft Entra ID 時,請確定端點是以該驗證方法部署,而且您具有加以叫用所需的權限。
如果您打算使用非同步呼叫,最佳做法是針對認證使用非同步版本:
from azure.identity.aio import (
DefaultAzureCredential as DefaultAzureCredentialAsync,
)
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredentialAsync(),
model_name="mistral-large-2407",
)
如果您的端點提供一個模型,例如無伺服器 API 端點,則不需要指出 model_name 參數:
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
)
使用聊天完成模型
讓我們先直接使用模型。
ChatModels 是 LangChain Runnable的實例,這表示它們會公開標準介面來與其互動。 為了簡單地呼叫模型,我們可以將訊息清單傳遞至 invoke 方法。
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="Translate the following from English into Italian"),
HumanMessage(content="hi!"),
]
model.invoke(messages)
您也可以視需要在所謂的 鏈結中撰寫作業。 現在讓我們使用提示範本來翻譯句子:
from langchain_core.output_parsers import StrOutputParser
system_template = "Translate the following into {language}:"
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
如您在提示範本中看到,此鏈結具有 language 和 text 輸入。 現在,讓我們建立輸出剖析器:
from langchain_core.prompts import ChatPromptTemplate
parser = StrOutputParser()
我們現在可以使用管道 (|) 運算子,結合上述的範本、模型和輸出剖析器:
chain = prompt_template | model | parser
若要叫用 invoke 鏈結,請使用 方法來識別所需的輸入,並提供值:
chain.invoke({"language": "italian", "text": "hi"})
'ciao'
將多個 LLM 鏈結在一起
部署到 Azure AI Foundry 的模型支援 Azure AI 模型推斷 API,這是所有模型的標準。 根據每個模型的功能鏈結多個 LLM 作業,讓您可以根據功能針對正確的模型進行優化。
在下列範例中,我們會建立兩個模型用戶端,一個是生產者,另一個是驗證程式。 為了清楚辨別,我們使用多模型端點,例如 Azure AI 模型推斷服務,因此我們會傳遞 參數model_name來使用 Mistral-Large 和 Mistral-Small 模型,並引用產生內容比驗證內容更複雜的事實。
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
producer = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2407",
)
verifier = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-small",
)
提示
探索每個模型的模型卡片,以瞭解每個模型的最佳使用案例。
下列範例會產生由城市詩人撰寫的詩:
from langchain_core.prompts import PromptTemplate
producer_template = PromptTemplate(
template="You are an urban poet, your job is to come up \
verses based on a given topic.\n\
Here is the topic you have been asked to generate a verse on:\n\
{topic}",
input_variables=["topic"],
)
verifier_template = PromptTemplate(
template="You are a verifier of poems, you are tasked\
to inspect the verses of poem. If they consist of violence and abusive language\
report it. Your response should be only one word either True or False.\n \
Here is the lyrics submitted to you:\n\
{input}",
input_variables=["input"],
)
現在讓我們鏈結這些片段:
chain = producer_template | producer | parser | verifier_template | verifier | parser
上一個鏈結只會傳回步驟 verifier 的輸出。 由於我們想要存取 所產生的 producer中繼結果,在 LangChain 中,您必須使用 RunnablePassthrough 對象來輸出該中繼步驟。 下列程式代碼示範如何執行:
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
generate_poem = producer_template | producer | parser
verify_poem = verifier_template | verifier | parser
chain = generate_poem | RunnableParallel(poem=RunnablePassthrough(), verification=RunnablePassthrough() | verify_poem)
若要叫用 invoke 鏈結,請使用 方法來識別所需的輸入,並提供值:
chain.invoke({"topic": "living in a foreign country"})
{
"peom": "...",
"verification: "false"
}
使用內嵌模型
同樣地,您可以建立 LLM 用戶端,連線到內嵌模型。 在下列範例中,我們會將環境變數設定至現在指向內嵌模型:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
接著,建立用戶端物件:
from langchain_azure_ai.embeddings import AzureAIEmbeddingsModel
embed_model = AzureAIEmbeddingsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ['AZURE_INFERENCE_CREDENTIAL'],
model_name="text-embedding-3-large",
)
下列範例示範使用記憶體中向量存放區的簡單範例:
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embed_model)
讓我們新增一些檔:
from langchain_core.documents import Document
document_1 = Document(id="1", page_content="foo", metadata={"baz": "bar"})
document_2 = Document(id="2", page_content="thud", metadata={"bar": "baz"})
documents = [document_1, document_2]
vector_store.add_documents(documents=documents)
讓我們以相似度搜尋:
results = vector_store.similarity_search(query="thud",k=1)
for doc in results:
print(f"* {doc.page_content} [{doc.metadata}]")
使用 Azure OpenAI 模型
如果您使用 Azure OpenAI 服務或 Azure AI 模型推斷服務搭配 OpenAI 模型搭配 langchain-azure-ai 套件,您可能需要使用 api_version 參數來選取特定的 API 版本。 下列範例示範如何在 Azure OpenAI 服務中連線到 Azure OpenAI 模型部署:
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
llm = AzureAIChatCompletionsModel(
endpoint="https://<resource>.openai.azure.com/openai/deployments/<deployment-name>",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
api_version="2024-05-01-preview",
)
重要
檢查您的部署所使用的 API 版本。 使用錯誤或模型不支援的錯誤 api_version 會導致 ResourceNotFound 例外狀況。
如果部署裝載在 Azure AI 服務中,您可以使用 Azure AI 模型推斷服務:
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
llm = AzureAIChatCompletionsModel(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="<model-name>",
api_version="2024-05-01-preview",
)
偵錯和疑難排解
如果您需要對應用程式進行偵錯並了解傳送至 Azure AI Foundry 中模型的要求,您可以使用整合的偵錯功能,如下所示:
首先,將記錄設定為您感興趣的層級:
import sys
import logging
# Acquire the logger for this client library. Use 'azure' to affect both
# 'azure.core` and `azure.ai.inference' libraries.
logger = logging.getLogger("azure")
# Set the desired logging level. logging.INFO or logging.DEBUG are good options.
logger.setLevel(logging.DEBUG)
# Direct logging output to stdout:
handler = logging.StreamHandler(stream=sys.stdout)
# Or direct logging output to a file:
# handler = logging.FileHandler(filename="sample.log")
logger.addHandler(handler)
# Optional: change the default logging format. Here we add a timestamp.
formatter = logging.Formatter("%(asctime)s:%(levelname)s:%(name)s:%(message)s")
handler.setFormatter(formatter)
若要查看要求的承載,在具現化用戶端時,請將 自變數logging_enable=True傳遞至 :client_kwargs
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2407",
client_kwargs={"logging_enable": True},
)
如往常在程式代碼中使用用戶端。
追蹤
您可以藉由建立追蹤,在 Azure AI Foundry 中使用追蹤功能。 記錄會儲存在 Azure 應用程式 Insights 中,而且可以隨時使用 Azure 監視器或 Azure AI Foundry 入口網站進行查詢。 每個 AI 中樞都有與其相關聯的 Azure 應用程式 深入解析。
取得您的檢測 連接字串
您可以透過下列方式,將應用程式設定為將遙測傳送至 Azure 應用程式 Insights:
使用 連接字串 直接 Azure 應用程式 Insights:
移至 Azure AI Foundry 入口網站 ,然後選取 [ 追蹤]。
選取 [ 管理數據源]。 在此畫面中,您可以看到與專案相關聯的實例。
複製 [連接字串] 上的值,並將其設定為下列變數:
import os application_insights_connection_string = "instrumentation...."
使用 Azure AI Foundry SDK 和專案 連接字串。
請確定您已在環境中安裝套件
azure-ai-projects。複製專案的 連接字串,並設定下列程式代碼:
from azure.ai.projects import AIProjectClient from azure.identity import DefaultAzureCredential project_client = AIProjectClient.from_connection_string( credential=DefaultAzureCredential(), conn_str="<your-project-connection-string>", ) application_insights_connection_string = project_client.telemetry.get_connection_string()
設定 Azure AI Foundry 的追蹤
下列程式代碼會建立連線至 Azure AI Foundry 中專案後方的 Azure 應用程式 Insights 追蹤。 請注意,參數 enable_content_recording 設定為 True。 這可擷取整個應用程式的輸入和輸出,以及中繼步驟。 偵錯和建置應用程式時,這類方法很有用,但您可能想要在生產環境中停用它。 預設為環境變數 AZURE_TRACING_GEN_AI_CONTENT_RECORDING_ENABLED:
from langchain_azure_ai.callbacks.tracers import AzureAIInferenceTracer
tracer = AzureAIInferenceTracer(
connection_string=application_insights_connection_string,
enable_content_recording=True,
)
若要使用您的鏈結設定追蹤,請將作業中的 invoke 值設定指示為回呼:
chain.invoke({"topic": "living in a foreign country"}, config={"callbacks": [tracer]})
若要設定追蹤的鏈結本身,請使用 .with_config() 方法:
chain = chain.with_config({"callbacks": [tracer]})
然後像往常一樣使用 invoke() 方法:
chain.invoke({"topic": "living in a foreign country"})
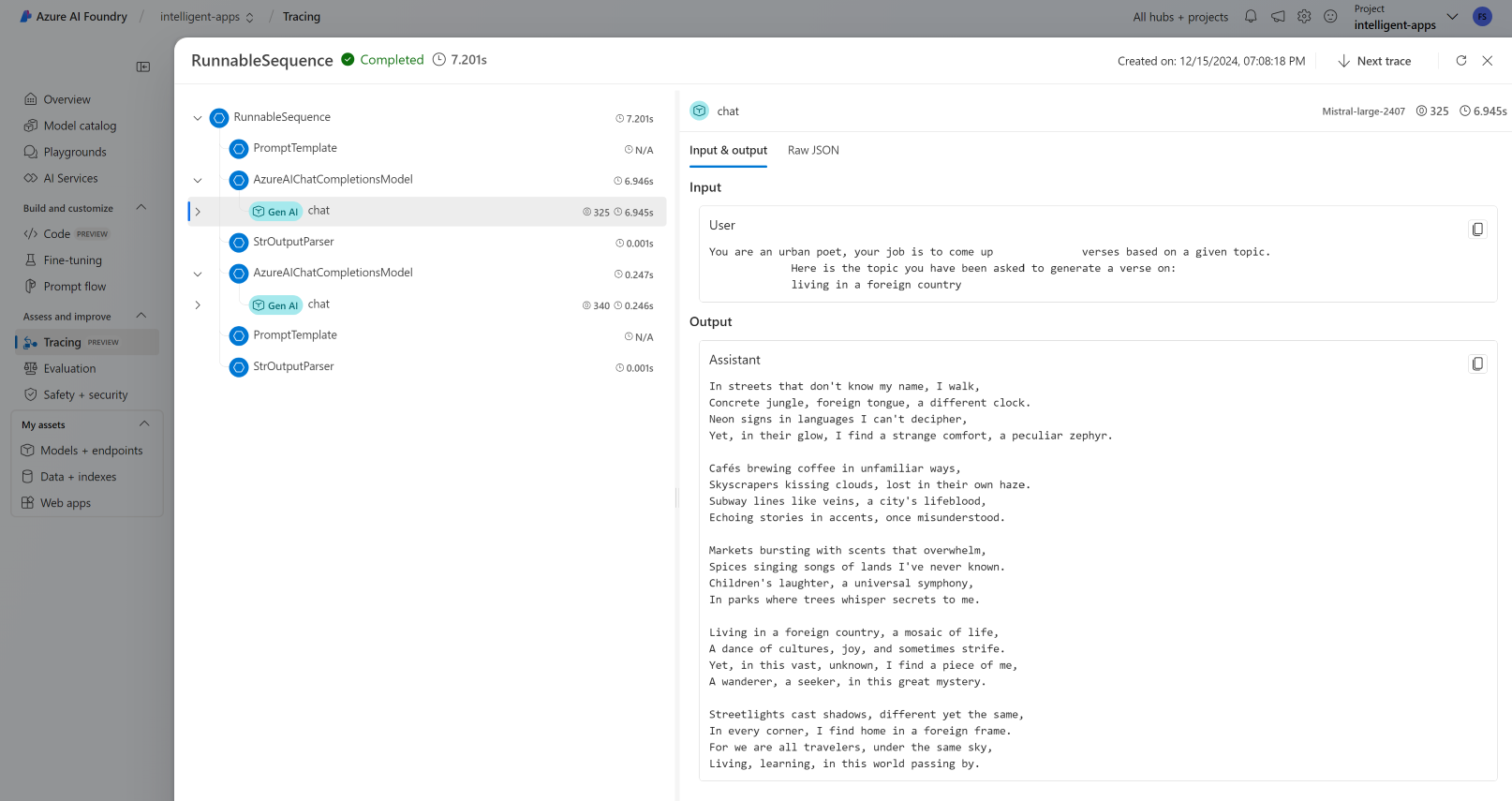
檢視追蹤
若要查看追蹤:
流覽至 [追蹤] 區段。
識別您已建立的追蹤。 追蹤可能需要幾秒鐘的時間才會顯示。

深入瞭解 如何可視化和管理追蹤。