使用 viseme 取得臉部位置
注意
若要探索 Viseme 識別碼和混合圖形所支援的地區設定,請參閱所有支援的地區設定清單。 僅 en-US 地區設定支援可調整向量圖形 (SVG)。
Viseme 能夠以視覺方式呈現出口說語言的音素。 Viseme 會在有人說話時定義臉部和嘴巴的位置。 每個 Viseme 都能為一組特定音素描繪出關鍵臉部姿勢。
您可以使用 visemes 來控制 2D 和 3D 虛擬人偶模型的移動,讓臉部位置與綜合語音能以最佳效果對齊。 例如,您可以:
- 為智慧型資訊亭建立動畫虛擬語音助理,為您的顧客建立多模式的整合服務。
- 透過自然臉部和嘴部的移動,打造出沉浸性新聞廣播並提升觀眾體驗。
- 產生更多互動式遊戲虛擬人偶和卡通人物,這些人物可以說出動態內容。
- 製作更有效的語言教學影片,協助語言學習者們瞭解每個單字和音素的正確嘴部動作。
- 聽障人士也可以透過視覺方式得悉聲音,在動畫的臉部上顯示發音嘴型,以「讀唇」方式理解語音內容。
如需 visemes 的詳細資訊,請檢視此簡介影片。
使用語音產生 viseme 的整體工作流程
類神經文字轉換語音 (類神經 TTS) 會將輸入文字或 SSML (語音合成標記語言) 轉換成逼真的合成語音。 語音音訊輸出可以伴隨 viseme 識別碼、可變式向量圖形 (SVG) 或混合圖形。 搭配使用 2D 或3D 轉譯引擎,您可以利用這些 Viseme 事件來為您的虛擬人偶製作動畫。
下列流程圖說明 Viseme 的整體工作流程:
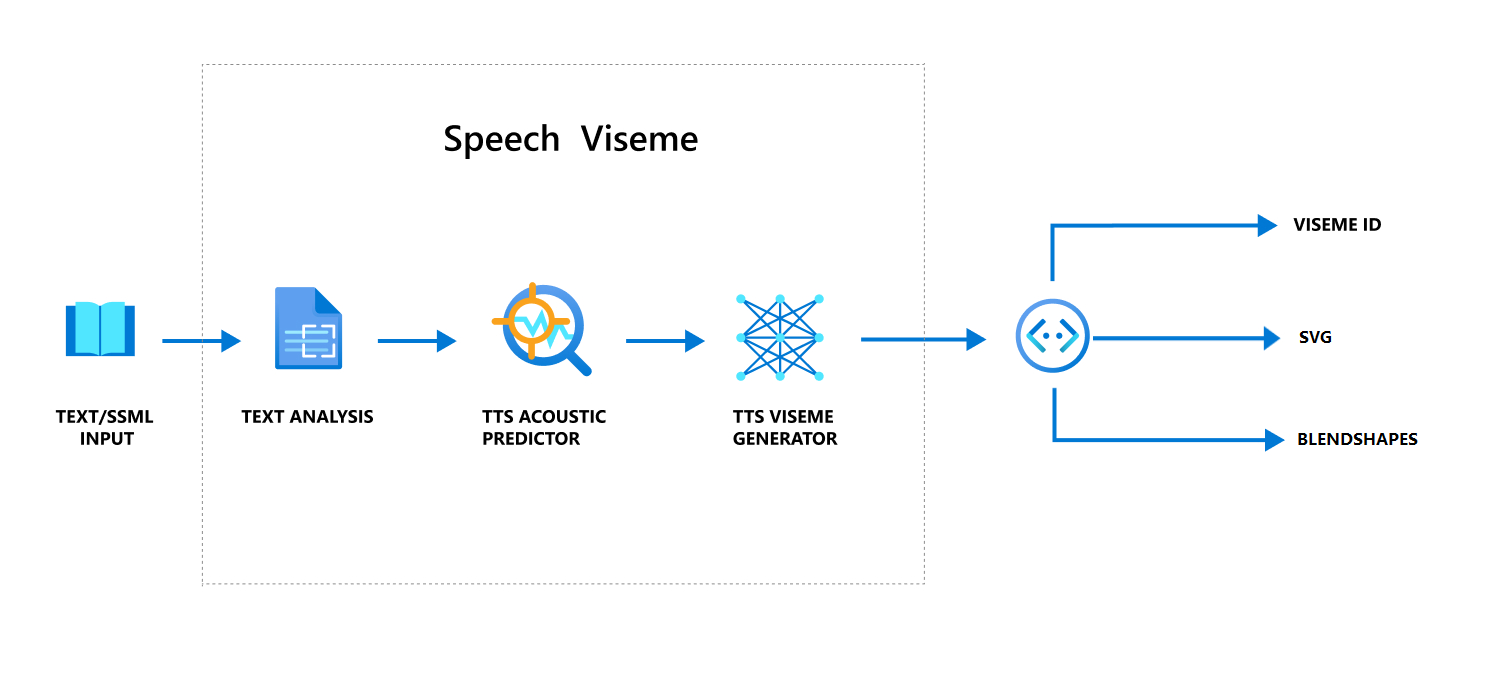
Viseme 識別碼
Viseme 識別碼是指定 viseme 的整數。 我們提供 22 種不同的 Visemes,分別描述特定一組音素的口部位置。 Viseme 與音素之間並沒有一對一的對應關係。 通常會有數個音素對應至單一 Viseme,這是因為這些音素在發音時說話者的臉部動作看起來是一樣的,例如 s 和 z。 如需特定詳細資訊,請參閱將將音素對應至 Viseme 識別碼的資料表。
語音音訊輸出會伴隨著 Viseme 識別碼及 Audio offset。 Audio offset 表示每個 viseme 開始時間的位移時間戳記,以刻度為單位 (100 奈秒)。
將音素對應至 Viseme
Visemes 會依語言和地區設定而有所不同。 每種地區設定都有一組對應到特定音素的 Viseme。 SSML 音標文件會將 viseme 識別碼對應至相對應的國際音標 (IPA) 音素。 此節中的表格顯示 Visemes 識別碼與口部位置之間的對應關聯性,列出每個 Visemes 識別碼的典型 IPA 音素。
| Viseme 識別碼 | IPA | 口部位置 |
|---|---|---|
| 0 | 靜音 |  |
| 1 | æ }, |
 |
| 2 | ɑ |
 |
| 3 | ɔ |
 |
| 4 | % |  |
| 5 | ɝ |
 |
| 6 | j }, |
 |
| 7 | % |  |
| 8 | o |
 |
| 9 | aʊ |
 |
| 10 | ɔɪ |
 |
| 11 | aɪ |
 |
| 12 | h |
 |
| 13 | ɹ |
 |
| 14 | l |
 |
| 15 | % |  |
| 16 |  |
|
| 17 | ð |
 |
| 18 | % |  |
| 19 |  |
|
| 20 | k }, |
 |
| 21 | p }, |
 |
2D SVG 動畫
針對 2D 角色,您可以設計符合您使用情境的角色,並針對每個 Viseme 識別碼使用可調整向量圖形 (SVG),藉此取得以時間為基礎的臉部位置。
藉助 Viseme 事件提供的時態性標記,這些設計完善的 SVG 將會接受平滑性修改處理,為使用者提供生動的動畫。 例如,下圖顯示專為語言學習而設計的紅唇角色。

3D 混合圖形動畫
您可以使用混合圖形來驅動您設計的 3D 字元臉部移動。
混合圖形 JSON 字串會以 2 維矩陣表示。 每一列代表一個畫面格。 每個畫面格 (在 60 FPS 中) 包含 55 個臉部位置的陣列。
以語音 SDK 取得 Viseme 事件
若要為您的合成語音取得 viseme,請訂閱語音 SDK 中的 VisemeReceived 事件。
注意
若要要求 SVG 或混合圖形輸出,您應該使用 SSML 中的 mstts:viseme 元素。 如需詳細資訊,請參閱如何在 SSML 中使用 viseme 元素。
下列程式碼片段展示了如何訂閱 Viseme 事件:
using (var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig))
{
// Subscribes to viseme received event
synthesizer.VisemeReceived += (s, e) =>
{
Console.WriteLine($"Viseme event received. Audio offset: " +
$"{e.AudioOffset / 10000}ms, viseme id: {e.VisemeId}.");
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
var result = await synthesizer.SpeakSsmlAsync(ssml);
}
auto synthesizer = SpeechSynthesizer::FromConfig(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer->VisemeReceived += [](const SpeechSynthesisVisemeEventArgs& e)
{
cout << "viseme event received. "
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
<< "Audio offset: " << e.AudioOffset / 10000 << "ms, "
<< "viseme id: " << e.VisemeId << "." << endl;
// `Animation` is an xml string for SVG or a json string for blend shapes
auto animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
auto result = synthesizer->SpeakSsmlAsync(ssml).get();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.VisemeReceived.addEventListener((o, e) -> {
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
System.out.print("Viseme event received. Audio offset: " + e.getAudioOffset() / 10000 + "ms, ");
System.out.println("viseme id: " + e.getVisemeId() + ".");
// `Animation` is an xml string for SVG or a json string for blend shapes
String animation = e.getAnimation();
});
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
SpeechSynthesisResult result = synthesizer.SpeakSsmlAsync(ssml).get();
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def viseme_cb(evt):
print("Viseme event received: audio offset: {}ms, viseme id: {}.".format(
evt.audio_offset / 10000, evt.viseme_id))
# `Animation` is an xml string for SVG or a json string for blend shapes
animation = evt.animation
# Subscribes to viseme received event
speech_synthesizer.viseme_received.connect(viseme_cb)
# If VisemeID is the only thing you want, you can also use `speak_text_async()`
result = speech_synthesizer.speak_ssml_async(ssml).get()
var synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.visemeReceived = function (s, e) {
window.console.log("(Viseme), Audio offset: " + e.audioOffset / 10000 + "ms. Viseme ID: " + e.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.animation;
}
// If VisemeID is the only thing you want, you can also use `speakTextAsync()`
synthesizer.speakSsmlAsync(ssml);
SPXSpeechSynthesizer *synthesizer =
[[SPXSpeechSynthesizer alloc] initWithSpeechConfiguration:speechConfig
audioConfiguration:audioConfig];
// Subscribes to viseme received event
[synthesizer addVisemeReceivedEventHandler: ^ (SPXSpeechSynthesizer *synthesizer, SPXSpeechSynthesisVisemeEventArgs *eventArgs) {
NSLog(@"Viseme event received. Audio offset: %fms, viseme id: %lu.", eventArgs.audioOffset/10000., eventArgs.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
NSString *animation = eventArgs.Animation;
}];
// If VisemeID is the only thing you want, you can also use `SpeakText`
[synthesizer speakSsml:ssml];
以下是 Viseme 輸出的範例。
(Viseme), Viseme ID: 1, Audio offset: 200ms.
(Viseme), Viseme ID: 5, Audio offset: 850ms.
……
(Viseme), Viseme ID: 13, Audio offset: 2350ms.
取得 Viseme 輸出之後,您可以使用這些事件來為角色繪製動畫。 您可以建立自己的角色,並自動為這些角色建立動畫。