什麼是自訂語音?
有了 自訂語音,您即可評估與提高應用程式和產品的語音辨識精確度。 自訂語音模型可用於即時語音轉換文字、語音翻譯和批次謄寫。
開箱即用的語音辨識功能運用通用語言模型作為基礎模型。這個功能是以 Microsoft 擁有的資料定型,且能夠反映常用的口語語言。 基礎模型會預先定型,其中包含代表各種常見網域的方言和注音符號。 當您提出語音辨識要求時,系統預設會使用每個支援語言的最新基礎模型。 基礎模型在大部分的語音辨識案例中運作良好。
自訂模型可用於增強基礎模型,藉由提供文字資料來定型模型,以改善應用程式特有領域限定的詞彙辨識。 它也可以藉由提供音訊資料與參考轉錄內容,來改善應用程式特定音訊條件的辨識。
您也可以在資料遵循模式時使用結構化文字定型模型,以指定自訂發音,以及使用自訂反向文字正規化、自訂重寫和自訂不雅內容篩選來自訂顯示文字格式。
如何運作?
有了自訂語音後,您就可以上傳自己的資料、測試與定型自訂模型、比較模型之間的精確度,以及將模型部署至自訂端點。
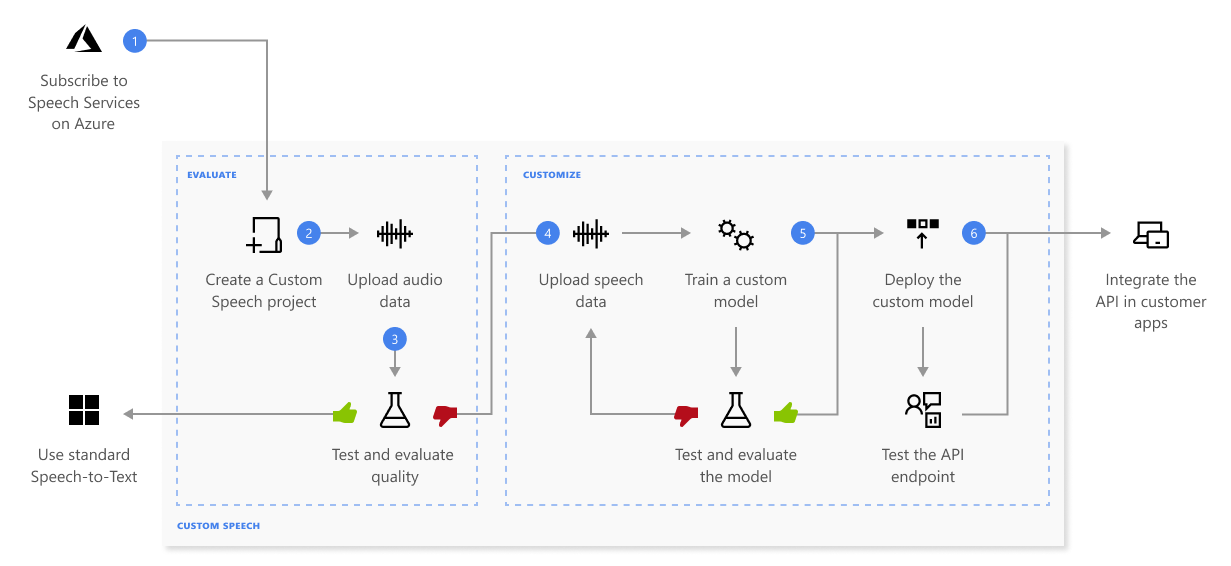
如需有關上圖步驟順序的詳細資訊,請參閱以下內容:
- 建立專案並選擇模型。 使用您在 Azure 入口網站中建立的語音資源。 如果您使用音訊數據來定型自定義模型,請選擇語音區域的 AI Services 資源,並搭配專用硬體來定型音訊數據。 如需詳細資訊,請參閱區域資料表中的註腳。
- 上傳測試資料。 上傳測試資料以評估您應用程式、工具和產品的語音轉換文字供應項目。
- 測試辨識品質。 使用 Speech Studio 播放上傳的音訊,並檢查測試資料的語音辨識品質。
- 以量化方式測試模型。 評估及提高語音轉換文字模型的精確度。 語音服務會提供以量化方式執行的字詞錯誤率 (WER),以便您判斷是否需要其他定型。
-
將模型定型。 提供書面文字轉錄內容與相關文字,以及對應的音訊資料。 您可以自由選擇是否要在定型前後測試模型,但建議進行這個步驟。
注意
會根據自訂語音模型使用量和端點託管向您收取費用。 如果基底模型是在 2023 年 10 月 1 日及以後建立的,則還會向您收取自訂語音模型訓練的費用。 如果基底模型是在 2023 年 10 月之前建立的,則不會向您收取訓練費用。 如需詳細資訊,請參閱 Azure AI 語音價格和語音轉換文字 3.2 遷移指南中的採用價格部分。
- 部署模型。 若您滿意測試結果,即可將模型部署至自訂端點。 除了批次謄寫外,您必須部署自訂端點以使用自訂語音模型。
負責 AI
AI 系統不僅包含技術,也包含使用該技術的人員、受其影響的人員及部署的環境。 閱讀透明度資訊,了解在系統中負責任 AI 的使用和部署資訊。