評估特徵重要度
重要
從 2023 年 9 月 20 日起,您將無法建立新的個人化工具資源。 個人化工具服務將於 2026 年 10 月 1 日淘汰。
您可以藉由對歷程記錄資料進行特徵評估,來評估每個特徵對個人化工具機器學習模型的重要度。 特徵評估適合用於:
- 了解對模型最重要或最不重要的特徵。
- 藉由從模型中目前重要的特徵衍生靈感,腦力激盪出可能有助於學習的額外特徵。
- 找出應該考慮進一步分析或移除的可能不重要或非實用特徵。
- 針對設計特徵並將其傳送至個人化工具時可能發生的常見問題和錯誤疑難排解。 例如,使用 GUID、時間戳記或其他一般疏鬆的特徵可能會有問題。 深入了解改善特徵。
什麼是特徵評估?
特徵評估是透過針對指定時段內收集的記錄資料定型並執行目前模型設定的複本來進行。 一次會忽略一個特徵,以測量在含有與不含每個特徵時模型效能的差異。 由於特徵評估是依據歷史資料執行,因此無法保證將在未來料中觀察到這些模式。 不過,如果您的記錄資料已擷取資料的足夠變異性或非固定屬性,這些深入解析可能仍與未來資料相關。 您目前的模型效能不會受到執行特徵評估的影響。
特徵重要度分數是對評估期間獎勵特徵的相對影響量值。 特徵重要度分數是介於 0 (最不重要) 和 100 (最重要) 之間的數字,而且會在特徵評估中顯示。 由於評估會針對特定時段執行,隨著其他資料傳送至個人化工具,以及隨著您的使用者、案例和資料隨時間變更,特徵重要度可能會變更。
建立特徵評估
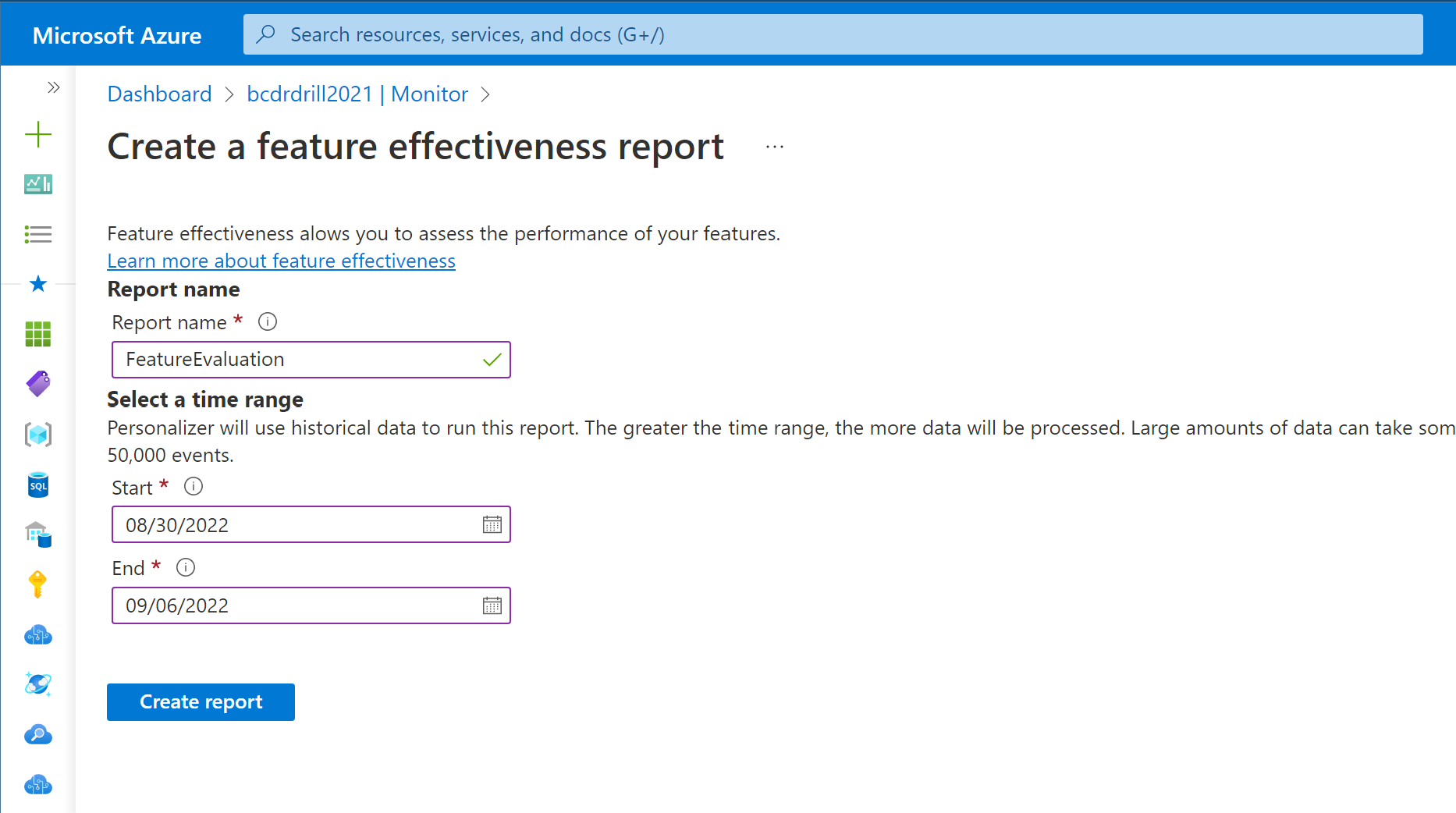
若要取得特徵重要度分數,您必須對一段時間記錄的資料建立特徵評估,以產生包含特徵重要度分數的報表。 此報表可在 Azure 入口網站中檢視。 若要建立特徵評估:
- 移至 Azure 入口網站網站
- 選取您的個人化工具資源
- 從側邊瀏覽窗格選取 [監視] 區段
- 選取 [特徵] 索引標籤
- 選取 [建立報表],新畫面應該會顯示
- 選擇報表的名稱
- 選擇評估期間的 [開始] 和 [結束] 時間
- 選取 [建立報表]
![顯示如何在透過按一下 [監視] 刀鋒視窗、[特徵] 索引標籤,然後按一下 [建立報表],在個人化工具資源中建立特徵評估的螢幕擷取畫面。](media/feature-evaluation/create-report.png)
接下來,您的報表名稱應該會出現在下表中。 建立特徵評估是長時間執行的程序,其完成時間取決於評估期間傳送給個人化工具的資料量。 產生報表時,[狀態] 資料行會指出評估「執行中」,且會在完成之後更新為「成功」。 定期回來查看您的評估是否已完成。
您可以在個人化工具資源具有記錄資料的各種時段期間執行多個特徵評估。 請確定您的資料保留期間已設為足夠長的時間,讓您能夠對較舊的資料執行評估。
解譯特徵重要度分數
具有高重要度分數的特徵
相較於其他特徵,具有較高重要度分數的特徵在評估期間對模型更具影響力。 重要特徵可提供設計要包含在模型中其他特徵的靈感。 例如,如果您看到內容功能 「IsWeekend」 或 「IsWeekday」 對雜貨店購物具有很高的重要性,則可能是假日或長週末可能也是重要因素,因此您可能想要考慮新增可擷取此資訊的功能。
具有低重要度分數的特徵
具有低重要度分數的特徵是進一步分析的良好候選項目。 並非所有低分數的特徵都不好或不實用,因為低分數可能會因為一或多個原因而發生。 下列清單可協助您開始分析特徵可能有低分數的原因:
在評估期間,在資料中很少觀察到該特徵。
- 如果此特徵的出現次數相較於其他特徵來得低,這可能表示特徵的出現次數通常不夠,無法讓模型判斷是否重要。
特徵值沒有許多多樣性或變化。
- 如果此特徵的唯一值數目低於您的預期,這可能表示此特徵在評估期間沒有太大變化,因此不會提供顯著的深入解析。
特徵值太多雜訊 (隨機) 或太相異,且提供較少的值。
- 檢查特徵評估中的唯一值數目。 如果此特徵的唯一值數目高於您的預期,或相較於其他特徵來得高,這可能表示該特徵在評估期間有太多雜訊。
具有資料或格式問題。
- 檢查以確定特徵已格式化,並以您預期的方式傳送至個人化工具。
如果特徵分數很低,且上述原因不適用,則該特徵對於模型學習和效能可能不重要。
- 考慮移除此特徵,因為其無助於模型將平均獎勵最大化。
移除具有低重要度分數的特徵可透過減少需要學習的資料量,協助加速模型定型。 其也可能會改善模型的效能。 不過,這並非保證且可能需要進一步的分析。 深入了解如何設計內容和動作特徵。
常見問題和改善特徵的步驟
傳送具有高基數的特徵。 具有高基數的特徵是具有許多相異值,其不一定會對許多事件重複。 例如,單一個人特定的個人資訊 (例如姓名、電話號碼、信用卡號碼、IP 位址) 不應與個人化工具搭配使用。
傳送使用者識別碼:對於大量使用者而言,此資訊不太可能與個人化工具學習來將平均獎勵分數最大化有關。 傳送使用者識別碼 (即使是非個人資訊) 可能會對模型新增更多雜訊,因此不建議這麼做。
特徵太疏鬆。 值相異且很少發生多次. 將精確時間戳記向下至秒可能會非常疏鬆。 可以使其更密集 (因此有效),例如,您可以將時間分組為「上午」、「中午」或「下午」。
位置資訊通常也可因建立更廣泛的分類而受益。 例如,經緯度座標 (例如緯度:47.67402° N、經度:122.12154° W) 太過精確,會強制模型將緯度和經度視為相異維度來學習。 當您嘗試根據位置資訊進行個人化時,這有助於將位置資訊分組在較大的磁區中。 為此有個簡單的方法,就是為經緯度數值選擇適當的捨入精確度,並將緯度和經度變成一個字串,以將其合併到「區域」中。 例如,在大約數公里寬的區域中表示緯度:47.67402° N,經度:122.12154° W 的恰當方法,是 "location":"34.3 , 12.1"。
- 使用類推的資訊擴大特性集合 您也可以想想有沒有尚未探索到的屬性可以從您已經擁有的資訊來衍生,從而獲得更多的特徵。 例如,在進行虛構電影清單的個人化作業時,週末和平日是否可能會得到不同的使用者行為? 您可以擴充時間來獲得「週末」或「平日」屬性。 與文化有關的國定/區域假日是否會讓人們關注某些電影類型? 例如,「萬聖節」屬性在與其相關的地點便很有用。 雨天是否可能會對許多人在選擇電影時造成重大影響? 使用時間和地點,天氣服務便可以提供該資訊,您也可以將其新增為額外的特性。
下一步
使用個人化工具運用離線評估來分析原則效能。