開始使用 Azure OpenAI 批次部署
Azure OpenAI Batch API 的設計目的是要有效率地處理大規模和大量處理工作。 以個別配額處理要求的非同步群組 (目標往返時間為 24 小時),且成本比全域標準低 50%。 使用批次處理時,不是一次傳送一個要求,而是在單一檔案中傳送大量要求。 全域批次要求有個別加入佇列的權杖配額,可避免任何線上工作負載中斷。
關鍵使用案例包括:
大規模資料處理:以平行方式快速分析廣泛的資料集。
內容產生:建立大量文字,例如產品描述或文章。
文件檢閱和摘要:自動檢閱和摘要冗長文件。
客戶支援自動化:同時處理許多查詢,以更快做出回應。
資料擷取和分析:從大量的非結構化資料擷取和分析資訊。
自然語言處理 (NLP) 工作:在大型資料集上執行情感分析或翻譯等工作。
行銷與個人化:大規模產生個人化內容和建議。
重要
我們的目標是在 24 小時內處理批次要求,超過時間的作業不會到期。 您可以隨時取消作業。 當您取消作業時,會取消任何剩餘的工作,並傳回任何已完成的工作。 您需支付任何已完成的工作費用。
儲存的待用資料會保留在指定的 Azure 地理位置中,同時可能會在任何 Azure OpenAI 位置中處理資料進行推斷。 深入了解資料落地。
批次支援
全域批次模型可用性
| 區域 | o3-mini, 2025-01-31 | gpt-4o,2024-05-13 | gpt-4o,2024-08-06 | gpt-4o, 2024-11-20 | gpt-4o-mini, 2024-07-18 | gpt-4,0613 | gpt-4,turbo-2024-04-09 | gpt-35-turbo,0613 | gpt-35-turbo,1106 | gpt-35-turbo,0125 |
|---|---|---|---|---|---|---|---|---|---|---|
| australiaeast | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| brazilsouth | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| canadaeast | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| eastus | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| eastus2 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| francecentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| germanywestcentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| japaneast | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| koreacentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| northcentralus | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| norwayeast | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| polandcentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southafricanorth | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southcentralus | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southindia | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| swedencentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| switzerlandnorth | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| uksouth | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westeurope | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westus | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westus3 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
需要註冊才能存取 o3-mini。 如需詳細資訊,請參閱我們的 推理模型指南。
下列模型支援全域批次:
| 模型 | 版本 | 輸入格式 |
|---|---|---|
o3-mini |
2025-01-31 | text |
gpt-4o |
2024-08-06 | 文字 + i影像 |
gpt-4o-mini |
2024-07-18 | 文字 + i影像 |
gpt-4o |
2024-05-13 | 文字 + i影像 |
gpt-4 |
turbo-2024-04-09 | text |
gpt-4 |
0613 | text |
gpt-35-turbo |
0125 | text |
gpt-35-turbo |
1106 | text |
gpt-35-turbo |
0613 | text |
如需目前支援全域批次所在區域/模型的最新資訊,請參閱模型頁面。
API 支援
| API 版本 | |
|---|---|
| 最新的 GA API 版本: | 2024-10-21 |
| 最新的預覽 API 版本: | 2025-01-01-preview |
支援第一次新增於: 2024-07-01-preview
功能支援
目前不支援下列項目:
- 與 Assistants API 整合。
- 與 Azure OpenAI On Your Data 功能整合。
注意
全域 Batch 現在支援結構化輸出。
批次部署
注意
在 Azure AI Foundry 入口網站中,批次部署類型會顯示為 Global-Batch 和 Data Zone Batch。 若要深入瞭解 Azure OpenAI 部署類型,請參閱我們的 部署類型指南。

提示
我們建議為所有全域批次模型部署啟用 動態配額 ,以協助避免因加入佇列令牌配額不足而導致作業失敗。 動態配額可讓您的部署在有額外的容量可用時,以機會利用更多配額。 當動態配額設定為關閉時,您的部署將只能處理您建立部署時所定義的加入佇列令牌限制要求。
必要條件
- Azure 訂用帳戶 - 建立免費帳戶。
- 已部署
Global-Batch部署類型模型的 Azure OpenAI 資源。 您可以參考資源建立和模型部署指南來取得協助進行此程序。
準備您的批次檔
如同微調,全域批次會使用 JSON Lines (.jsonl) 格式的檔案。 以下是一些具有不同支援內容類型的範例檔案:
輸入格式
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
需要 custom_id,才能讓您識別哪些個別批次要求對應至指定的回應。 回應不會依與 .jsonl 批次檔中定義的相同順序傳回。
model 屬性應設定為符合您想要作為推斷回應目標的全域批次部署名稱。
重要
model 屬性必須設定為和您想要作為推斷回應目標的全域批次部署名稱相符。
批次檔案的每一行都必須有相同的全域批次模型部署名稱。如果您想要以不同的部署為目標,則必須在不同的批次檔案/作業中執行此動作。
為了達到最佳效能,我們建議提交大型檔案以進行批處理,而不是在每一個檔案中只有幾行的小型檔案。
建立輸入檔
在本文中,我們將建立名為 test.jsonl 的檔案,並將上述標準輸入程式碼區塊的內容複製到該檔案。 您必須修改全域批次部署名稱,並將其新增至檔案的每一行。
上傳批次檔
準備好輸入檔之後,您必須先上傳檔案,才能開始批次作業。 檔案上傳可以透過程式設計方式或透過 Studio 來完成。
選取您提供全域批次模型部署所在的 Azure OpenAI 資源。
選取 [Batch 作業>+建立批次作業]。
從 [批次資料] 的下拉式清單中 > 選取 [上傳檔案]> 選取 [上傳檔案] 並提供在上一個步驟中建立的
test.jsonl檔案 > 按一下 [下一步]。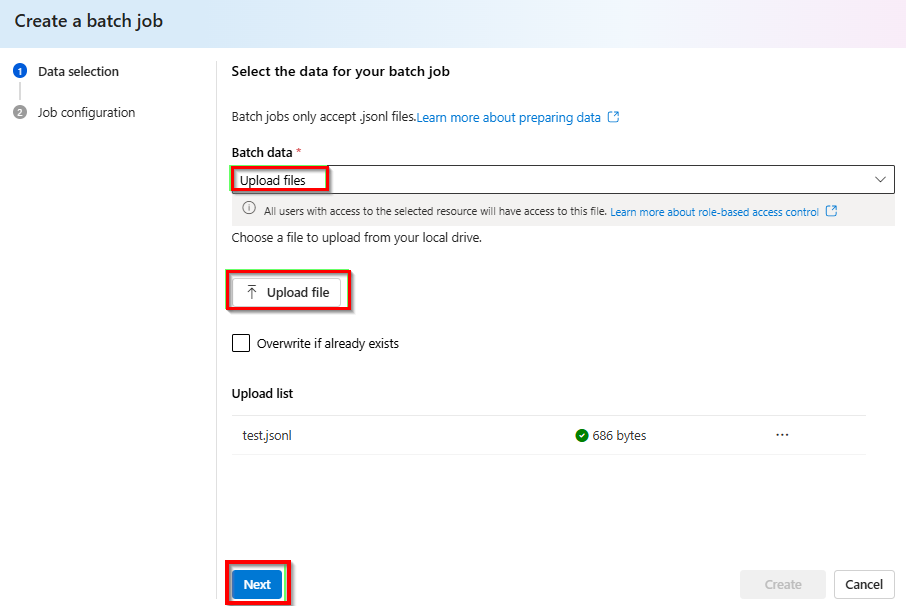


建立 Batch 作業
選取 [建立],以啟動您的批次作業。

追蹤批次作業進度
建立作業之後,您可以選取最近建立之作業的作業識別碼來監視作業的進度。 根據預設,系統會將您帶到最近建立批次作業的狀態頁面。

您可以在右側窗格中追蹤作業的作業狀態:

擷取批次作業輸出檔案
作業完成或達到終端狀態之後,就會產生錯誤檔案和輸出檔案,按一下向下箭號圖示即可下載以供檢閱。

取消批次
取消進行中的批次。 批次會處於 cancelling 狀態長達 10 分鐘,再變更為 cancelled,並在輸出檔案中提供部分結果 (如果有)。

必要條件
- Azure 訂用帳戶 - 建立免費帳戶。
- Python 3.8 或較新版本
- 下列 Python 程式庫:
openai - Jupyter 筆記本
- 已部署
Global-Batch部署類型模型的 Azure OpenAI 資源。 您可以參考資源建立和模型部署指南來取得協助進行此程序。
本文中的步驟必須在 Jupyter Notebook 中循序執行。 因此,我們只會在範例開頭具現化 Azure OpenAI 用戶端一次。 如果您想要不按照順序執行任一步驟,您通常需要在該呼叫中設定 Azure OpenAI 用戶端。
即使您已安裝 OpenAI Python 程式庫,也可能需要將安裝升級至最新版本:
!pip install openai --upgrade
準備您的批次檔
如同微調,全域批次會使用 JSON Lines (.jsonl) 格式的檔案。 以下是一些具有不同支援內容類型的範例檔案:
輸入格式
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
需要 custom_id,才能讓您識別哪些個別批次要求對應至指定的回應。 回應不會依與 .jsonl 批次檔中定義的相同順序傳回。
model 屬性應設定為符合您想要作為推斷回應目標的全域批次部署名稱。
重要
model 屬性必須設定為和您想要作為推斷回應目標的全域批次部署名稱相符。
批次檔案的每一行都必須有相同的全域批次模型部署名稱。如果您想要以不同的部署為目標,則必須在不同的批次檔案/作業中執行此動作。
為了達到最佳效能,我們建議提交大型檔案以進行批處理,而不是在每一個檔案中只有幾行的小型檔案。
建立輸入檔
在本文中,我們將建立名為 test.jsonl 的檔案,並將上述標準輸入程式碼區塊的內容複製到該檔案。 您必須修改全域批次部署名稱,並將其新增至檔案的每一行。 將此檔案儲存在您要執行 Jupyter Notebook 的相同目錄中。
上傳批次檔
準備好輸入檔之後,您必須先上傳檔案,才能開始批次作業。 檔案上傳可以透過程式設計方式或透過 Studio 來完成。 此範例會使用環境變數來取代金鑰和端點值。 如果您不熟悉搭配 Python 使用環境變數,請參閱我們的其中一個快速入門,其中逐步說明設定環境變數的程序。
import os
from openai import AzureOpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_ad_token_provider=token_provider,
api_version="2024-10-21"
)
# Upload a file with a purpose of "batch"
file = client.files.create(
file=open("test.jsonl", "rb"),
purpose="batch"
)
print(file.model_dump_json(indent=2))
file_id = file.id
輸出:
{
"id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"bytes": 815,
"created_at": 1722476551,
"filename": "test.jsonl",
"object": "file",
"purpose": "batch",
"status": null,
"status_details": null
}
建立 Batch 作業
成功上傳檔案之後,您就可以提交檔案以進行批處理。
# Submit a batch job with the file
batch_response = client.batches.create(
input_file_id=file_id,
endpoint="/chat/completions",
completion_window="24h",
)
# Save batch ID for later use
batch_id = batch_response.id
print(batch_response.model_dump_json(indent=2))
注意
目前,必須將完成時間範圍設定為 24 小時。 如果您設定為 24 小時以外的任何其他值,您的作業將會失敗。 超過 24 小時的作業會繼續執行,直到取消為止。
輸出:
{
"id": "batch_6caaf24d-54a5-46be-b1b7-518884fcbdde",
"completion_window": "24h",
"created_at": 1722476583,
"endpoint": null,
"input_file_id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"object": "batch",
"status": "validating",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"error_file_id": null,
"errors": null,
"expired_at": null,
"expires_at": 1722562983,
"failed_at": null,
"finalizing_at": null,
"in_progress_at": null,
"metadata": null,
"output_file_id": null,
"request_counts": {
"completed": 0,
"failed": 0,
"total": 0
}
}
追蹤批次作業進度
成功建立批次作業之後,您可以在 Studio 中或以程式設計方式監視其進度。 檢查批次作業進度時,建議在每個狀態呼叫之間等候至少 60 秒。
import time
import datetime
status = "validating"
while status not in ("completed", "failed", "canceled"):
time.sleep(60)
batch_response = client.batches.retrieve(batch_id)
status = batch_response.status
print(f"{datetime.datetime.now()} Batch Id: {batch_id}, Status: {status}")
if batch_response.status == "failed":
for error in batch_response.errors.data:
print(f"Error code {error.code} Message {error.message}")
輸出:
2024-07-31 21:48:32.556488 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: validating
2024-07-31 21:49:39.221560 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:50:53.383138 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:52:07.274570 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:53:21.149501 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:54:34.572508 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:55:35.304713 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:56:36.531816 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:57:37.414105 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: completed
可能的狀態值如下:
| 狀態 | 說明 |
|---|---|
validating |
正在驗證輸入檔,之後才能開始批次處理。 |
failed |
輸入檔的驗證程序失敗。 |
in_progress |
已成功驗證輸入檔,目前正在執行批次。 |
finalizing |
批次已完成,正在準備結果。 |
completed |
已完成批次,且結果已就緒。 |
expired |
批次無法在 24 小時的時間範圍內完成。 |
cancelling |
正在 cancelled 批次 (最多可能需要 10 分鐘才會生效)。 |
cancelled |
已 cancelled 批次。 |
若要查看作業狀態詳細資料,您可以執行:
print(batch_response.model_dump_json(indent=2))
輸出:
{
"id": "batch_6caaf24d-54a5-46be-b1b7-518884fcbdde",
"completion_window": "24h",
"created_at": 1722476583,
"endpoint": null,
"input_file_id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"object": "batch",
"status": "completed",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1722477429,
"error_file_id": "file-c795ae52-3ba7-417d-86ec-07eebca57d0b",
"errors": null,
"expired_at": null,
"expires_at": 1722562983,
"failed_at": null,
"finalizing_at": 1722477177,
"in_progress_at": null,
"metadata": null,
"output_file_id": "file-3304e310-3b39-4e34-9f1c-e1c1504b2b2a",
"request_counts": {
"completed": 3,
"failed": 0,
"total": 3
}
}
注意同時會有 error_file_id 和個別的 output_file_id。 使用 error_file_id 來協助偵錯批次作業發生的任何問題。
擷取批次作業輸出檔案
import json
output_file_id = batch_response.output_file_id
if not output_file_id:
output_file_id = batch_response.error_file_id
if output_file_id:
file_response = client.files.content(output_file_id)
raw_responses = file_response.text.strip().split('\n')
for raw_response in raw_responses:
json_response = json.loads(raw_response)
formatted_json = json.dumps(json_response, indent=2)
print(formatted_json)
輸出:
為了簡潔起見,我們只包含輸出的單一聊天完成回應。 如果依照本文中的步驟執行,您應該會有三個類似如下的回應:
{
"custom_id": "task-0",
"response": {
"body": {
"choices": [
{
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
},
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "Microsoft was founded on April 4, 1975, by Bill Gates and Paul Allen in Albuquerque, New Mexico.",
"role": "assistant"
}
}
],
"created": 1722477079,
"id": "chatcmpl-9rFGJ9dh08Tw9WRKqaEHwrkqRa4DJ",
"model": "gpt-4o-2024-05-13",
"object": "chat.completion",
"prompt_filter_results": [
{
"prompt_index": 0,
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"jailbreak": {
"filtered": false,
"detected": false
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
}
}
],
"system_fingerprint": "fp_a9bfe9d51d",
"usage": {
"completion_tokens": 24,
"prompt_tokens": 27,
"total_tokens": 51
}
},
"request_id": "660b7424-b648-4b67-addc-862ba067d442",
"status_code": 200
},
"error": null
}
其他批次命令
取消批次
取消進行中的批次。 批次會處於 cancelling 狀態長達 10 分鐘,再變更為 cancelled,並在輸出檔案中提供部分結果 (如果有)。
client.batches.cancel("batch_abc123") # set to your batch_id for the job you want to cancel
列出批次
列出特定 Azure OpenAI 資源的批次作業。
client.batches.list()
Python 連結庫中的清單方法會編頁。
若要列出所有作業:
all_jobs = []
# Automatically fetches more pages as needed.
for job in client.batches.list(
limit=20,
):
# Do something with job here
all_jobs.append(job)
print(all_jobs)
清單批次 (預覽)
使用 REST API 列出具有其他排序/篩選選項的所有批次作業。
在下列範例中,我們會提供 函 generate_time_filter 式,讓建構篩選變得更容易。 如果您不想使用此函式,篩選字串的格式看起來會像 created_at gt 1728860560 and status eq 'Completed'。
import requests
import json
from datetime import datetime, timedelta
from azure.identity import DefaultAzureCredential
token_credential = DefaultAzureCredential()
token = token_credential.get_token('https://cognitiveservices.azure.com/.default')
endpoint = "https://{YOUR_RESOURCE_NAME}.openai.azure.com/"
api_version = "2024-10-01-preview"
url = f"{endpoint}openai/batches"
order = "created_at asc"
time_filter = lambda: generate_time_filter("past 8 hours")
# Additional filter examples:
#time_filter = lambda: generate_time_filter("past 1 day")
#time_filter = lambda: generate_time_filter("past 3 days", status="Completed")
def generate_time_filter(time_range, status=None):
now = datetime.now()
if 'day' in time_range:
days = int(time_range.split()[1])
start_time = now - timedelta(days=days)
elif 'hour' in time_range:
hours = int(time_range.split()[1])
start_time = now - timedelta(hours=hours)
else:
raise ValueError("Invalid time range format. Use 'past X day(s)' or 'past X hour(s)'")
start_timestamp = int(start_time.timestamp())
filter_string = f"created_at gt {start_timestamp}"
if status:
filter_string += f" and status eq '{status}'"
return filter_string
filter = time_filter()
headers = {'Authorization': 'Bearer ' + token.token}
params = {
"api-version": api_version,
"$filter": filter,
"$orderby": order
}
response = requests.get(url, headers=headers, params=params)
json_data = response.json()
if response.status_code == 200:
print(json.dumps(json_data, indent=2))
else:
print(f"Request failed with status code: {response.status_code}")
print(response.text)
輸出:
{
"data": [
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1729011896,
"completion_window": "24h",
"created_at": 1729011128,
"error_file_id": "file-472c0626-4561-4327-9e4e-f41afbfb30e6",
"expired_at": null,
"expires_at": 1729097528,
"failed_at": null,
"finalizing_at": 1729011805,
"id": "batch_4ddc7b60-19a9-419b-8b93-b9a3274b33b5",
"in_progress_at": 1729011493,
"input_file_id": "file-f89384af0082485da43cb26b49dc25ce",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": "file-62bebde8-e767-4cd3-a0a1-28b214dc8974",
"request_counts": {
"total": 3,
"completed": 2,
"failed": 1
},
"status": "completed",
"endpoint": "/chat/completions"
},
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1729016366,
"completion_window": "24h",
"created_at": 1729015829,
"error_file_id": "file-85ae1971-9957-4511-9eb4-4cc9f708b904",
"expired_at": null,
"expires_at": 1729102229,
"failed_at": null,
"finalizing_at": 1729016272,
"id": "batch_6287485f-50fc-4efa-bcc5-b86690037f43",
"in_progress_at": 1729016126,
"input_file_id": "file-686746fcb6bc47f495250191ffa8a28e",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": "file-04399828-ae0b-4825-9b49-8976778918cb",
"request_counts": {
"total": 3,
"completed": 2,
"failed": 1
},
"status": "completed",
"endpoint": "/chat/completions"
}
],
"first_id": "batch_4ddc7b60-19a9-419b-8b93-b9a3274b33b5",
"has_more": false,
"last_id": "batch_6287485f-50fc-4efa-bcc5-b86690037f43"
}
必要條件
- Azure 訂用帳戶 - 建立免費帳戶。
- 已部署
Global-Batch部署類型模型的 Azure OpenAI 資源。 您可以參考資源建立和模型部署指南來取得協助進行此程序。
準備您的批次檔
如同微調,全域批次會使用 JSON Lines (.jsonl) 格式的檔案。 以下是一些具有不同支援內容類型的範例檔案:
輸入格式
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
需要 custom_id,才能讓您識別哪些個別批次要求對應至指定的回應。 回應不會依與 .jsonl 批次檔中定義的相同順序傳回。
model 屬性應設定為符合您想要作為推斷回應目標的全域批次部署名稱。
重要
model 屬性必須設定為和您想要作為推斷回應目標的全域批次部署名稱相符。
批次檔案的每一行都必須有相同的全域批次模型部署名稱。如果您想要以不同的部署為目標,則必須在不同的批次檔案/作業中執行此動作。
為了達到最佳效能,我們建議提交大型檔案以進行批處理,而不是在每一個檔案中只有幾行的小型檔案。
建立輸入檔
在本文中,我們將建立名為 test.jsonl 的檔案,並將上述標準輸入程式碼區塊的內容複製到該檔案。 您必須修改全域批次部署名稱,並將其新增至檔案的每一行。
上傳批次檔
準備好輸入檔之後,您必須先上傳檔案,才能開始批次作業。 檔案上傳可以透過程式設計方式或透過 Studio 來完成。 此範例會使用環境變數來取代金鑰和端點值。 如果您不熟悉搭配 Python 使用環境變數,請參閱我們的其中一個快速入門,其中逐步說明設定環境變數的程序。
重要
請謹慎使用 API 金鑰。 請勿在程式碼中直接包含 API 金鑰,且切勿公開張貼金鑰。 如果您使用 API 金鑰,請將它安全地儲存在 Azure 金鑰保存庫 中。 如需在應用程式中安全地使用 API 金鑰的詳細資訊,請參閱搭配 Azure 金鑰保存庫 的 API 金鑰。
如需 AI 服務安全性的詳細資訊,請參閱驗證對 Azure AI 服務的要求 (英文)。
curl -X POST https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files?api-version=2024-10-21 \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=batch" \
-F "file=@C:\\batch\\test.jsonl;type=application/json"
上述程式碼假設您的 test.jsonl 檔案有特定檔案路徑。 您可以視本機系統需要調整此檔案路徑。
輸出:
{
"status": "pending",
"bytes": 686,
"purpose": "batch",
"filename": "test.jsonl",
"id": "file-21006e70789246658b86a1fc205899a4",
"created_at": 1721408291,
"object": "file"
}
追蹤檔案上傳狀態
視上傳檔案的大小而定,可能需要一些時間才能完整上傳和處理檔案。 若要檢查您的檔案上傳狀態,請執行:
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files/{file-id}?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
輸出:
{
"status": "processed",
"bytes": 686,
"purpose": "batch",
"filename": "test.jsonl",
"id": "file-21006e70789246658b86a1fc205899a4",
"created_at": 1721408291,
"object": "file"
}
建立 Batch 作業
成功上傳檔案之後,您就可以提交檔案以進行批處理。
curl -X POST https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"input_file_id": "file-abc123",
"endpoint": "/chat/completions",
"completion_window": "24h"
}'
注意
目前,必須將完成時間範圍設定為 24 小時。 如果您設定為 24 小時以外的任何其他值,您的作業將會失敗。 超過 24 小時的作業會繼續執行,直到取消為止。
輸出:
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"completion_window": "24h",
"created_at": "2024-07-19T17:13:57.2491382+00:00",
"error_file_id": null,
"expired_at": null,
"expires_at": "2024-07-20T17:13:57.1918498+00:00",
"failed_at": null,
"finalizing_at": null,
"id": "batch_fe3f047a-de39-4068-9008-346795bfc1db",
"in_progress_at": null,
"input_file_id": "file-21006e70789246658b86a1fc205899a4",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": null,
"request_counts": {
"total": null,
"completed": null,
"failed": null
},
"status": "Validating"
}
追蹤批次作業進度
成功建立批次作業之後,您可以在 Studio 中或以程式設計方式監視其進度。 檢查批次作業進度時,建議在每個狀態呼叫之間等候至少 60 秒。
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches/{batch_id}?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
輸出:
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"completion_window": "24h",
"created_at": "2024-07-19T17:33:29.1619286+00:00",
"error_file_id": null,
"expired_at": null,
"expires_at": "2024-07-20T17:33:29.1578141+00:00",
"failed_at": null,
"finalizing_at": null,
"id": "batch_e0a7ee28-82c4-46a2-a3a0-c13b3c4e390b",
"in_progress_at": null,
"input_file_id": "file-c55ec4e859d54738a313d767718a2ac5",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": null,
"request_counts": {
"total": null,
"completed": null,
"failed": null
},
"status": "Validating"
}
可能的狀態值如下:
| 狀態 | 說明 |
|---|---|
validating |
正在驗證輸入檔,之後才能開始批次處理。 |
failed |
輸入檔的驗證程序失敗。 |
in_progress |
已成功驗證輸入檔,目前正在執行批次。 |
finalizing |
批次已完成,正在準備結果。 |
completed |
已完成批次,且結果已就緒。 |
expired |
批次無法在 24 小時的時間範圍內完成。 |
cancelling |
正在 cancelled 批次 (最多可能需要 10 分鐘才會生效)。 |
cancelled |
已 cancelled 批次。 |
擷取批次作業輸出檔案
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files/{output_file_id}/content?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY" > batch_output.jsonl
其他批次命令
取消批次
取消進行中的批次。 批次會處於 cancelling 狀態長達 10 分鐘,再變更為 cancelled,並在輸出檔案中提供部分結果 (如果有)。
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches/{batch_id}/cancel?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
列出批次
列出指定 Azure OpenAI 資源的現有批次作業。
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
清單 API 呼叫已編頁。 回應包含布爾值 has_more ,指出何時有更多可逐一查看的結果。
清單批次 (預覽)
使用 REST API 列出具有其他排序/篩選選項的所有批次作業。
curl "YOUR_RESOURCE_NAME.openai.azure.com/batches?api-version=2024-10-01-preview&$filter=created_at%20gt%201728773533%20and%20created_at%20lt%201729032733%20and%20status%20eq%20'Completed'&$orderby=created_at%20asc" \
-H "api-key: $AZURE_OPENAI_API_KEY"
若要避免錯誤 URL rejected: Malformed input to a URL function 空間會取代為 %20。
Batch 限制
| 限制名稱 | 限制值 |
|---|---|
| 每個資源的檔案數目上限 | 500 |
| 輸入檔案大小上限 | 200 MB |
| 每個檔案的要求數目上限 | 100,000 |
批次配額
下表顯示批次配額限制。 全域批次的配額值會以加入佇列的權杖表示。 當您提交檔案進行批次處理時,就會計算檔案中存在的權杖數目。 在批次作業達到終端狀態之前,這些權杖將會計入您加入佇列的權杖總計限制。
全域批次
| 模型 | Enterprise 合約 | 預設 | 每月信用卡型訂閱 | MSDN 訂用帳戶 | Azure 學生版,免費試用 |
|---|---|---|---|---|---|
gpt-4o |
5 B | 200 M | 50 公尺 | 90 K | N/A |
gpt-4o-mini |
15 B | 1 B | 50 公尺 | 90 K | N/A |
gpt-4-turbo |
300 M | 80 M | 40 M | 90 K | N/A |
gpt-4 |
150 M | 30 M | 5 M | 100 K | N/A |
gpt-35-turbo |
10 B | 1 B | 100 M | 2 公尺 | 50 K |
o3-mini |
15 B | 1 B | 50 公尺 | 90 K | N/A |
B = 十億 | M = 百萬 | K = 千
數據區批次
| 模型 | Enterprise 合約 | 預設 | 每月信用卡型訂閱 | MSDN 訂用帳戶 | Azure 學生版,免費試用 |
|---|---|---|---|---|---|
gpt-4o |
500 M | 30 M | 30 M | 90 K | N/A |
gpt-4o-mini |
1.5 B | 100 M | 50 公尺 | 90 K | N/A |
批次物件
| 屬性 | 類型 | 定義 |
|---|---|---|
id |
字串 | |
object |
字串 | batch |
endpoint |
字串 | 批次所使用的 API 端點 |
errors |
object | |
input_file_id |
字串 | 批次的輸入檔識別碼 |
completion_window |
字串 | 應處理批次的時間範圍 |
status |
字串 | 批次目前的狀態。 可能的值:validating、failed、in_progress、finalizing、completed、expired、cancelling、cancelled。 |
output_file_id |
字串 | 包含成功執行之要求輸出的檔案識別碼。 |
error_file_id |
字串 | 包含具有錯誤之要求輸出的檔案識別碼。 |
created_at |
整數 | 已建立此批次的時間戳記 (以 Unix Epoch 表示)。 |
in_progress_at |
整數 | 此批次已開始進行中的時間戳記 (以 Unix Epoch 表示)。 |
expires_at |
整數 | 此批次將到期的時間戳記 (以 Unix Epoch 表示)。 |
finalizing_at |
整數 | 此批次已開始結束中的時間戳記 (以 Unix Epoch 表示)。 |
completed_at |
整數 | 此批次已開始結束中的時間戳記 (以 Unix Epoch 表示)。 |
failed_at |
整數 | 此批次失敗的時間戳記 (以 Unix Epoch 表示) |
expired_at |
整數 | 此批次已到期的時間戳記 (以 Unix Epoch 表示)。 |
cancelling_at |
整數 | 此批次已開始 cancelling 的時間戳記 (以 Unix Epoch 表示)。 |
cancelled_at |
整數 | 已 cancelled 批次的時間戳記 (以 Unix Epoch 表示)。 |
request_counts |
object | 物件結構:total
整數 批次中的要求總數。 completed
整數 批次中已成功完成的要求數目。 failed
整數 批次中失敗的要求數目。 |
metadata |
map | 可附加至批次的索引鍵/值組。 此屬性可能有助於以結構化格式儲存批次的其他相關資訊。 |
常見問題集 (FAQ)
影像可以搭配 Batch API 使用嗎?
這項功能僅限於特定多模式模型。 目前只有 GPT-4o 支援在批次要求中使用影像。 您可以透過影像 URL 或影像的 Base64 編碼表示法提供影像作為輸入。 GPT-4 Turbo 目前不支援針對批次使用影像。
我可以搭配微調模型使用 Batch API 嗎?
目前不支援。
我可以使用 Batch API 來內嵌模型嗎?
目前不支援。
內容篩選是否可與全域批次部署搭配運作?
是。 類似於其他部署類型,您可以建立內容篩選,並將其與全域批次部署類型產生關聯。
我可以要求額外的配額嗎?
是,從 Azure AI Foundry 入口網站中的配額頁面。 您可以在配額和限制一文中找到預設配額配置。
如果 API 未在 24 小時的時間範圍內完成要求,會發生什麼事?
我們的目標是在 24 小時內處理這些要求,超過時間的作業不會到期。 您可以隨時取消作業。 當您取消作業時,會取消任何剩餘的工作,並傳回任何已完成的工作。 您需支付任何已完成的工作費用。
我可以使用批次將多少個要求排入佇列?
您可以批次處理的要求數目沒有固定限制,但會取決於加入佇列的權杖配額。 加入佇列的權杖配額包含您一次可以加入佇列的輸入權杖數目上限。
完成批次要求之後,由於已清除輸入權杖,因此會重設批次速率限制。 該限制取決於佇列中的全域要求數目。 如果 Batch API 佇列快速處理您的批次,則會更快重設批次速率限制。
疑難排解
當 Completed 為 status 時,作業會成功。 成功的作業仍會產生 error_file_id,但會與具有零位元組的空白檔案相關聯。
當作業發生失敗時,您會在 errors 屬性中找到失敗的詳細資料:
"value": [
{
"id": "batch_80f5ad38-e05b-49bf-b2d6-a799db8466da",
"completion_window": "24h",
"created_at": 1725419394,
"endpoint": "/chat/completions",
"input_file_id": "file-c2d9a7881c8a466285e6f76f6321a681",
"object": "batch",
"status": "failed",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1725419955,
"error_file_id": "file-3b0f9beb-11ce-4796-bc31-d54e675f28fb",
"errors": {
"object": “list”,
"data": [
{
“code”: “empty_file”,
“message”: “The input file is empty. Please ensure that the batch contains at least one request.”
}
]
},
"expired_at": null,
"expires_at": 1725505794,
"failed_at": null,
"finalizing_at": 1725419710,
"in_progress_at": 1725419572,
"metadata": null,
"output_file_id": "file-ef12af98-dbbc-4d27-8309-2df57feed572",
"request_counts": {
"total": 10,
"completed": null,
"failed": null
},
}
錯誤碼
| 錯誤碼 | 定義 |
|---|---|
invalid_json_line |
輸入檔中的一或多行無法剖析為有效的 JSON。 請確定沒有錯字、左右括弧正確,並依照 JSON 標準加上引號,再重新提交要求。 |
too_many_tasks |
輸入檔中的要求數目超過允許的最大值 100,000。 請確定您的要求總數低於 100,000,再重新提交作業。 |
url_mismatch |
可能是輸入檔中的某個資料列具有不符合其餘資料列的 URL,或是輸入檔中指定的 URL 不符合預期的端點 URL。 請確定所有要求 URL 都相同,並符合與 Azure OpenAI 部署相關聯的端點 URL。 |
model_not_found |
找不到輸入檔 model 屬性中指定的 Azure OpenAI 模型部署名稱。請確定此名稱指向有效的 Azure OpenAI 模型部署。 |
duplicate_custom_id |
此要求的自訂識別碼與另一個要求的自訂識別碼重複。 |
empty_batch |
請檢查您的輸入檔,確定批次中每個要求的自訂識別碼參數都是唯一的。 |
model_mismatch |
在輸入檔內此要求的 model 屬性中指定的 Azure OpenAI 模型部署名稱不符合檔案的其餘部分。請確定批次中的所有要求都指向要求 屬性中的 model 相同 Azure OpenAI 服務模型部署。 |
invalid_request |
輸入行的結構描述無效,或部署 SKU 無效。 請確定輸入檔中要求的屬性符合預期的輸入屬性,且 Batch API 要求中的 Azure OpenAI 部署 SKU 為 globalbatch。 |
已知問題
- 使用 Azure CLI 部署的資源無法直接與 Azure OpenAI 全域批次搭配運作。 這是由於使用此方法部署的資源具有未遵循
https://your-resource-name.openai.azure.com模式之端點子網域的問題所造成。 此問題的因應措施是使用其他常見部署方法的其中之一來部署新的 Azure OpenAI 資源,以適當地在部署程序中處理子網域設定。