作法:將計量資料上線至計量建議程式
重要
從 2023 年 9 月 20 日起,您將無法建立新的計量建議程式資源。 計量建議程式服務將於 2026 年 10 月 1 日淘汰。
使用本文來了解如何將資料上線至計量建議程式。
資料結構描述需求和組態
Azure AI 計量建議程式是用於時間序列異常偵測、診斷和分析的服務。 作為 AI 服務,其會使用您的資料來定型所使用的模型。 服務接受具有下列資料行的彙總資料資料表:
- 量值 (必要):量值是基本或單位特定的字詞,也是可量化的計量值。 其表示包含數值的一或多個資料行。
- 時間戳記 (選用):零或一個類型為
DateTime或String的資料行。 未設定這個資料行時,時間戳記會設定為每個內嵌期間的開始時間。 格式化時間戳記,如下所示:yyyy-MM-ddTHH:mm:ssZ。 - 維度 (選用):維度是一或多個類別值。 這些值的組合會識別特定的單變量時間序列 (例如國家/地區、語言和租用戶)。 維度資料行可以是任何資料類型。 使用大量資料行和值時請小心,以避免處理過多的維度數。
如果您使用資料來源,例如 Azure Data Lake Storage 或 Azure Blob 儲存體,您可以彙總資料,以符合預期的計量結構描述。 這是因為這些資料來源會使用檔案作為計量輸入。
如果您使用資料來源,例如 Azure SQL 或 Azure 資料總管,您可以使用彙總函數,將資料彙總至預期的結構描述。 這是因為這些資料來源支援執行查詢,以從來源取得計量資料。
如果您不確定某些字詞,則請參閱詞彙。
避免載入部分資料
部分資料是計量建議程式中所儲存的資料與資料來源之間的不一致所造成。 計量建議程式完成提取資料之後,會在更新資料來源時發生這種情況。 計量建議程式只會從指定的資料來源提取資料一次。
例如,如果已將計量上線至計量建議程式來進行監視。 計量建議程式會在時間戳記 A 時成功擷取計量資料,並在對其執行異常偵測。 不過,如果在擷取資料之後已重新整理該特定時間戳記 A 的計量資料。 將不會擷取新的資料值。
您可以嘗試回填歷程記錄資料 (如稍後所述) 以減輕不一致,但如果已觸發這些時間點的警示,則這不會觸發新的異常警示。 此程序可能會將額外的工作負載新增至系統,而且不是自動的。
為了避免載入部分資料,建議使用兩種方法:
使用一筆交易產生資料:
確定使用一筆交易將相同時間戳記上所有維度組合的計量值都儲存至資料來源。 在上述範例中,請等到所有資料來源的資料就緒,然後以一筆交易將其載入至計量建議程式。 除非成功 (或部分) 擷取資料,否則計量建議程式可以定期輪詢資料摘要。
設定「擷取時間位移」參數的適當值,以延遲資料擷取:
設定資料摘要的「擷取時間位移」參數,以將擷取延遲到資料完整備妥。 這可以適用於不支援 Azure 資料表儲存體這類交易的某些資料來源。 如需詳細資料,請參閱進階設定。
從新增資料摘要開始
登入您的計量建議程式入口網站並選擇工作區之後,請按一下 [開始使用]。 然後,在工作區的主要頁面上,按一下左側功能表中的 [新增資料摘要]。
新增連線設定
1. 基本設定
接下來,您將輸入一組參數來連線時間序列資料來源。
- 來源類型:儲存時間序列資料的資料來源類型。
- 細微性:時間序列資料中連續資料點之間的間隔。 計量建議程式目前支援:每年、每月、每週、每日、每小時、每分鐘和自訂。 自訂選項所支援的最低間隔是 60 秒。
- 秒:granularityName 設定為 Customize 時的秒數。
- 擷取資料起算時間 (UTC):資料擷取的基準開始時間。
startOffsetInSeconds通常用來新增位移,以協助資料一致性。
2. 指定連接字串
接下來,您將需要指定資料來源的連線資訊。 如需其他欄位和連線不同資料來源類型的詳細資料,請參閱操作說明:連線不同的資料來源。
3. 指定單一時間戳記的查詢
如需不同資料來源類型的詳細資料,請參閱操作說明:連線不同的資料來源。
載入資料
輸入連接字串和查詢字串之後,請選取 [載入資料]。 在此作業內,計量建議程式將會檢查可載入資料的連線和權限、檢查必要的參數 (需要用於查詢的 @IntervalStart 和 @IntervalEnd)),以及檢查資料來源中的資料行名稱。
如果此步驟發生錯誤:
- 先檢查連接字串是否有效。
- 然後檢查是否有足夠的權限,以及擷取背景工作角色 IP 位址是否獲授與存取權。
- 然後檢查是否在查詢中使用必要參數 (@IntervalStart 和 @IntervalEnd))。
結構描述組態
載入資料結構描述之後,請選取適當的欄位。
如果省略資料點的時間戳記,則計量建議程式將會在擷取資料點時改為使用時間戳記。 針對每個資料摘要,您最多可以指定一個資料行作為時間戳記。 如果您收到一則訊息,指出無法將資料行指定為時間戳記,則請檢查您的查詢或資料來源,以及查詢結果中是否有多個時間戳記,而不只是檢查預覽資料。 執行資料擷取時,計量建議程式每次只能從所指定來源的時間序列資料取用一個區塊 (例如一天、一個小時 - 根據細微性而定)。
| 選取項目 | 描述 | 附註 |
|---|---|---|
| 顯示名稱 | 要在工作區中顯示的名稱,而不是原始資料行名稱。 | 選擇性。 |
| Timestamp | 資料點的時間戳記。 如果省略,則在內嵌資料點時,Metrics Advisor 會使用時間戳記。 針對每個資料摘要,您最多可以指定一個資料行作為時間戳記。 | 選擇性。 最多只能指定一個資料行。 如果您收到「無法將資料行指定為時間戳記」錯誤,則請檢查您的查詢或資料來源是否有重複的時間戳記。 |
| Measure | 資料摘要中的數值。 針對每個資料摘要,您可以指定多個量值,但至少應該選取一個資料行作為量值。 | 應指定至少一個資料行。 |
| 維度 | 類別值。 不同值的組合會識別特定的單一維度時間序列,例如:國家/地區、語言、租用戶。 您可以選取零或多個資料行作為維度。 注意:選取非字串資料行作為維度時請小心。 | 選擇性。 |
| 忽略 | 略過選取的資料行。 | 選擇性。 針對使用查詢取得資料的資料來源支援,沒有 [忽略] 選項。 |
如果您想要忽略資料行,則建議更新查詢或資料來源,以排除這些資料行。 您也可以使用 [忽略資料行] 來忽略資料行,然後在特定資料行上使用 [忽略]。 如果資料行應該是維度,而且錯誤地設定為 [忽略],則計量建議程式最後可能會擷取部分資料。 例如,假設查詢中的資料如下:
| 資料列識別碼 | 時間戳記 | 國家/地區 | 語言 | Income |
|---|---|---|---|---|
| 1 | 2019/11/10 | 中國 | ZH-CN | 10000 |
| 2 | 2019/11/10 | 中國 | ZH-TW | 1000 |
| 3 | 2019/11/10 | US | ZH-CN | 12000 |
| 4 | 2019/11/11 | US | ZH-TW | 23000 |
| ... | ... | ... | ... | ... |
如果 [國家/地區] 是維度,且 [語言] 設定為 [忽略],則第一個和第二個資料列的時間戳記將會具有相同的維度。 計量建議程式將會任意使用來自這兩個資料列的一個值。 在此案例中,計量建議程式將不會彙總資料列。
設定結構描述之後,請選取 [驗證結構描述]。 在此作業內,計量建議程式將會執行下列檢查:
- 已查詢資料的時間戳記是否落在一個單一間隔。
- 是否在一個計量間隔內針對相同維度組合傳回重複的值。
自動積存設定
重要事項
如果您想要啟用根本原因分析和其他診斷功能,則需要設定「自動積存設定」。 啟用之後,就無法變更自動積存設定。
計量建議程式可以在擷取期間自動對每個維度執行彙總 (例如 SUM、MAX、MIN),然後建置將用於根本原因分析和其他診斷功能的階層。
請考慮下列案例:
「我不需要包括資料的積存分析。」
您不需要使用計量建議程式積存。
「我的資料已進行積存,且維度值是以:Null 或空白 (預設值)、僅限 Null、其他。」
此選項表示計量建議程式不需要積存資料,因為已加總資料列。 例如,如果您只選取 NULL,則下列範例中的第二個數據列會被視為所有國家/地區和語言 EN-US 的匯總;第四個數據列,其中的國家/地區具有空白值,但被視為可能表示不完整數據的一般數據列。
國家/地區 語言 Income 中國 ZH-CN 10000 (NULL) ZH-TW 999999 US ZH-TW 12000 ZH-TW 5000 「我需要計量建議程式藉由計算 Sum/Max/Min/Avg/Count 來積存我的資料,並使用 {some string} 予以表示。」
某些資料來源 (例如 Azure Cosmos DB 或 Azure Blob 儲存體) 不支援特定計算,例如「分組依據」或「Cube」。 計量建議程式提供積存選項,以在擷取期間自動產生資料 Cube。 此選項表示您需要計量建議程式以使用所選取的演算法來計算積存,並使用指定的字串來代表計量建議程式中的積存。 這不會變更資料來源中的任何資料。 例如,假設您有一組時間序列,而此時間序列代表具有維度 (Country, Region) 的 Sales 計量。 針對指定的時間戳記,這看起來可能如下所示:
Country 區域 Sales Canada Alberta 100 Canada British Columbia 500 美國 Montana 100 使用 Sum 啟用自動積存之後,計量建議程式將會計算維度組合,並在資料擷取期間加總計量。 結果可能是:
Country 區域 Sales Canada Alberta 100 NULL Alberta 100 Canada British Columbia 500 NULL British Columbia 500 美國 Montana 100 NULL Montana 100 NULL NULL 700 Canada NULL 600 美國 NULL 100 (Country=Canada, Region=NULL, Sales=600)表示加拿大 (所有區域) 銷售總和為 600。以下是 SQL 語言的轉換。
SELECT dimension_1, dimension_2, ... dimension_n, sum (metrics_1) AS metrics_1, sum (metrics_2) AS metrics_2, ... sum (metrics_n) AS metrics_n FROM each_timestamp_data GROUP BY CUBE (dimension_1, dimension_2, ..., dimension_n);使用自動積存功能之前,請考慮下列事項:
- 如果您想要使用 SUM 來彙總資料,則請確定計量在每個維度中都是加總的。 以下是一些「非加法」計量範例:
- 分數型計量。 這包括比率、百分比等。例如,您不應該新增每個州/省的失業率,來計算整個國家的失業率。
- 維度重疊。 例如,您不應該將人員數目新增至每個運動,以計算喜歡運動的人員數目,因為它們之間重疊,一個人可以喜歡多個運動。
- 為了確保整個系統的健康情況,Cube 的大小會受到限制。 限制目前為 100,000。 如果您的資料超過該限制,則該時間戳記的擷取將會失敗。
- 如果您想要使用 SUM 來彙總資料,則請確定計量在每個維度中都是加總的。 以下是一些「非加法」計量範例:
進階設定
有數個進階設定可讓您以自訂的方式來擷取資料,例如指定擷取位移或並行。 如需詳細資訊,請參閱資料摘要管理文章中的進階設定一節。
指定資料摘要的名稱,並檢查擷取進度
為資料摘要提供自訂名稱,這會顯示在您的工作區中。 然後,選取 [提交]。 在資料摘要詳細資料頁面中,您可以使用擷取進度列來檢視狀態資訊。

若要檢查擷取失敗詳細資料:
- 選取 [顯示詳細資料]。
- 選取 [狀態],然後選擇 [失敗] 或 [錯誤]。
- 將滑鼠停留在失敗的擷取上方,並檢視所出現的詳細資料訊息。
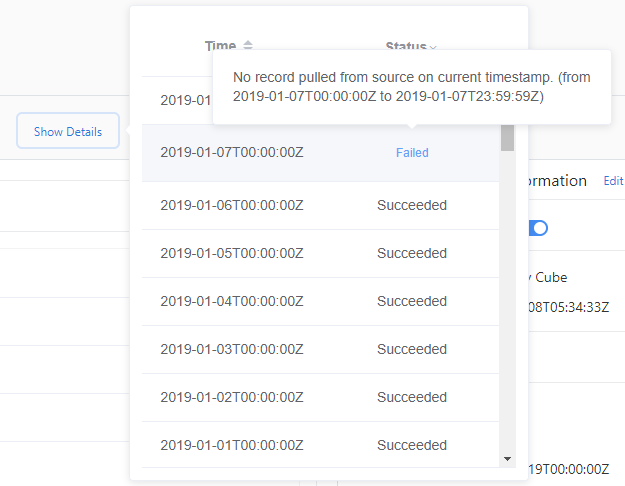
「失敗」狀態指出稍後將會重試此資料來源的擷取。 「錯誤」 狀態指出計量建議程式將不會重試資料來源。 若要重新載入資料,您需要手動觸發回填/重新載入。
您也可以按一下 [重新整理進度] 來重新載入擷取進度。 資料擷取完成之後,您可以按一下計量,並檢查異常偵測結果。