為專案建置結構描述之後,您應該將定型語句新增至您的專案。 語句應該與您的使用者在與專案互動時所使用的內容類似。 當您新增表達時,您必須指派其所屬的意圖。 新增表達之後,請標記您要擷取為實體的表達中字組。
資料標記是開發生命週期的重要步驟;定型模型時,將會在下一個步驟中使用此資料,讓您的模型可以從所標記的資料中學習。 如果您已經標標記表達,您可以直接將其匯入專案中,但是您必須確定您的資料遵循已接受的資料格式。 若要深入了解如何將已標記的資料匯入專案中,請參閱建立專案。 已標記的資料會告知模型如何解讀文字,並且會用於定型和評估。
必要條件
您需要下列項目才能標記資料:
- 成功建立的專案。
如需詳細資訊,請參閱專案開發生命週期。
資料標記指導方針
在組建結構描述並建立專案之後,您必須標記資料。 標記您的資料很重要,如此您的模型就會知道哪些字組和句子將與專案中的意圖和實體相關聯。 您會想要花時間標記表達 - 導入和精簡將用於定型模型的資料。
當您新增表達並加上標籤時,請記住:
機器學習模型會根據您提供的已標記範例進行一般化;您提供的範例越多,模型必須進行更好的資料點一般化。
您已加上標籤的資料的精確度、一致性和完整性,是決定模型效能的關鍵因素。
- 精確標記:一律將每個意圖和實體標記為其正確的類型。 只包含您想要分類和擷取的內容,避免標籤中出現非必要的資料。
- 標記一致:相同的實體在所有表達中都應該具有相同的標籤。
- 完整標記:為每個意圖提供不同的表達。 標記所有表達中實體的所有執行個體。
清楚標記表達
確定您實體所參考的概念已妥善定義且可分隔。 檢查您是否能夠輕鬆且可靠地判斷差異。 如果您不能,這種缺乏區別可能表示學習的元件也會有困難。
如果實體之間存在相似性,請確定資料的某些層面可提供其之間差異的訊號。
例如,如果您建置模型來預訂航班,使用者可能會使用類似「我需要從波士頓飛往西雅圖的航班」之類的語句。這類語句的「出發城市」和「目的地城市」應該類似。 區分「出發城市」的訊號可能是其前面通常會加上「從」一詞。
確定您會在訓練和測試資料中標記每個實體的所有執行個體。 其中一種方法是使用搜尋函式來尋找資料中字組或片語的所有執行個體,以檢查是否已為其正確標記。
針對具有無學習的元件的實體以及有學習的元件的實體標記測試資料。 這有助於確保您的評估計量正確無誤。
針對多語專案,在其他語言中新增表達會提高這些語言中模型的效能,但是請避免在您想要支援的所有語言中複製您的資料。 例如,若要提高行事曆機器人對使用者的效能,開發人員最可能會新增英文的範例,以及西班牙文或法文的一些範例。 其新增的語句可能包括:
- "Set a meeting with Matt and Kevintomorrow at 12 PM." (英文)
- "Reply as tentative to the weekly update meeting." (英文)
- "Cancelar mi próxima reunión." (西班牙文)
如何標記表達
使用下列步驟標記您的表達:
移至您在 Language Studio 中的專案頁面。
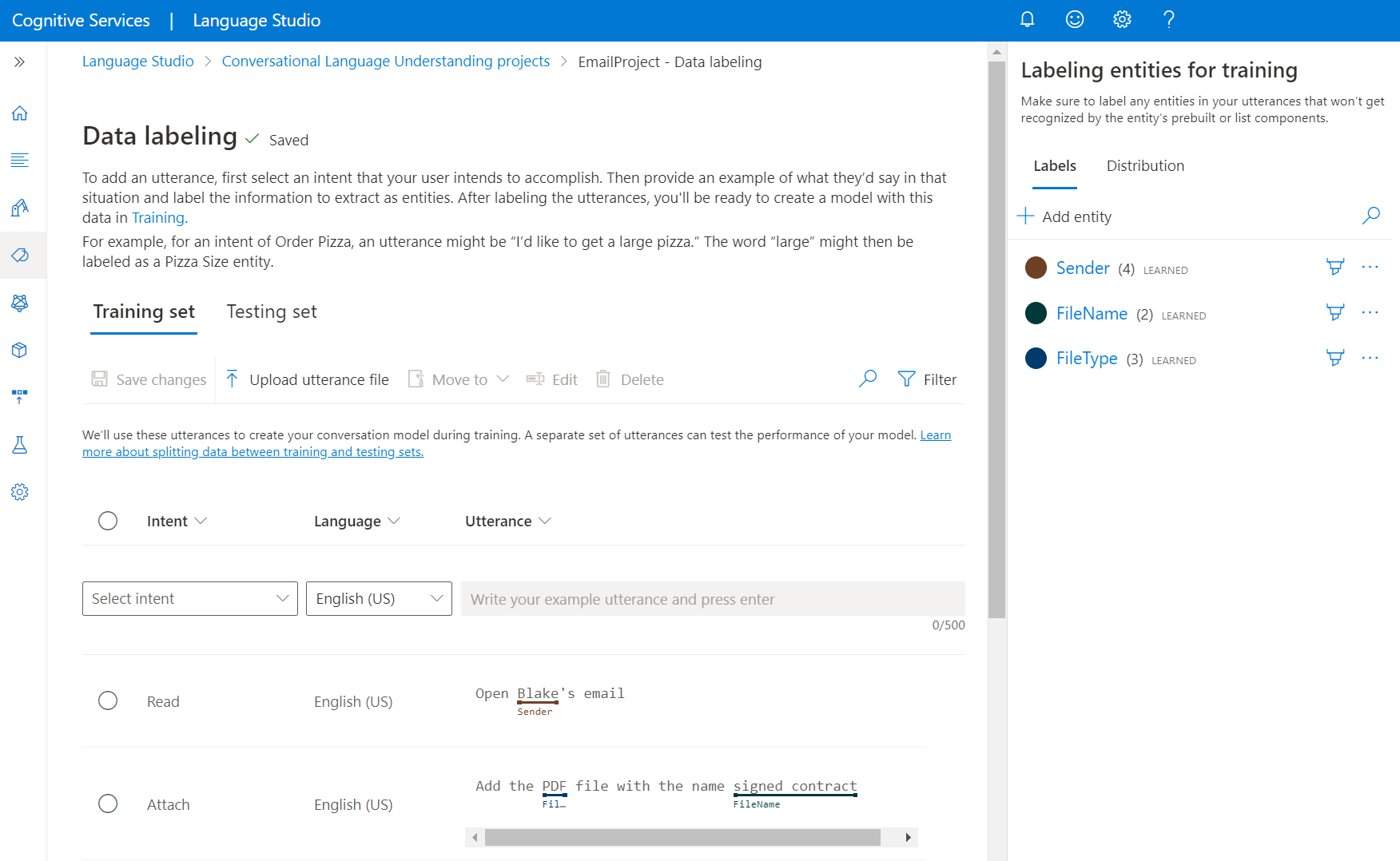
在左側功能表中,選取 [資料標記]。 在此頁面中,您可以開始新增表達並加上標籤。 您也可以按一下頂端功能表中的 [上傳表達檔案]直接上傳表達,確定其遵循已接受的格式。
從頂端樞紐中,您可以將檢視變更為 [定型集] 或 [測試集]。 深入了解定型和測試集,以及如何將其用於模型定型和評估。
提示
如果您打算使用 [從定型資料自動分割測試集] 分割,則請將所有表達都新增至定型集。
從 [選取意圖] 下拉式功能表中,選取其中一個意圖、(多語專案) 的表達語言,以及表達本身。 在表達的文字輸入框中按下輸入鍵以新增表達。
您有兩個標記表達中實體的選項:
選項 描述 使用筆刷標記 選取右窗格中實體旁邊的筆刷圖示,然後醒目提示表達中您要標記的文字。 使用內嵌功能表的標籤 醒目提示您要標記為實體的字詞,隨即出現一個功能表。 選取您要標記這些字組的實體。 在右窗格中,[標籤] 樞紐下,您可以找到專案中的所有實體類型,以及每個類別的已標記執行個體計數。
在 [分佈] 樞紐下,您可以檢視定型和測試集之間的分佈。 您有兩個檢視選項:
- 每個已標記實體的執行個體總計,您可以在其中檢視特定實體的所有已標記執行個體計數。
- 每個已標記實體的唯一表達,如果每個表達包含至少一個已標記的執行個體,則會計算每個表達。
- 每個意圖的表達,您可以在其中檢視每個意圖的表達計數。


注意
清單和預先建置的元件不會在資料標記頁面中顯示,而且此處的所有標籤都僅適用於學過的元件。
移除標籤:
- 從表達中,選取您要從中移除標籤的實體。
- 捲動出現的功能表,然後選取 [移除標籤]。
若要刪除實體:
- 在右側窗格中選取您要編輯的實體。
- 選取實體旁的三個點,然後從下拉式功能表中選取您想要的選項。
使用 Azure OpenAI 建議表達
在 CLU 中,使用 Azure OpenAI 來建議表達,以使用 GPT 模型將其新增至專案。 您必須首先取得存取權,並在 Azure OpenAI 中建立資源。 然後,您必須建立 GPT 模型的部署。 請遵循此處的必要步驟。
開始之前,只有在您的語言資源位於下列區域時,才能使用建議的表達功能:
- 美國東部
- 美國中南部
- 西歐
在 [資料標記] 頁面中:
- 選取 [建議表達] 按鈕。 窗格會在右側開啟,提示您選取 Azure OpenAI 資源和部署。
- 在選取 Azure OpenAI 資源時,選取 [連線],這可讓您的語言資源直接存取 Azure OpenAI 資源。 其會將語言資源角色
Cognitive Services User指派給 Azure OpenAI 資源,這可讓您的目前語言資源存取 Azure OpenAI 的服務。 如果連線失敗,請遵循下列這些步驟,手動將正確的角色新增至您的 Azure OpenAI 資源。 - 一旦連線資源,請選取部署。 Azure OpenAI 部署的建議模型為
text-davinci-002。 - 選取您想要取得建議的意圖。 確定您所選取的意圖至少有 5 個儲存的表達,要針對表達建議啟用。 Azure OpenAI 所提供的建議是根據您已為該意圖新增的最新表達。
- 選取 [產生表達]。 一旦完成,建議的表達就會顯示並以虛線括住,並帶有附注「由 AI 產生」。 必須接受或拒絕這些建議。 接受建議只會將其新增至您的專案,就像您自己新增一樣。 拒絕建議會完全將其刪除。 只有接受的表達將是專案的一部分,並用於定型或測試。 您可以按一下每個表達旁的綠色核取或紅色取消按鈕,以接受或拒絕此表達。 您也可以使用工具列中的
Accept all和Reject all按鈕。

使用此功能需要向 Azure OpenAI 資源收費,以取得與所產生建議表達類似的權杖數目。 Azure OpenAI 定價的詳細資料可在這裡找到。
將必要的設定新增至 Azure OpenAI 資源
如果將您的語言資源連線至 Azure OpenAI 資源失敗,請遵循下列步驟:
使用下列選項為您的語言資源啟用身分識別管理:
您的語言資源必須具有身分識別管理,才能使用 Azure 入口網站將其啟用:
- 移至您的語言資源
- 從左側功能表的 [資源管理] 區段底下,選取 [身分識別]
- 從 [系統指派] 索引標籤中,請務必將 [狀態] 設定為 [開啟]
在啟用受控識別之後,請使用語言資源的受控識別,將角色 Cognitive Services User 指派給 Azure OpenAI 資源。
- 登入 Azure 入口網站,然後瀏覽至 Azure OpenAI 資源。
- 選取左側的 [存取控制 (IAM)] 索引標籤。
- 選取 [新增] > [新增角色指派]。
- 選取「工作職能角色」,然後按 [下一步]。
- 從角色清單中選取
Cognitive Services User,然後按 [下一步]。 - 選取 [將存取權指派給「受控識別」],然後選取 [選取成員]。
- 在 [受控識別] 底下,選取 [語言]。
- 搜尋您的資源並加以選取。 然後選取下方的 [選取] 按鈕,接著完成此流程。
- 檢閱詳細資料,然後選取 [檢閱 + 指派]。

幾分鐘後,重新整理 Language Studio,您將能夠成功連線至 Azure OpenAI。