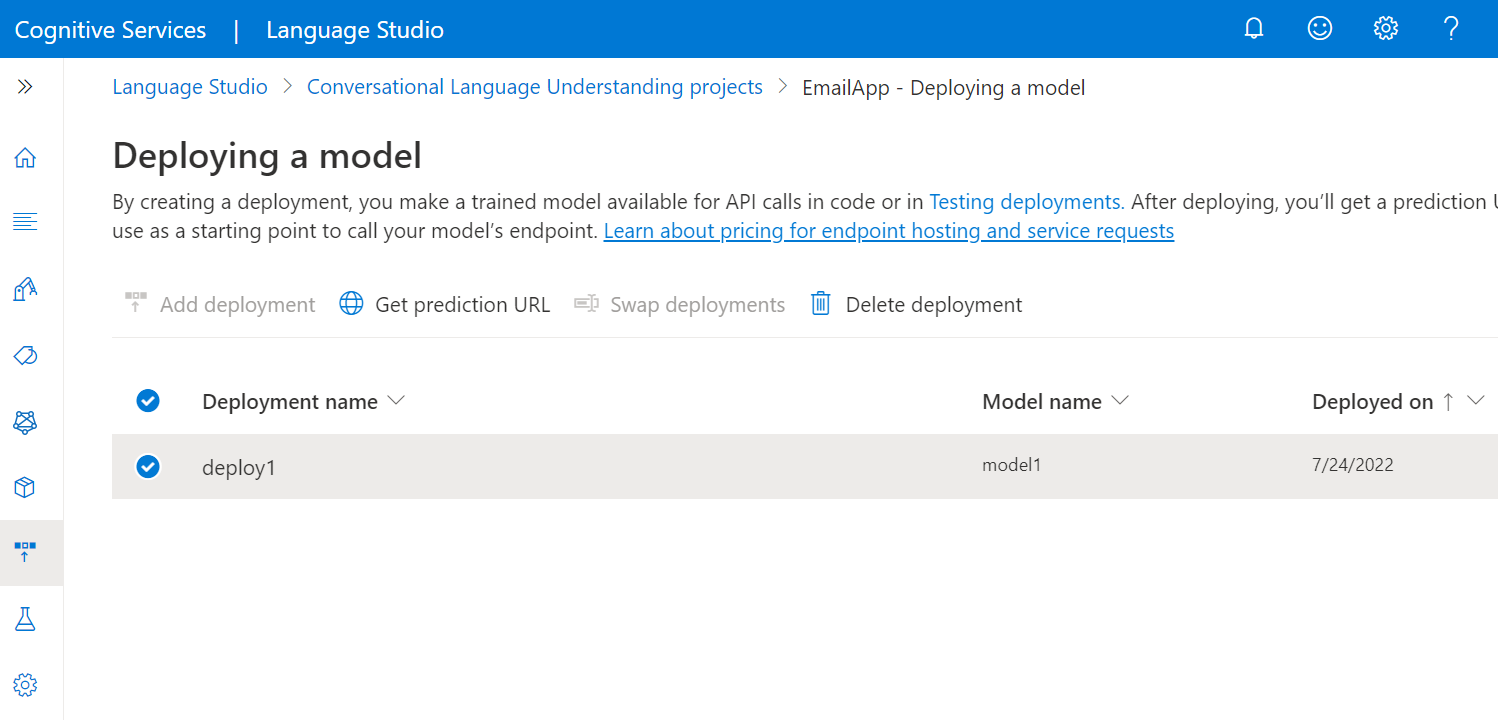
首先,您需要取得您的資源金鑰和端點:
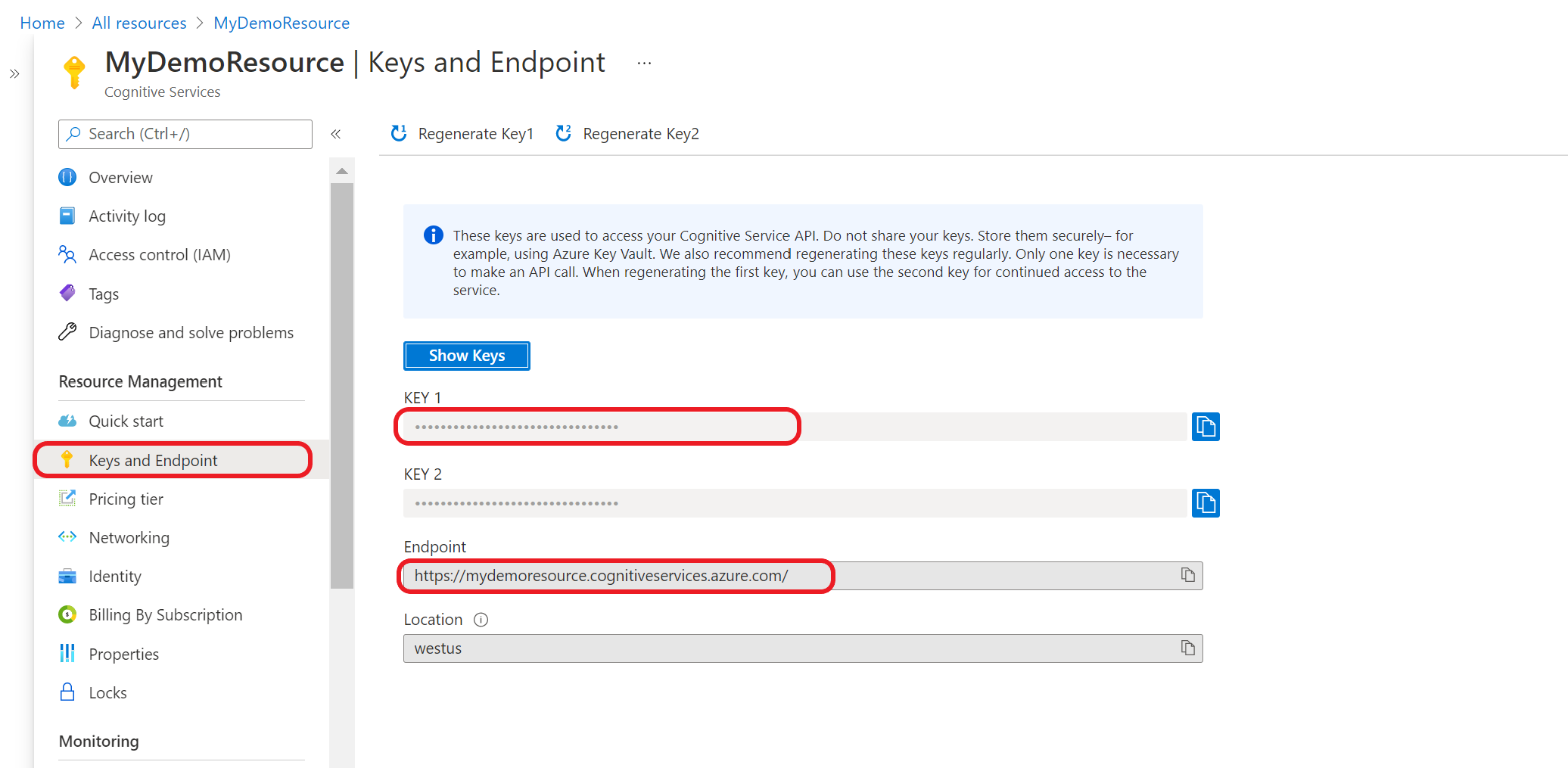
前往您位於 Azure 入口網站的資源概觀頁面。 在左側功能表中,選取 [金鑰和端點]。 您將使用 API 要求的端點和金鑰
查詢您的模型
使用下列 URL、標頭和 JSON 本文來建立 POST 要求,以開始測試交談語言理解模型。
要求 URL
{ENDPOINT}/language/:analyze-conversations?api-version={API-VERSION}
| 預留位置 |
值 |
範例 |
{ENDPOINT} |
用於驗證 API 要求的端點。 |
https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
您正在呼叫的 API 版本。 |
2023-04-01 |
使用下列標頭來驗證您的要求。
| 機碼 |
值 |
Ocp-Apim-Subscription-Key |
資源的金鑰。 用於驗證 API 要求。 |
要求本文
{
"kind": "Conversation",
"analysisInput": {
"conversationItem": {
"id": "1",
"participantId": "1",
"text": "Text 1"
}
},
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}",
"stringIndexType": "TextElement_V8"
}
}
| 機碼 |
預留位置 |
值 |
範例 |
participantId |
{JOB-NAME} |
|
"MyJobName |
id |
{JOB-NAME} |
|
"MyJobName |
text |
{TEST-UTTERANCE} |
您想要預測其意圖並從中擷取實體的語句。 |
"Read Matt's email |
projectName |
{PROJECT-NAME} |
您專案的名稱。 此值區分大小寫。 |
myProject |
deploymentName |
{DEPLOYMENT-NAME} |
您部署的名稱。 此值區分大小寫。 |
staging |
傳送要求之後,您會收到下列回應以進行預測
回應本文
{
"kind": "ConversationResult",
"result": {
"query": "Text1",
"prediction": {
"topIntent": "inten1",
"projectKind": "Conversation",
"intents": [
{
"category": "intent1",
"confidenceScore": 1
},
{
"category": "intent2",
"confidenceScore": 0
},
{
"category": "intent3",
"confidenceScore": 0
}
],
"entities": [
{
"category": "entity1",
"text": "text1",
"offset": 29,
"length": 12,
"confidenceScore": 1
}
]
}
}
}
| 機碼 |
範例值 |
描述 |
| query |
「讀出 Matt 的電子郵件」 |
為了查詢而提交的文字。 |
| topIntent |
「讀出」 |
具備最高信賴分數的預測意圖。 |
| 意圖 |
}, |
針對查詢文字預測的所有意圖清單,其中每個意圖都有信賴分數。 |
| 實體 |
}, |
陣列,其中包含從查詢文字中擷取的實體清單。 |
交談專案的 API 回應
在交談專案中,您將為您的意圖和專案內存在的實體取得預測。
- 這些意圖和實體包含 0.0 到 1.0 之間的信賴分數,其與模型預測專案中特定元素的信心程度相關。
- 最高分的意圖是包含在其自己的參數內。
- 只有預測的實體才會顯示在您的回應中。
- 實體指出:
- 已擷取的實體文字
- 其由位移值表示的起始位置
- 由長度值表示的實體文字長度。