檔智慧批次分析
批次分析 API 可讓您使用一個非同步要求來大量處理多份文件。 您不必個別提交文件並追蹤多個要求標識符,而是可以同時分析發票、一系列貸款檔或一組自定義檔等檔集合。 批次 API 支援從 Azure Blob 記憶體讀取檔,並將結果寫入 Blob 記憶體。
- 若要利用批次分析,您需要具有來源文件和已處理輸出之特定容器的 Azure Blob 儲存體帳戶。
- 完成時,批次作業結果會列出所有已處理的個別文件及其狀態 (例如
succeeded、skipped或failed)。 - 此 Batch API 預覽版本可透過隨用隨付定價取得。
批次分析指引
每個批次分析要求處理的文件數目上限 (包括跳過的文件) 為 10,000 個。
作業結果會在完成後保留 24 小時。 文件和結果會位於提供的儲存體帳戶中,但作業狀態在完成 24 小時後將不再提供。
準備開始了嗎?
必要條件
您需要作用中的 Azure 訂用帳戶。 若還沒有 Azure 訂閱,您可以建立免費帳戶。
擁有 Azure 訂閱之後,請在 Azure 入口網站中建立文件智慧服務執行個體。 您可以使用免費定價層 (
F0) 來試用服務。部署資源之後,請選取 [前往資源] 擷取金鑰與端點。
- 您需要使用資源的金鑰和端點,將應用程式連線至文件智慧服務。 您稍後會在快速入門中將金鑰和端點貼到程式碼中。 您可以在 Azure 入口網站的 [金鑰和端點] 頁面上找到這些值。
Azure Blob 儲存體帳戶。 您將在 Azure Blob 儲存體帳戶中為您的來源和結果檔案建立容器:
- 來源容器。 此容器是上傳檔案進行分析的位置 (必要)。
- 結果容器。 此容器是已處理檔案的儲存位置 (必要)。
您可以為來源和已處理的文件指定相同的 Azure Blob 儲存體容器。 不過,為了盡可能避免意外覆寫資料,建議您選擇不同的容器。
儲存體容器授權
您可以選擇下列其中一個選項來授權文件服務資源的存取權。
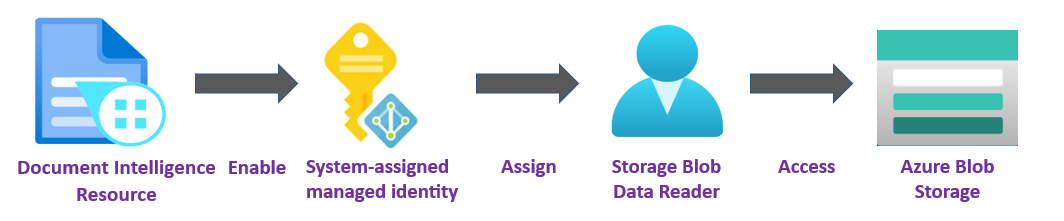
✔️ 受控識別。 受控識別是一種服務主體,其會建立 Microsoft Entra 身分識別和 Azure 受控資源的特定權限。 受控識別可讓您執行文件智慧服務應用程式,而不需要在程式碼中內嵌認證。 受控識別提供更安全的方式來授與儲存體資料的存取權,並取代您包含共用存取簽章權杖 (SAS) 與您的來源和結果 URL 的需求。
若要深入瞭解,請參閱設定文件智慧服務的受控識別。
重要
- 使用受控識別時,請勿在 HTTP 要求中包含 SAS 權杖 URL,否則您的要求將會失敗。 使用受控識別可取代您包含共用存取簽章權杖 (SAS) 的需求。
✔️ 共用存取簽章 (SAS)。 共用存取簽章是一個 URL,可將受限制的存取權授與文件智慧服務一段時間。 若要使用此方法,您必須為來源和結果容器建立共用存取簽章 (SAS) 權杖。 來源和結果容器必須包含共用存取簽章 (SAS) 權杖,並附加為查詢字串。 權杖可以指派給您的容器或特定 Blob。

- 您的來源容器或 Blob 必須指定讀取、寫入、列出和刪除權限。
- 您的結果容器或 Blob 必須指定寫入、列出、刪除權限。
若要深入了解,請參閱建立 SAS 權杖。
呼叫批次分析 API
- 為
azureBlobSource或azureBlobFileListSource物件內的來源文件集指定 Azure Blob 儲存體容器 URL。
指定輸入檔
批次 API 支援兩個選項來指定要處理的檔案。 如果您需要處理容器或資料夾中的所有檔案,且檔案數目小於單一批次要求的10000個限制,請使用 azureBlobSource 容器。
如果您在容器或資料夾中有要處理的特定檔案,或要處理的檔案數目超過單一批次的最大限制,請使用 azureBlobFileListSource。 將數據集分割成多個批次,並在容器的根資料夾中新增要以 JSONL 格式處理的檔案清單。 檔案清單格式的範例為 。
{"file": "Adatum Corporation.pdf"}
{"file": "Best For You Organics Company.pdf"}
指定結果位置
使用 resultContainerUrl,為您的批次分析結果指定 Azure Blob 儲存體容器 URL。 為了避免意外覆寫,建議您針對來源和已處理的文件使用不同的容器。
如果您不想覆寫具有相同檔名的任何現有結果,請將 overwriteExisting 布爾值屬性設定為 false。 此設定不會影響計費,而且只會防止在處理輸入檔案之後覆寫結果。
resultPrefix將 設定為 命名空間,此批次 API 執行的結果。
- 如果您打算針對輸入和輸出使用相同的容器,請設定
resultContainerUrl和resultPrefix以符合您的輸入azureBlobSource。 - 使用相同的容器時,您可以包含
overwriteExisting欄位,以決定是否要使用分析結果檔覆寫任何檔案。
建置並執行 POST 要求
執行 POST 要求之前,請將 {your-source-container-SAS-URL} 和 {your-result-container-SAS-URL} 取代為您的 Azure Blob 儲存體容器執行個體的值。
下列範例示範如何將 屬性新增 azureBlobSource 至要求:
只允許一個 azureBlobSource 或 azureBlobFileListSource。
POST /documentModels/{modelId}:analyzeBatch
{
"azureBlobSource": {
"containerUrl": "https://myStorageAccount.blob.core.windows.net/myContainer?mySasToken",
"prefix": "trainingDocs/"
},
"resultContainerUrl": "https://myStorageAccount.blob.core.windows.net/myOutputContainer?mySasToken",
"resultPrefix": "layoutresult/",
"overwriteExisting": true
}
下列範例示範如何將 屬性新增 azureBlobFileListSource 至要求:
POST /documentModels/{modelId}:analyzeBatch
{
"azureBlobFileListSource": {
"containerUrl": "https://myStorageAccount.blob.core.windows.net/myContainer?mySasToken",
"fileList": "myFileList.jsonl"
},
"resultContainerUrl": "https://myStorageAccount.blob.core.windows.net/myOutputContainer?mySasToken",
"resultPrefix": "customresult/",
"overwriteExisting": true
}
成功回應
202 Accepted
Operation-Location: /documentModels/{modelId}/analyzeBatchResults/{resultId}
擷取批次分析 API 結果
執行 Batch API 作業之後,您可以使用 GET 作業來擷取批次分析結果。 此作業會擷取作業狀態資訊、作業完成百分比,以及作業建立和更新日期/時間。
GET /documentModels/{modelId}/analyzeBatchResults/{resultId}
200 OK
{
"status": "running", // notStarted, running, completed, failed
"percentCompleted": 67, // Estimated based on the number of processed documents
"createdDateTime": "2021-09-24T13:00:46Z",
"lastUpdatedDateTime": "2021-09-24T13:00:49Z"
...
}
解譯狀態訊息
針對每個文件集,會指派一個狀態,可能是 succeeded、failed 或 skipped。 針對每個文件,會提供兩個 URL 來驗證結果:sourceUrl 是成功輸入文件的來源 Blob 儲存體容器,而 resultUrl 是結合 resultContainerUrl 和resultPrefix 建構而成,以建立來源檔案的相對路徑和 .ocr.json。
狀態
notStarted或running。 批次分析作業未起始或未完成。 請等候所有文件的作業完成。狀態
completed。 批次分析作業已完成。狀態
failed。 批次作業失敗。 如果要求整體有問題,通常會出現此回應。 批次報表回應中會傳回個別檔案的失敗,即使所有檔案都失敗也一樣。 例如,儲存體錯誤不會停止整個批次作業,因此您可以透過批次報表回應存取部分結果。
只有具有 succeeded 狀態的檔案才會在回應中產生 resultUrl 屬性。 這可讓模型訓練偵測以 .ocr.json 結尾的檔案名稱,並將其識別為唯一可用於訓練的檔案。
succeeded 狀態回應的範例如下:
[
"result": {
"succeededCount": 0,
"failedCount": 2,
"skippedCount": 2,
"details": [
{
"sourceUrl": "https://{your-source-container}/myContainer/trainingDocs/file2.jpg",
"status": "failed",
"error": {
"code": "InvalidArgument",
"message": "Invalid argument.",
"innererror": {
"code": "InvalidSasToken",
"message": "The shared access signature (SAS) is invalid: {details}"
}
}
}
]
}
]
...
failed 狀態回應的範例如下:
- 只有在整體批次要求中有錯誤時,才會傳回此錯誤。
- 批次分析作業啟動之後,個別文件作業狀態不會影響整體批次工作的狀態,即使所有檔案的狀態都是
failed也一樣。
[
"result": {
"succeededCount": 0,
"failedCount": 2,
"skippedCount": 2,
"details": [
"sourceUrl": "https://{your-source-container}/myContainer/trainingDocs/file2.jpg",
"status": "failed",
"error": {
"code": "InvalidArgument",
"message": "Invalid argument.",
"innererror": {
"code": "InvalidSasToken",
"message": "The shared access signature (SAS) is invalid: {details}"
}
}
]
}
]
...
skipped 狀態回應的範例如下:
[
"result": {
"succeededCount": 3,
"failedCount": 0,
"skippedCount": 2,
"details": [
...
"sourceUrl": "https://myStorageAccount.blob.core.windows.net/myContainer/trainingDocs/file4.jpg",
"status": "skipped",
"error": {
"code": "OutputExists",
"message": "Analysis skipped because result file {path} already exists."
}
]
}
]
...
批次分析結果可協助您藉由比較 resultUrl 中的檔案與 resultContainerUrl 中的輸出檔案,識別已成功分析哪些檔案並驗證分析結果。
注意
在完成整份文件集批次分析之前,不會傳回個別檔案的分析結果。 若要追蹤 percentCompleted 以外的詳細進度,您可以在寫入 resultContainerUrl 時監視 *.ocr.json 檔案。