使用 Azure AI 文件智慧服務進行擷取擴增生成
此內容適用於: ![]() v4.0 (GA)
v4.0 (GA)
簡介
擷取增擴生成 (RAG) 是一種設計模式,其結合了像是 ChatGPT 的預先定型大型語言模型 (LLM) 與外部資料擷取系統,以產生包含原始定型資料以外新資料的增強式回應。 將資訊擷取系統新增至您的應用程式,可讓您與文件聊天、產生迷人的內容,以及為您的資料存取 Azure OpenAI 模型的強大功能。 您還可以更好地控制 LLM 在制訂回應時所使用的資料。
文件智慧服務版面配置模型是進階機器學習型文件分析 API。 版面配置模型會提供適用於進階內容擷取和文件結構分析功能的全方位解決方案。 透過版面配置模型,您可以輕鬆地擷取文字和結構元素,根據語意內容將大型文字主體分割成較小的有意義區塊,而不是任意分割。 擷取的資訊可以方便地輸出至 Markdown 格式,讓您可以根據提供的建置區塊定義語意區塊化策略。
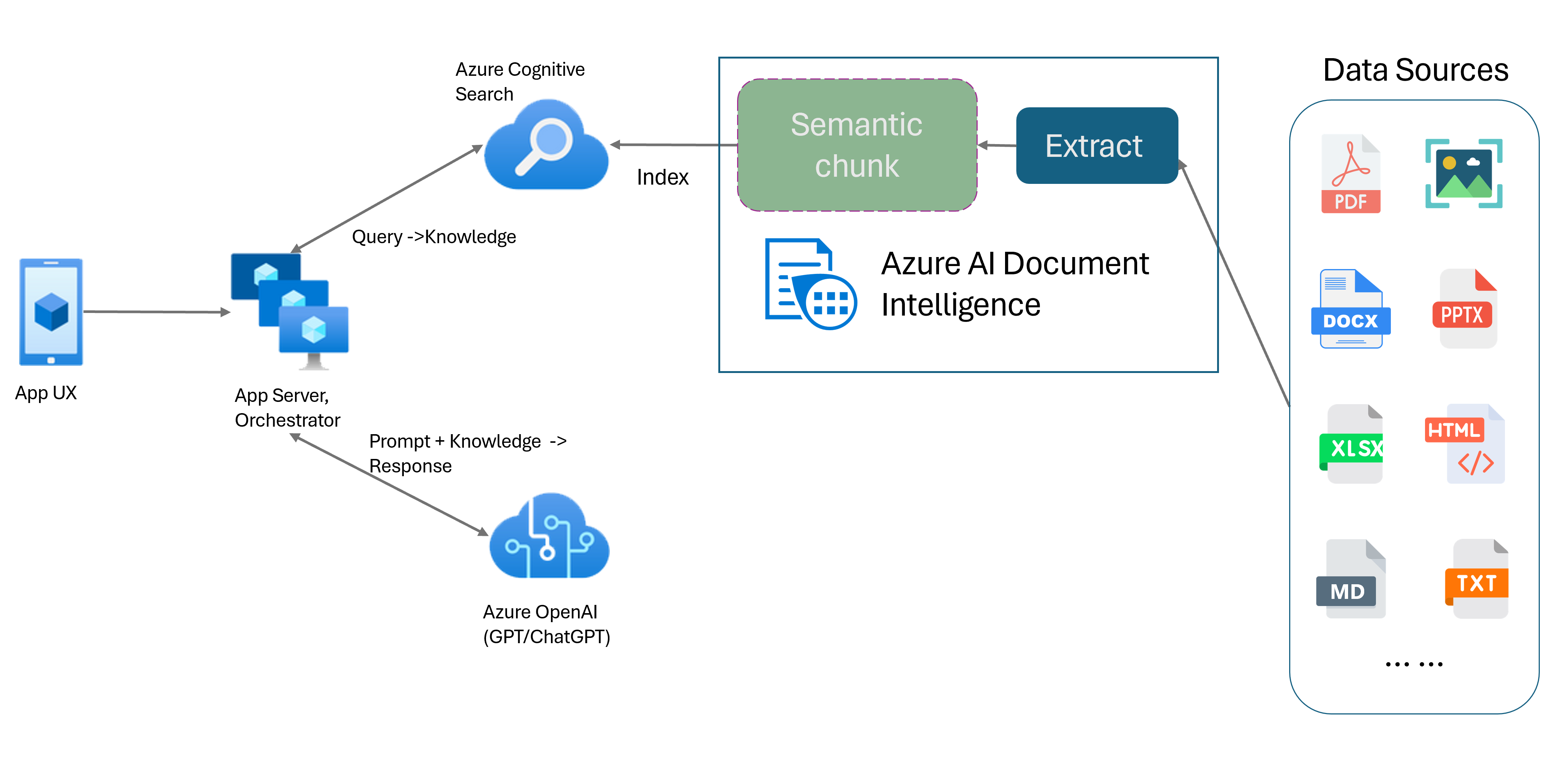
語意區塊化
對於自然語言處理 (NLP) 應用程式來說,長句子具有挑戰性。 特別是在其是由多個子句、複雜的名詞或動詞片語、關係子句和括號群組所組成的時候。 就像旁觀者一樣,NLP 系統也需要成功追蹤所有呈現的相依性。 語意區塊化的目標是尋找句子表示法的語意連貫片段。 然後,可以獨立處理這些片段,並重新組合為語意表示法,而不會失去資訊、解釋或語意相關性。 文字的內在意義會當做區塊化流程的指南使用。
文字資料區塊化策略在最佳化 RAG 回應和效能方面扮演重要角色。 固定大小和語意是兩種不同的區塊化方法:
固定大小區塊化。 現今 RAG 中使用的大部分區塊化策略都是以固定大小的文字區段 (稱為區塊) 為基礎。 對於記錄和資料等不具強式語義結構的文字,固定大小區塊化快速、簡單且有效。 不過,不建議用於需要語意理解和精確內容的文字。 視窗的固定大小本質可能會導致字組、句子或段落斷開,從而妨礙理解力並擾亂資訊和理解的流動。
語意區塊化。 此方法會根據語意理解將文字分成區塊。 劃分界限集中於句子主詞,並使用大量且計算演算法複雜的資源。 不過,其具有維護每個區塊內語意一致的明顯優勢。 其適用於文字摘要、情感分析和文件分類工作。
使用文件智慧服務版面配置模型進行語意區塊化
Markdown 是結構化且格式化的標記語言,也是在 RAG (擷取擴增生成)中啟用語意區塊化的熱門輸入。 您可以使用來自版面配置模型的 Markdown 內容,根據段落界限分割文件、建立資料表的特定區塊,以及微調您的區塊化策略,以改善所產生回應的品質。
使用版面配置模型的優勢
簡化處理。 您可以剖析不同的文件類型,例如數位和掃描的 PDF、影像、Office 檔案 (docx、xlsx、pptx) 和 HTML,只需進行單一 API 呼叫即可。
可擴縮性和 AI 品質。 版面配置模型在光學字元辨識 (OCR)、資料表擷取和文件結構分析方面具有高度可擴縮性。 其支援 309 種列印語言和 12 種手寫語言,進一步確保 AI 功能推動的高品質結果。
大型語言模型 (LLM) 相容性。 版面配置模型 Markdown 格式化的輸出對 LLM 是友善的,並可協助無縫地整合至您的工作流程。 您可以將文件中的任何資料表轉換成 Markdown 格式,並避免大量剖析文件的工作,以取得更深的 LLM 理解。
使用文件智慧服務工作室處理,並使用版面配置模型輸出至 MarkDown 的文字影像

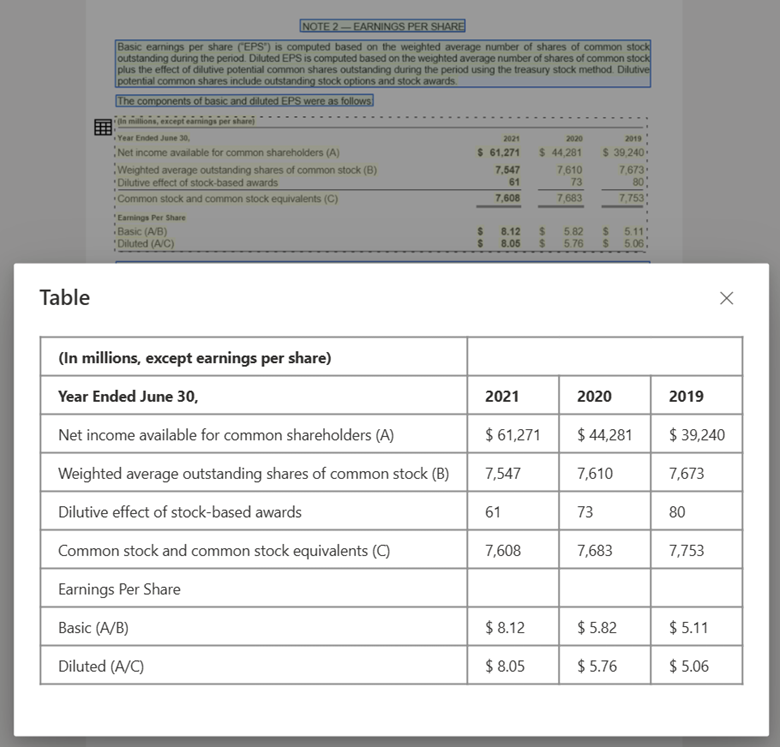
使用版面配置模型搭配文件智慧服務工作室處理的資料表影像
開始使用
檔案智慧版面配置模型 2024-11-30 (GA) 支援下列開發選項:
準備好開始了嗎?
Document Intelligence Studio
您可以遵循文件智慧服務工作室快速入門以開始。 接下來,您可以使用提供的範例程式碼,整合文件智慧服務功能與您自己的應用程式。
從版面配置模型開始。 您必須選取下列 [分析選項],才能在工作室中使用 RAG:
**Required**- 執行分析範圍 → 目前檔案。
- 頁面範圍 → 所有頁面。
- 輸出格式樣式 → Markdown。
**Optional**- 您也可以選取相關的選用偵測參數。
選取 [儲存]。
![文件智慧服務工作室中 [分析選項] 對話方塊視窗的螢幕擷取畫面,其中具有 RAG 必要選項。](../media/rag/rag-analyze-options.png?view=doc-intel-3.1.0)
選取 [執行分析] 按鈕來檢視輸出。
![文件智慧工作室中 [執行分析] 按鈕的螢幕擷取畫面。](../media/rag/run-analysis.png?view=doc-intel-3.1.0)
SDK 或 REST API
您可以遵循文件智慧服務快速入門,以取得您慣用的程式設計語言 SDK 或 REST API。 使用版面配置模型,從您的文件擷取內容和結構。
您也可以查看 GitHub 存放庫,以取得程式碼範例,以及使用 Markdown 輸出格式分析文件的秘訣。
使用語意區塊化建置文件聊天
Azure OpenAI on Your Data 可讓您在文件上執行支援的聊天。 Azure OpenAI on Your Data 會套用文件智慧服務版面配置模型,來擷取和剖析文件資料,方法是根據資料表和段落將長文字區塊化。 您也可以使用位於 GitHub 存放庫中的 Azure OpenAI 範例指令碼自訂區塊化策略。
Azure AI 文件智慧服務現在已與 LangChain 整合為其中一個文件載入器。 您可以使用此文件載入器,輕鬆地載入資料並輸出為 Markdown 格式。 如需詳細資訊,請參閱我們的範例程式碼,其會顯示 RAG 模式的簡單示範,其中 Azure AI 文件智慧服務作為文件載入器,而 Azure 搜尋服務作為 LangChain 中的擷取器。
與資料解決方案加速器程式碼範例的聊天示範了端對端基準 RAG 模式範例。 其會使用 Azure AI 搜尋服務 (作為擷取器) 和 Azure AI 文件智慧服務,進行文件載入和語意區塊化。
使用案例
如果您要尋找文件中的特定章節,則可以使用語意區塊化,根據章節標題將文件分割成較小的區塊,以協助您快速且輕鬆地找到您正在尋找的章節:
# Using SDK targeting 2024-11-30 (GA), make sure your resource is in one of these regions: East US, West US2, West Europe
# pip install azure-ai-documentintelligence==1.0.0b1
# pip install langchain langchain-community azure-ai-documentintelligence
from azure.ai.documentintelligence import DocumentIntelligenceClient
endpoint = "https://<my-custom-subdomain>.cognitiveservices.azure.com/"
key = "<api_key>"
from langchain_community.document_loaders import AzureAIDocumentIntelligenceLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
# Initiate Azure AI Document Intelligence to load the document. You can either specify file_path or url_path to load the document.
loader = AzureAIDocumentIntelligenceLoader(file_path="<path to your file>", api_key = key, api_endpoint = endpoint, api_model="prebuilt-layout")
docs = loader.load()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_string = docs[0].page_content
splits = text_splitter.split_text(docs_string)
splits
下一步
深入了解 Azure AI 文件智慧服務。
完成 Document Intelligence 快速入門,並開始以您選擇的開發語言來建立文件處理應用程式。