適用於初學者的自訂翻譯工具
自訂翻譯工具可讓您根據自己的業務、產業和特定領域的術語和文風來建立翻譯系統。 定型和部署自訂系統很簡單,而且不需要任何程式設計技能。 自訂翻譯系統可無縫整合到您現有的應用程式、工作流程和網站中,並且可以透過每天處理數十億次翻譯的雲端式 Microsoft 文字翻譯 API 服務在 Azure 上使用。
該平台可讓使用者建置並發佈將其他語言翻成英文,或將英文翻譯成其他語言的自訂翻譯系統。 自訂翻譯工具支援超過 60 種語言,並會直接對應至類神經機器翻譯 (NMT) 可用的語言。 如需完整清單,請參閱翻譯工具語言支援。
自訂翻譯模型對我來說是否是正確的選擇?
經過妥善訓練的自訂翻譯模型可提供更精確的特定網域翻譯,因為它依賴先前翻譯的網域內文件來學習慣用的翻譯。 翻譯工具會在上下文中使用這些詞彙和片語,以目標語言產生通順的翻譯,同時遵守與上下文相關的文法。
定型完整的自訂翻譯模型需要大量的資料。 如果您沒有至少 10,000 句過去訓練之文件的句子,您無法訓練完整的語言翻譯模型。 不過,您可以選擇定型一個僅限字典的模型,或使用文字翻譯 API 所提供的高品質現成翻譯。
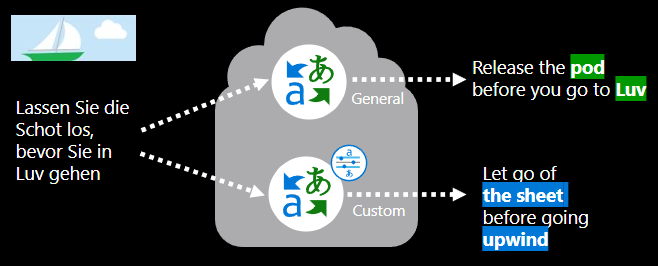
定型自訂翻譯模型會牽涉到什麼?
要建立自訂翻譯模型需要:
了解您的使用案例。
取得領域內的翻譯資料 (人工翻譯為佳)。
評估翻譯品質或目標語言翻譯。
如何評估我的使用案例?
清楚了解您的使用案例和成功案例的樣子,是取得精準訓練資料的第一步。 以下是幾項考量重點:
是否已指定您所需的結果,以及其測量方式?
是否已識別您的商務領域?
您有使用類似術語和文風的專業領域句子嗎?
您的使用案例是否牽涉到多個領域? 如果是,您應該建立一個還是多個系統?
您是否有會影響到待用和傳輸中區域資料落地的要求?
目標使用者是位於一個還是多個區域中?
如何取得資料?
尋找網域內品質資料的工作會根據使用者分類而有所不同,通常是一項具有挑戰性的工作。 以下是一些在評估哪些資料可以使用時,您可以先詢問自己的問題:
貴公司是否有先前的翻譯資料可供使用? 企業通常會有豐富的翻譯資料,累積了數年來使用人工翻譯的結果。
您是否有大量的單一語言資料? 單一語言資料是只有一種語言的資料。 如果是,您可以取得此資料的翻譯嗎?
您可以搜耙線上入口網站來收集來源句子和目標合成句子嗎?
我應該用什麼來當訓練資料?
| 來源 | 作用 | 要遵守的規則 |
|---|---|---|
| 雙語定型文件 | 教系統學習您的術語和文風。 | 自由一點。 任何領域內的人工翻譯都比機器翻譯還要好。 在訓練的同時新增和移除文件,並試著改善 BLEU 分數。 |
| 微調文件 | 訓練神經機器翻譯參數。 | 嚴格一點。 以最能代表您未來要翻譯的內容來撰寫。 |
| 測試文件 | 計算 BLEU 分數。 | 嚴格一點。 以最能代表您未來預計要翻譯的內容來撰寫測試文件。 |
| 片語字典 | 一律強制使用指定的翻譯。 | 嚴格一點。 片語字典會區分大小寫,且會以您指定的方式對任何列出的單字或片語進行翻譯。 在許多情況下,讓系統學習會比使用片語字典還要好。 |
| 句子字典 | 一律強制使用指定的翻譯。 | 嚴格一點。 句子字典不會區分大小寫,比較適合在網域裡的簡短句子。 假設要比對句子字典,整個提交的句子就必須符合原始字典項目。 如果只有一部分的句子符合,則不會比對項目。 |
什麼是 BLEU 分數?
BLEU (雙語評估替補) 是一種演算法,可用來評估從某種語言翻譯為另一種語言的文字精確度或正確性。 自訂翻譯工具使用 BLEU 計量作為傳達翻譯正確性的一種方式。
BLEU 分數是介於零到 100 之間的數字。 分數零表示低品質翻譯,其中翻譯中沒有任何項目符合參考。 分數 100 指出與參考完全相同的完美翻譯。 不需要取得分數 100:BLEU 40 到 60 之間的分數表示高品質翻譯。
如果我不提交微調或測試資料,會發生什麼事?
微調和測試例句是最能代表您未來預計要翻譯之內容的句子。 如果您未提交任何調整或測試資料,自訂翻譯工具會自動從訓練文件中排除句子來作為調整和測試資料。
| 系統產生 | 手動選取 |
|---|---|
| 方便。 | 為您未來的需求進行微調。 |
| 很好,如果您知道您的定型資料代表您打算翻譯的內容。 | 更自由地撰寫定型資料。 |
| 擴大或縮小領域時可以輕鬆重做。 | 允許更多資料和更佳的領域涵蓋率。 |
| 變更每個定型回合。 | 在重複的定型回合中保持固定 |
自訂翻譯工具如何處理訓練資料?
如要為訓練做準備,文件需進行一系列的處理程序和篩選步驟。 篩選流程的知識可協助您了解顯示的句子數目,以及您可採取哪些步驟來準備定型文件,以便使用「自訂翻譯工具」進行定型。 篩選步驟如下:
句子對齊
如果文件不是
XLIFF、XLSX、TMX或ALIGN格式,則「自訂翻譯」會逐句對齊來源與目標文件的句子。 翻譯工具不會執行文件對齊,而是會依照您的文件命名慣例來尋找其他語言的相符文件。 在來源文字中,「自訂翻譯工具」會嘗試在目標語言中尋找對應的句子。 它會使用文件標記 (如內嵌 HTML 標記) 來協助對齊。如果您看到來源與目標端文件中的句子數目大不相符,則您的文件可能未平行,或者無法對齊。 您需要再次查看每一端上句子差異很大 (>10%) 的文件配對,以確保它們確實平行。
調整和測試資料擷取
微調和測試資料是選擇性的。 若未提供,系統會從訓練文件中取出適當百分比的資料,以用於調整和測試。 移除動作會在定型的流程中同時進行。 由於此步驟會在定型的流程中發生,因此上傳的文件不會受到影響。 您可以在訓練成功之後,在 [模型詳細資料] 頁面上查看每個資料類別 (訓練、調整、測試和字典) 最終使用的句子數目。
長度篩選
- 移除任一邊只有一個字組的句子。
- 移除任一邊有超過 100 個字組的句子。 中文、日文、韓文均豁免。
- 移除少於三個字元的句子。 中文、日文、韓文均豁免。
- 移除具有超過 2000 個中文、日文、韓文字元的句子。
- 移除具有少於 1% 英數字元的句子。
- 移除包含超過 50 個字組的字典項目。
空白字元
- 以單一空格字元,取代任何空白字元序列,包括索引標籤和 CR/LF 序列。
- 移除句子中的前置或尾端空格。
句子結尾標點符號
以單一執行個體取代多個句子結尾標點符號字元。 日文字元正規化。
將全形字母和數字轉換成半形字元。
未逸出的 XML 標記
將未逸出的標記轉換成逸出的標記:
標籤 變成 < < > > & & 無效字元
「自訂翻譯」會移除包含 Unicode 字元 U+FFFD 的句子。 字元 U+FFFD 表示編碼轉換失敗。
上傳資料之前,我應該執行哪些步驟?
- 移除編碼無效的句子。
- 移除 Unicode 控制字元。
- 如果可以的話,請將句子對齊 (來源對目標)。
- 移除不符合來源和目標語言的來源和目標句子。
- 當來源和目標句子中混有不同語言時,請確定未翻譯的字組是刻意不翻譯的,例如組織和產品的名稱。
- 請確定文法和印刷樣式正確,以避免對模型進行錯誤教學。
- 一個來源句子對應至一個目標句子。 雖然我們的訓練程式會處理包含多個句子的來源和目標行,但一對一對應是最佳做法。
如何評估結果?
成功定型模型之後,您可以在 [模型詳細資料] 頁面上檢視模型的 BLEU 分數和基準模型的 BLEU 分數。 我們使用同一組測試資料,以產生模型的 BLEU 分數和基準 BLEU 分數。 此資料可協助您做出明智的決策,以決定哪一個模型最適合您的使用案例。