Memory Models
Understand the Impact of Low-Lock Techniques in Multithreaded Apps
Vance Morrison
This article discusses:
|
This article uses the following technologies: .NET Framework 2.0 |
Contents
Principles of Safe Multithreaded Access
The Need for Memory Models
A Relaxed Model: ECMA
Strong Model 1: x86 Behavior
Strong Model 2: .NET Framework 2.0
Technique 1: Avoiding Locks on Some Reads
Interlocked Operations
Technique 2: Spin Locks
Technique 3: Direct Interlocked Updates
Technique 4: Lazy Initialization
A Final Word of Warning
Conclusion
I n my recent article on writing multithreaded applications (see "Concurrency: What Every Dev Must Know About Multithreaded Apps"), I outlined the basic principles of multithreaded programs, explained why most multithreaded programs are full of concurrency bugs (races), and illustrated a locking protocol that can keep such bugs out of your programs. Unfortunately, the locks introduced by this protocol have overhead that can sometimes be an issue, which raises the question of whether it is possible to avoid the overhead of methodically locking and still write correct, multithreaded programs?
In some cases you can avoid the locking overhead; however, an improvement in performance comes with two significant software engineering costs. First, low-lock techniques can only be applied in narrow circumstances, and can easily be misapplied or broken by later code modifications, introducing difficult-to-find bugs. Second, low-lock techniques rely on details of the memory system and compiler that were previously irrelevant. These details now must be precisely specified, understood, and validated before using these techniques.
Since using low-lock techniques significantly increases the likelihood of introducing hard-to-find bugs, it is best to use them only when the performance benefit is absolutely clear and necessary. My goal here is not to encourage the use of low-lock techniques, but rather to demonstrate their limitations and subtleties, so that if you are forced to use them (or have to read code that uses them), you have a better chance of using them correctly.
Principles of Safe Multithreaded Access
The biggest conceptual difference between sequential and multithreaded programs is the way the programmer should view memory. In a sequential program, memory can be thought of as being stable unless the program is actively modifying it. For a multithreaded program, however, it is better to think of all memory as spinning (being changed by other threads) unless the programmer does something explicit to freeze (or stabilize) it.
All memory that a thread accesses should be frozen before use. This happens naturally for memory that is read-only or is never given out to more than one thread (for example, local variables). For read/write, thread-shared memory, the only way to freeze memory is to use locks. It is not sufficient, however, just to take a lock. It is necessary that all the code that accesses a particular memory location take the same lock. Only then will holding the lock ensure that no other thread is concurrently modifying the location.
In practice, every region of thread-shared, read/write memory is assigned a lock that protects it. Before any operation begins, all the memory that will be accessed must be frozen by entering one or more locks. The operation can then proceed as in a sequential program. Once the operation is complete, the locks can be released and other threads get their turn. This is the locking protocol that I described in depth in my previous article.
The protocol gives the programmer a lot of freedom in making two key design decisions. The first is how much memory is protected by a particular lock and, as a result, how many locks a program needs to cover all thread-shared, read/write memory. The second is how long the locks are held. The sooner a lock is released, the sooner another thread can use the memory protected by that lock. However, once a lock is released, its value is no longer stable and care must be taken to ensure this does not break the algorithm.
There is a spectrum of possible design choices. On one extreme, all thread-shared, read/write memory could be protected by a single lock that is held for large units of work. This design is likely to be race-free, but affords relatively few opportunities for multiple threads to run concurrently. On the other extreme, every memory location could have its own independent lock, and each lock is only held for the minimum time needed to update that location. This design allows for more concurrency but is more complex, significantly more error prone, and increases lock overhead (since locks are entered and released often).
It is at this latter extreme where lock-free techniques become applicable. Conceptually, if the time a lock needs to be held can be shrunk to a single memory access, then it is possible to take advantage of the hardware to avoid some or all of the locking overhead. Unfortunately, having many small regions protected by different locks is the most error prone part of the design spectrum. It is all too easy to forget to take a lock, or not to hold the lock long enough, and thus introduce races. On top of that, when you omit locks, a whole new level of complexity related to the machine's memory model comes into play. Understanding memory models is thus part of the price for using low-lock techniques.
The Need for Memory Models
In any multithreaded system that includes memory shared among threads, there needs to be a specification (called a memory model) that states exactly how memory accesses from various threads interact. The simplest such model is called sequential consistency and is shown in Figure 1. In this model, memory is independent of any of the processors (threads) that use it. The memory is connected to each of the threads by a controller that feeds read and write requests from each thread. The reads and writes from a single thread reach memory in exactly the order specified by the thread, but they might be interleaved with reads and writes from other threads in an unspecified way.
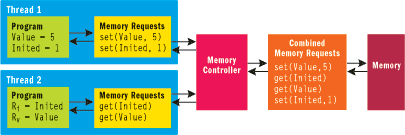
Figure 1** Sequential Consistency Memory Model **
In the example shown in Figure 1, a variable called Value needs to be initialized, and a flag called Inited is used to indicate that this has happened. Inited and Value start out at 0. Thread 1 first initializes Value (in this case, to 5) and indicates that it did this by setting Inited to 1. Thread 2 reads these values into registers Rv and Ri. In a sequential program it would be impossible to have the combination where Ri is 1 (indicating the value was initialized) and where Rv is 0 (its uninitialized state). This also holds in a sequentially consistent memory model. The table in Figure 2 demonstrates this by enumerating all six legal permutations allowed by sequential consistency and determining what the final values of Ri and Rv are. In no case is Ri nonzero and Rv zero.
Figure 2 Possible Permutations of Memory Requests
| Memory Requests as Seen from Memory | Final Result of Thread 2 | ||||
|---|---|---|---|---|---|
| Value = 5 | Inited = 1 | Ri = Inited | Rv = Value | 1 | 5 |
| Value = 5 | Ri = Inited | Inited = 1 | Rv = Value | 0 | 5 |
| Value = 5 | Ri = Inited | Rv = Value | Inited = 1 | 0 | 5 |
| Ri = Inited | Rv = Value | Value = 5 | Inited = 1 | 0 | 0 |
| Ri = Inited | Value = 5 | Rv = Value | Inited = 1 | 0 | 5 |
| Ri = Inited | Value = 5 | Inited = 1 | Rv = Value | 0 | 5 |
Sequential consistency is an intuitive model and, as the previous example shows, some of the concepts of sequential programs can be applied to it. It is also the model that gets implemented naturally on single-processor machines so, frankly, it is the only memory model most programmers have practical experience with. Unfortunately, for a true multiprocessor machine, this model is too restrictive to be implemented efficiently by memory hardware, and no commercial multiprocessor machines conform to it.
The memory system for a multiprocessor machine typically looks more like Figure 3. Each processor would have a relatively small cache of very fast memory that remembers the most recent data that was accessed. In addition, all writes to memory from the processor are typically buffered so that the processor can continue on to the next instruction before the write gets flushed to even the first level of cache. Typically, there is at least one more level of larger but slower cache before data finally reaches memory that is shared among processors. This architecture speeds up the processor, but also means that there is no longer one single view of memory. It is now possible for the caches to be incoherent in the sense that one processor's cache has one value for a particular memory location, while another processor's cache has an old stale version of that same memory location.
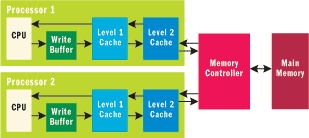
Figure 3** Realistic Memory System **
While this might seem universally undesirable, it only causes problems if this incoherent memory is being used to communicate between threads. If each thread flushes its caches as part of the communication handshake, a reliable system can be created. Such a system is very efficient because the expense of keeping the caches in sync is only incurred when threads are using the memory to communicate, which is a small percentage of all memory accesses.
The bottom line is that real memory systems, such as that shown in Figure 3, do not conform to the sequentially consistent model. Thus you are left with the problem of creating a memory model for such memory systems. A key insight in creating such a model is the following observation: the only visible effect of memory systems is to move memory accesses with respect to one another.
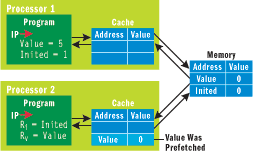
Figure 4** Initial Memory State **
Consider, for example, what happens if the Inited-Value example was run on a multiprocessor machine with a simplified cache, as show in Figure 4. In this version of the system, main memory has the initial values of 0 for both variables. Processor 1's cache is empty, but processor 2 has read Value (but not Inited) into its local cache. This could happen if Value happened to be near another value that was needed earlier in the program and the cache eagerly fetched nearby values.
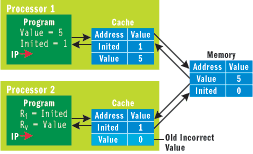
Figure 5** Incoherent Caches **
If both processors run their programs, the state changes to that shown in Figure 5. Main memory has Value set to 5 and Inited set to 1; however, because of the cache, this is not what will be seen by processor 2. When processor 2 reads the value of Inited, it will not find it in the cache and so it sees the value in main memory (Inited=1). When it reads Value, however, it will find it in the cache and see the old value of 0. Effectively, the fetch of Value has been moved from the time it actually executed on processor 2 to an earlier time when the cache was filled from main memory. Thus the program has the same behavior as if it was written as follows and run on a sequentially consistent memory model machine:
CacheTemp = Inited
Rv = Value
Ri = CacheTemp
A similar rationale applies to writes. When writes are cached, they are effectively delayed until the cache is flushed to main memory. Thus caches have the effect of causing reads to move earlier in time (to the time the cache was filled from shared memory), and writes to move later in time (to the time the cache was flushed to shared memory).
You can specify a memory model by starting with a sequentially consistent model (the most restrictive, or strongest model), and then specify how reads and writes from a single thread can be introduced, removed, or moved with respect to one another. This technique has three advantages. First, it can be specified simply but precisely without having to describe hardware details. Second, it can be related back to the source code in a straightforward manner. Caching reads can be modeled as loading the value into a temporary variable earlier than it is actually needed, and caching writes can be modeled as writing a temporary variable that is later written to the final location. Third, it can also be used to model the effect of compiler optimizations, which also have the effect of moving reads and writes. These data movements can have exactly the same issues for multithreaded programs that hardware memory hierarchies have, so it is very useful that both can be modeled using the same technique.
Clearly, the ability to arbitrarily move memory accesses anywhere at all would lead to chaos, so all practical memory models have the following three fundamental rules:
- The behavior of the thread when run in isolation is not changed. Typically, this means that a read or a write from a given thread to a given location cannot pass a write from the same thread to the same location.
- Reads cannot move before entering a lock.
- Writes cannot move after exiting a lock.
This is one more place where the locking protocol really adds value. The protocol ensures that every access to thread-shared, read/write memory only occurs when holding the associated lock. When a thread exits the lock, the third rule ensures that any writes made while the lock was held are visible to all processors. Before the memory is accessed by another thread, the reading thread will enter a lock and the second rule ensures that the reads happen logically after the lock was taken. While the lock is held, no other thread will access the memory protected by the lock, so the first rule ensures that during that time the program will behave as a sequential program.
The result is that programs that follow the locking protocol have the same behavior on any memory model having these three rules. This is an extremely valuable property. It is hard enough to write correct concurrent programs without having to think about the ways the compiler or memory system can rearrange reads and writes. Programmers who follow the locking protocol don't need to think about any of this. Once you deviate from the locking protocol, however, you must specify and consider what transformations hardware or a compiler might do to reads and writes.
A Relaxed Model: ECMA
You've seen now that sequential consistency is very constraining because it does not allow any reads or writes to be moved with respect to one another. At the other end of the spectrum are relaxed models like the one specified in Section 12, Partition I of the .NET Framework ECMA standard. This model divides memory accesses into ordinary memory accesses and those that are specially marked as "volatile". Volatile memory accesses cannot be created, deleted, or moved. Ordinary memory accesses are constrained only by the three fundamental rules for all memory models and the following two rules.
- Reads and writes cannot move before a volatile read.
- Reads and writes cannot move after a volatile write.
This gives compilers and hardware a lot of freedom to do optimization. They only have to respect the boundaries formed by locks and volatile accesses. For program fragments without locks or volatile use, optimizing compiles can do any optimization that is legal for a sequential program. It also means that the memory system only needs to do relatively expensive cache invalidation and flushing at locks and volatile accesses. This model is very efficient, but requires that programs follow the locking protocol or explicitly mark volatile accesses when using low-lock techniques.
Strong Model 1: x86 Behavior
Unfortunately, programs that correctly follow the locking protocol are more the exception than the rule. When multiprocessor systems based on the x86 architecture were being designed, the designers needed a memory model that would make most programs just work, while still allowing the hardware to be reasonably efficient. The resulting specification requires writes from a single processor to remain in order with respect to other writes, but does not constrain reads at all.
Unfortunately, a guarantee about write order means nothing if reads are unconstrained. After all, it does not matter that A is written before B if every reader reading B followed by A has reads reordered so that the pre-update value of B and the post-update value of A is seen. The end result is the same: write order seems reversed. Thus, as specified, the x86 model does not provide any stronger guarantees than the ECMA model.
It is my belief, however, that the x86 processor actually implements a slightly different memory model than is documented. While this model has never failed to correctly predict behavior in my experiments, and it is consistent with what is publicly known about how the hardware works, it is not in the official specification. New processors might break it. In this model, in addition to the three fundamental memory model rules, these rules also come into play:
- A write can only move later in time.
- A write cannot move past another write from the same thread.
- A write cannot move past a read from the same thread to the same location.
- A read can only move by going later in time to stay after a write to keep from breaking rule 3 as that write moves later in time.
This model effectively captures a system with a write buffer queue with read snooping. Writes to memory are not written to memory immediately, but instead are placed in the queue and kept in order. These writes may be delayed and thus move with respect to other reads (and reads/writes from other threads), but will keep their order with respect to other writes from the same thread. Reads effectively don't move except to allow snooping of the write queue. Every read snoops the write buffer to see if the processor recently wrote the value being read, and uses the value in the write buffer if it is found. Since the write in the write buffer does not logically happen until the entry is flushed to main memory, this read effectively gets pushed later to that time as well. Rule 4 specifically allows this action.
Strong Model 2: .NET Framework 2.0
Although the ECMA memory model for the .NET Framework specifies only weak guarantees, the only implementation of the .NET Framework 1.x runtime was on x86 machines, which meant the .NET runtime implemented a model much closer to the x86 model (it was not quite this model, however, because of just-in-time or JIT compiler optimizations). In version 2.0 of the runtime, support for weak memory model machines like those using Intel IA-64 processors creates a problem. Users of the .NET Framework could easily have been relying on the strong memory model provided by the x86 implementation and their code would break (fail nondeterministically) when run on platforms like the IA-64. Microsoft concluded that customers would be best served by a stronger memory model that would make most code that worked on x86 machines function correctly on other platforms as well. The x86 model, however, was too strong. It does not allow reads to move much at all, and optimizing compilers really need the flexibility of rearranging reads to do its job well. Another memory model was needed, and the result is the .NET Framework 2.0 runtime memory model. The rules for this model are:
- All the rules that are contained in the ECMA model, in particular the three fundamental memory model rules as well as the ECMA rules for volatile.
- Reads and writes cannot be introduced.
- A read can only be removed if it is adjacent to another read to the same location from the same thread. A write can only be removed if it is adjacent to another write to the same location from the same thread. Rule 5 can be used to make reads or writes adjacent before applying this rule.
- Writes cannot move past other writes from the same thread.
- Reads can only move earlier in time, but never past a write to the same memory location from the same thread.
Like the x86 model, writes are strongly constrained, but unlike the x86 model reads can move and can be eliminated. The model does not allow reads to be introduced, however, because this would imply refetching a value from memory, and in low-lock code memory could be changing. The last rule seems redundant, as moving a read past a write to the same location will change the value read, which would change sequential behavior. This is true if the read value is actually used. This rule is more a technicality and was added specifically to make a common lazy initialization pattern legal in this model (more on this later).
Reasoning about multithreaded programming is already hard enough. Even when using the locking protocol, you need to worry about how updates from multiple threads will interleave, but at least when using locks the granularity can be as fine or as coarse as you need. Without locks, the level of granularity is that of a single memory read or write, which increases the number of permutations dramatically. On top of this, in any memory model weaker than sequential consistency (which is every practical one), reads and writes can move with respect to one another, increasing the set of possible permutations even more dramatically. This is why so few low-lock techniques are actually correct, and why the problems can be so subtle.
Technique 1: Avoiding Locks on Some Reads
The list of low-lock techniques that are actually correct, widely applicable, and provide real performance gains is quite short. At the top of this list is the following technique for eliminating locks on read operations.
To illustrate the technique, consider a classic linked list of integers as implemented by the LinkedList class in Figure 6. This class has Push, Pop, and IsMember operations. It uses the C# lock statement to enter a lock associated with the list before performing any operation and to leave the lock before exiting the method. Thus the internal state of LinkedList is lock-protected (no read or write to internal data occurs without first entering the lock). So far, there are no low-lock techniques in use.
Figure 6 LinkedList Using the Locking Protocol
class LinkedList {
// ******** Internal types *********
private class ListNode {
public int elem;
public ListNode next;
};
// ******** Internal state *********
private ListNode head;
// ********* Constructors **********
public LinkedList() {
head = null;
}
// ******* Instance methods ********
public void Push(int elem) {
lock(this) {
ListNode newNode = new ListNode();
newNode.elem = elem;
newNode.next = head;
head = newNode;
}
}
public void Pop() {
lock(this) {
head = head.next;
}
}
public bool IsMember(int member) {
<span class="clsRed" xmlns="https://www.w3.org/1999/xhtml">lock (this) {</span>
ListNode ptr = head;
while(ptr != null) {
if (ptr.elem == member)
return true;
ptr = ptr.next;
}
return false;
<span class="clsRed" xmlns="https://www.w3.org/1999/xhtml">}</span>
}
};
Now consider the case where updates to LinkedList are relatively rare, but read accesses (calls to IsMember) are very common. In this case, the locks on Push and Pop are not problematic, but the lock on IsMember could be a performance concern. Removing this lock could be helpful. Usually, removing the lock on the IsMember method (thus breaking the locking protocol) would lead to races. However, a linked list has relatively unusual properties that can make removing the lock possible.
LinkedList is unusual because all of its mutator methods update exactly one thread-shared memory location exactly once, in particular the head field. The Push method updates other memory, too (the fields of the new ListNode), but when these are updated, the locations are thread local because they operate on new memory that other threads can't access. Because all updates have exactly one write, readers will see the list either before or after the write happens. In either case, the LinkedList is in a consistent state. If the LinkedList was doubly linked, it would not be possible to transition from one consistent state to another with a single write, so the technique could not be used. Very few data structures have this single write property that allows this optimization.
Even when the technique works, it introduces considerable subtlety to the code. For example, when locks were used, it was not important if the fields of the new node were set before or after the new node was linked into the list because no other thread could see these intermediate states. Now it is critically important that writes happen in the correct order. Because of the dependence on write ordering, memory model details come into play. In both x86 and .NET Framework 2.0 models, writes are constrained enough that the code works as expected. In the ECMA memory model, however, ordinary writes can be reordered with respect to one another and thus the code is broken unless volatile declarations are used on the head field to force a specific order of the writes.
Another subtlety is that the Pop method (or any method that reclaims memory) cannot easily be made to work in a system without garbage collection. The problem is that since threads can access ListNodes at any time without taking a lock, once memory is published, it becomes very difficult to determine whether it is still in use. Consider the following race in a system without garbage collection. Thread A calls the IsMember method, executes the ptr=head statement, and then is preempted by thread B, which calls Pop. This deletes the head node (to which the thread A ptr variable still has a reference) and places the memory on a free list. This memory immediately gets reused, overwriting the elem and next fields of the ListNode. Finally, when thread A gets to run again, it reads these fields (which are now junk), and the result will be incorrect behavior. A garbage collector avoids this problem because it reclaims objects only when references on all threads have died. For code without such smart collectors, the typical recourse is to never delete nodes if this technique is used.
A final subtlety is that readers that access multiple memory locations might read different versions of the data structure on each read. The reader has to assume that between any two reads a set of updates could happen. In the LinkedList example, the reader (IsMember) only reads a location (the head field) that is modified once, so for the x86 or .NET Framework 2.0 models the code will work as expected. For more complicated implementations, determining the correctness of the technique can be much harder.
In systems using the ECMA model, there is an additional subtlety. Even if only one memory location is fetched into a local variable and that local is used multiple times, each use might have a different value! This is because the ECMA model lets the compiler eliminate the local variable and re-fetch the location on each use. If updates are happening concurrently, each fetch could have a different value. This behavior can be suppressed with volatile declarations, but the issue is easy to miss.
This technique is the most widely applicable of the low-lock techniques, and even in this case most data structures can't use it. Typically, only data structures that are simple trees that only grow over time fit the pattern. If the data structure requires in-place updating, the technique is not likely to work. If the system does not have a garbage collector, data structures with delete operations are also problematic. Clearly low-lock techniques are very fragile and must be used with great care.
Interlocked Operations
The following optimization techniques use special interlocked instructions that perform a read/update/write action as a single atomic operation. The most generally useful interlocked operation is the CompareExchange instruction. This instruction takes three parameters: a location to modify, a value to put into that location, and a value to compare against the location. It has the semantics of the following function:
static object Lock = new System.Object();
public int CompareExchange(ref int loc, int value, int comp)
{
Monitor.Enter(Lock);
int ret = loc;
if (ret == comp)
loc = value;
Monitor.Exit(Lock);
return ret;
}
While I have defined CompareExchange by using a lock, in practice the CompareExchange instruction is the primitive operation on which all other synchronization constructs, including locks, are based. Because interlocked operations were built for cross-thread communication, they have strong ordering guarantees. No read or write can move in either direction past an interlocked operation.
Unfortunately, interlocked operations are relatively expensive, on the order of several dozen to up to hundreds of times the cost of a normal instruction. The lower bound on the cost is related to the fact that interlocked operations guarantee that the update is atomic. This requires the processor to insure that no other processor is also trying to execute an interlocked operation on the same location at the same time. This round-trip communication with the memory system can take dozens of instruction cycles. The upper bound on the cost relates to the ordering guarantee these instructions provide. Interlocked instructions need to ensure that caches are synchronized so that reads and writes don't seem to move past the instruction. Depending on the details of the memory system and how much memory was recently modified on various processors, this can be pretty expensive (hundreds of instruction cycles).
Technique 2: Spin Locks
The next technique is conceptually simple: if a lock is entered and exited frequently, use a lock optimized for that operation. A spin lock fits this bill. A simple spin lock is easily implemented using CompareExchange.
class SpinLock {
volatile int isEntered; // non-zero if the lock is entered
public void Enter() {
while(CompareExchange(ref isEntered, 1, 0) != 0) {
Thread.Sleep(0); // force a thread context switch
}
}
public void Exit() {
isEntered = 0;
}
}
The biggest difference between this simple spin lock and normal locks provided by the operating system is that a normal lock will wait on an operating system event instead of repeatedly polling the lock. Waiting on an event is much more efficient when the thread spends time waiting on the lock. This efficiency during wait has a cost, however. In a spin lock, exiting the lock does not require an interlocked operation because only the thread that owns the lock has access to the isEntered memory. To exit a normal lock, however, it must wake up any threads waiting on the lock. To prevent a race where thread A starts waiting just after thread B checked for waiting threads, the wake-up check involves an interlocked operation. Thus normal locks have an interlocked operation on entry and exit, and spin locks only have this overhead on entry, making them roughly twice as efficient.
Unfortunately, this simple spin lock has some deficiencies. On true multiprocessor machines it is better to busy-wait rather than force a context switch with Sleep(0). Busy-waits should be done through something like System.Threading.SpinWait so that hyperthreaded processors are told that no useful work is being done and another logical CPU can use the hardware. If the code is being run in an environment where a host might need to reliably kill runaway threads (like the .NET runtime when used by SQL Server), it becomes tricky to insure that no matter where a ThreadAbort happens, the lock will be released (see Stephen Toub's article on reliability in .NET in this issue). It is also useful in the .NET Framework for the lock to implement the IDisposable interface, which allows constructs like the C# using declaration to work. Finally, the locks should support debugging deadlocks. Making a good spin lock is not trivial, but only has to be done once.
One advantage spin locks have over other low-lock techniques is that they are true locks (they provide mutual exclusion), which means you can get improved performance without violating the locking protocol. They should not, however, be used for locks that could be held for any length of time since they are inefficient at waiting. They should be used only sparingly. In situations where technique 1 can be used to eliminate read locks, spin locks can be used for the update operations. This leads to a design where there would be only one interlocked operation per update and no interlocked operations on reads, which is ideal. For more information on interlocked operations and spin locks, see Jeffrey Richter's Concurrent Affairs column in this issue.
Technique 3: Direct Interlocked Updates
When it is applicable, the performance of combining spin locks and eliminating read locks is really hard to beat. A common technique that matches it, however, is the method of using interlocked operations directly. Instead of using the CompareExchange operation to enter a lock, you use it to update the data structure. Using this technique in the LinkedList example would mean changing the Push method as follows:
public void Push(int elem) {
ListNode newNode = new ListNode();
newNode.elem = elem;
ListNode origHead;
do {
origHead = head;
newNode.next = origHead;
} while (CompareExchange<ListNode>(
ref head, newNode, origHead) != origHead);
}
The Push method now has no locks associated with it. Instead, it prepares the new node and uses CompareExchange to update the head field. If another thread updated the head field in the meantime, the CompareExchange fails, and the code simply tries again. Under most circumstances, the loop is only executed once.
Because the CompareExchange technique does not use locks at all, this technique can only be used in cases where it is already possible to eliminate all read locks. This means every update operation must only modify a single location at most. However, unlike technique 1, which uses write locks to freeze all memory on updates, the CompareExchange technique only ensures that the one location being updated is stable between the time it was read for setup and the time it is updated. So CompareExchange can only be used if all update operations read only the one location being updated. This is true for the Push operation. However, take a look the following attempt to use CompareExchange in order to implement the Pop method:
public void Pop() {
ListNode newHead, origHead;
do { // This does not work if we allow inserts in the list
origHead = head;
newHead = origHead.next;
} while (CompareExchange<ListNode>(
ref head, newHead, origHead) != origHead);
}
This happens to work (barely) in the implementation as given; but it would be incorrect if there was an Insert method that allowed nodes to be added in the middle of the list. The problem is subtle. Unlike Push, Pop reads two locations from the data structure: the head field, and the next field of the first LinkedList node. Without an Insert operation, all fields in ListNodes are read-only after publication, so the read of the next field does not count as thread-shared read/write memory. However, if I add an Insert method, the next field is no longer read-only and Pop is broken.
Consider a scenario where thread A has just executed ListNode newHead = origHead.next in the Pop method and was then preempted by thread B. Thread B inserts a node just after the first node in the list (thus updating the next field). Thread A then resumes execution, and the CompareExchange completes successfully (because the head field has not changed). Because of the race, the state of the list after thread A completes loses the element X that thread B inserted. Thus a simple implementation of linked list using interlocked operations can add nodes to the list, but does not remove them correctly if the API is sufficiently flexible.
The simplest way of fixing the problem is to not use a raw CompareExchange to implement ListNode and to use a spin lock instead. The spin lock and CompareExchange techniques each have only one CompareExchange operation per update, and so in that respect they have equivalent performance.
CompareExchange does have a few significant advantages over spin locks. There is a slight space advantage to using CompareExchange since the word of memory used to represent the lock is not needed. A more important advantage is that it is impossible to leave the lock in the locked state when an operation fails or the thread is killed. Despite these relatively small advantages, there are a number of disadvantages. First and foremost, CompareExchange can only be used in a narrow set of circumstances, and it is very easy to use this technique when it is not applicable (for example, when calling Pop). In addition, because there is no lock object, locks cannot be held, which means it is impossible to stabilize two or more such data structures during an update. Because of these disadvantages, this technique is not as useful as the first two.
Technique 4: Lazy Initialization
The final low-lock technique is the most extreme. It has no interlocked operations at all. While this is the most efficient, it can only be used in a very narrow set of circumstances. Eliminating locks on reads requires that all updates change one memory location at most. To use a raw interlocked operation on update operations additionally requires that the update depends only on the previous value of the updated location. When eliminating locks completely, the update can't even expect this one location to remain stable. The only common situation where such a weak guarantee is actually useful is lazy initialization.
Consider first an example of a lazy initialized class that only uses the first technique to remove read locks as shown in Figure 7. In this code, GetValue always returns the value of the LazyInitClass constructor, but it also caches the result in the myValue variable and uses that for all future calls. It does not follow the locking protocol because a read/write thread-shared variable (myValue) is being accessed outside of a lock. It does follow the restrictions necessary to eliminate read locks because there is only one update operation (the body of the inner if statement), and that operation only modifies a single thread-shared memory location.
Figure 7 Double-Check Locking
public class LazyInitClass {
private static LazyInitClass myValue = null;
private static Object locker = new Object();
public static LazyInitClass GetValue() {
if (myValue == null) {
lock(locker) {
if (myValue == null) {
myValue = new LazyInitClass();
}
}
}
return myValue;
}
};
Like all techniques that remove read locks, the code in Figure 7 relies on strong write ordering. For example, this code would be incorrect in the ECMA memory model unless myValue was made volatile because the writes that initialize the LazyInitClass instance might be delayed until after the write to myValue, allowing the client of GetValue to read the uninitialized state. In the .NET Framework 2.0 model, the code works without volatile declarations.
The other requirements for removing read locks place further restrictions on what can be done in other methods of LazyInitClass. For example, if the fields of LazyInitClass are updated after publication by GetValue, each memory modification must move the class from one consistent state to another and readers must be able to handle arbitrary reordering of these updates. Typically, LazyInitClass is read-only which satisfies this requirement.
This pattern is often called double-check locking because the update operation (the body of the if statement) ends up revalidating the null check that was just made. This check is necessary because an update can happen between the first check and the time the lock was taken.
Notice that dropping the locks on reads captures almost all the possible performance gains. The path that takes the lock only happens once in the entire program run, so it is of little consequence. Moreover, this update lock is valuable in the case where two threads simultaneously find that myValue is uninitialized. The lock ensures that one thread will wait for the other, and thus the LazyInitClass constructor will be called exactly once.
While there is no strong performance reason to do so, the code is often simplified by removing the lock as follows:
public class LazyInitClass {
private static LazyInitClass myValue = null;
public static LazyInitClass GetValue() {
if (myValue == null)
myValue = new LazyInitClass();
return myValue;
}
};
In this case, notice that the body of the if statement does not read any thread-shared state at all. Because of this, the update can tolerate not having any locks at all. This will, however, introduce the race where two threads each notice myValue is null, each constructs a LazyInitClass, and each updates myValue with the constructed instance. This means myValue may have more than one value over time. However, it will always point at memory that was initialized the same way. As long as the LazyInitClass constructor can be called multiple times, and pointer equality is not used on the value returned from GetValue, the code just shown is likely to work as expected. Because of this race, however, the code also assumes garbage collection will clean up the instances of LazyInitClass that were orphaned when myValue was overwritten by another thread. The logic behind this code is pretty subtle, but it does work in the proper environment.
There is another variant of LazyInitClass that has even more subtleties. Again, start with the variation that only tries to remove read locks (see the code in Figure 8). This code is very similar to the first example, except that instead of a pointer, a Boolean variable is used to indicate whether the value is present. Already this code is suspect because the update operation is modifying two memory locations. This violates a requirement for eliminating read locks. However, because myValue is never read by any thread if myValueInit is zero, effectively myValue is not thread-shared at the time of the update (just like the ListNode fields in the Push method). Thus only one thread-shared location is modified, as required by the technique.
Figure 8 Using a Boolean to Indicate Initialization
public class LazyInitClass2 {
private static bool myValueInit = false;
private static int myValue;
private static Object locker = new Object();
public static int GetValue() {
if (!myValueInit) {
lock(locker) {
myValue = ComputeMyInt();
myValueInit = true;
}
}
return myValue;
}
};
While there is no compelling performance reason to do so, locks are often removed to yield the following code:
public class LazyInitClass2 {
private static bool myValueInit = false;
private static int myValue;
public static int GetValue() {
if (!myValueInit) {
myValue = ComputeMyInt();
myValueInit = true;
}
return myValue;
}
};
Unlike the first example, multiple memory locations are involved, which make analyzing its correctness much more subtle. Clearly, the strong write ordering of the x86 or .NET Framework 2.0 models is needed to make sure myValueInit is set after myValue. However, in the .NET model, reads can be reordered, which means the compiler could eagerly try to register myValue, effectively transforming the code into the following:
public class MorphedLazyInit2 {
private static bool myValueInit = false;
private static int myValue;
public static int GetValue() {
int temp = myValue;
if (!myValueInit) {
myValue = temp = computeMyInt();
myValueInit = true;
}
return temp;
}
};
This code has the same sequential logic as the original, but will break in a multithreaded environment if thread A loads temp just before being preempted by thread B, which sets myValue and myValueInit. As a result, thread A will return the uninitialized myValue, which is wrong. This example is specifically what motivated rule number 5 in the .NET Framework 2.0 memory model. With this rule, the morph just shown is illegal because the read of myValue was moved before a write to myValue. LazyInit2 will work correctly for the x86 and .NET Framework 2.0 models, but not the ECMA memory model unless myValueInit is declared volatile.
A Final Word of Warning
As can be seen from the examples of low-lock coding, some techniques work in some memory models but not others. Moreover, I am only guessing at the x86 memory model from observed behavior on existing processors. Thus low-lock techniques are also fragile because hardware and compilers can get more aggressive over time.
Here are some strategies to minimize the impact of this fragility on your code. First, whenever possible, avoid low-lock techniques. Second, if you do use low-lock techniques, create no-op methods like LockFreeEnter and LockFreeExit, which indicate the places where you have omitted locks. These will mark code that needs careful review, or must be updated if the memory model changes. Finally, assume the weakest memory model possible, using volatile declarations instead of relying on implicit guarantees.
Conclusion
Programs can be very subtle in the absence of locks. Programmers must be aware of the large number of ways reads and writes from different threads can interleave. And because of compiler and memory system optimization, it is possible for reads and writes to appear to move with respect to one another. Exactly how reads and writes can move around is specified by the memory model, and this must be taken into account when doing analysis.
I also looked at a number of techniques for avoiding locking overhead. The first, and by far the most important, technique eliminates locks on reads. The second technique builds on the first in a trivial way by using spin locks instead of normal locks for the write accesses. The third technique also builds on the first technique but removes the locks on writes altogether by using CompareExchange instructions to directly update the data structures. Finally, the last technique builds on the first technique and takes advantage of the fact that lazy initialization has unique robustness to concurrent updates to remove all interlocked operations.
Hopefully, all of this leads you to the conclusion that locks are a multithreading programmer's best friend. When the locking protocol is methodically followed, code is only accessing memory that is frozen by locks, and thus acts like it would in a sequential program. Memory model is irrelevant as all memory models guarantee this behavior. Once code strays from the locking protocol, however, reasoning about the program gets significantly more complex. The best advice is to avoid low-lock techniques when you can. When you can't, stick to tried and true idioms that have had a great deal of careful review.
Vance Morrison is the compiler architect for the .NET runtime at Microsoft, where he has been involved in the design of the .NET runtime since its inception. He drove the design for the .NET Intermediate Language (IL) and was lead for the just-in-time (JIT) compiler team.