Using Spark on Azure - Part 1
The world of data is one that is evolving quite rapidly, over the last years many new technologies have seen the light like Hadoop, Hive, Pig and many many more. One project that has gotten quite some attention lately is Spark which is described as follows: "Spark is a fast and general engine for large-scale data processing." Of course there are many projects in this particular area but Spark is gaining a lot of traction with its high performance in-memory handling. Spark also stands out by delivering not only an engine for data processing but a full platform offering Spark SQL, Spark Streaming, ML Lib (Machine Learning) and GraphX (a graph DB).
As Microsoft we have a history of embracing Big Data technologies on our Azure platform. We offer templates in our IAAS platform for HortonWorks, Cloudera and MapR among other Big Data Services. We also offer HDInsight, our 100% Apache Hadoop-based service in the cloud. By using HDInsight you are up and running in minutes with your own Big Data cluster, these clusters can come in different types such as Hadoop (HortonWorks), HBase, Storm and more recently Spark. If you want to read more in detail about this please refer to https://azure.microsoft.com/en-us/blog/interactive-analytics-on-big-data-with-the-release-of-spark-for-azure-hdinsight/.
If you want to learn how easy it is to setup a Spark cluster on Azure please follow the instructions here: https://azure.microsoft.com/en-us/documentation/articles/hdinsight-apache-spark-zeppelin-notebook-jupyter-spark-sql/
We will go through a practical example on how you can take an input file and process it using Spark, for this I will call in the help of someone with a lot of experience in Spark (Nathan Bijnens - @nathan_gs).
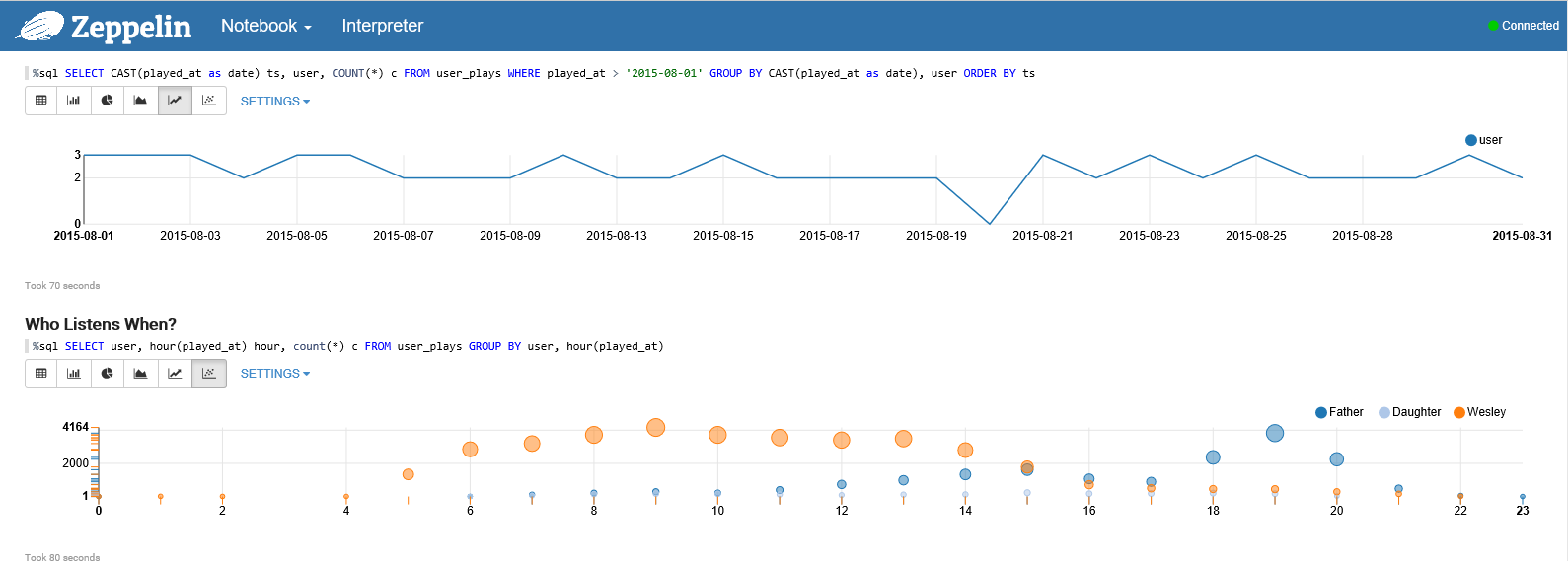
My previous post (I know it has been way to long since I blogged :-)) was about using Last.FM data to see if my father had influenced me. As I am a father myself I figured I should now see how I am influencing my daughter, so I created her an account on Last.FM too. The goal of this post is to show how easy it is to work with Spark on Azure, we are not trying to prove the performance of Spark since there are more than enough benchmarks done. Because we want to work with a raw file on Spark I have written an Azure WebJob that reads the Last.FM API every night and outputs this to an Azure Storage Account (in JSON). This will be the starting point for our journey from raw file to Power BI Dashboard.
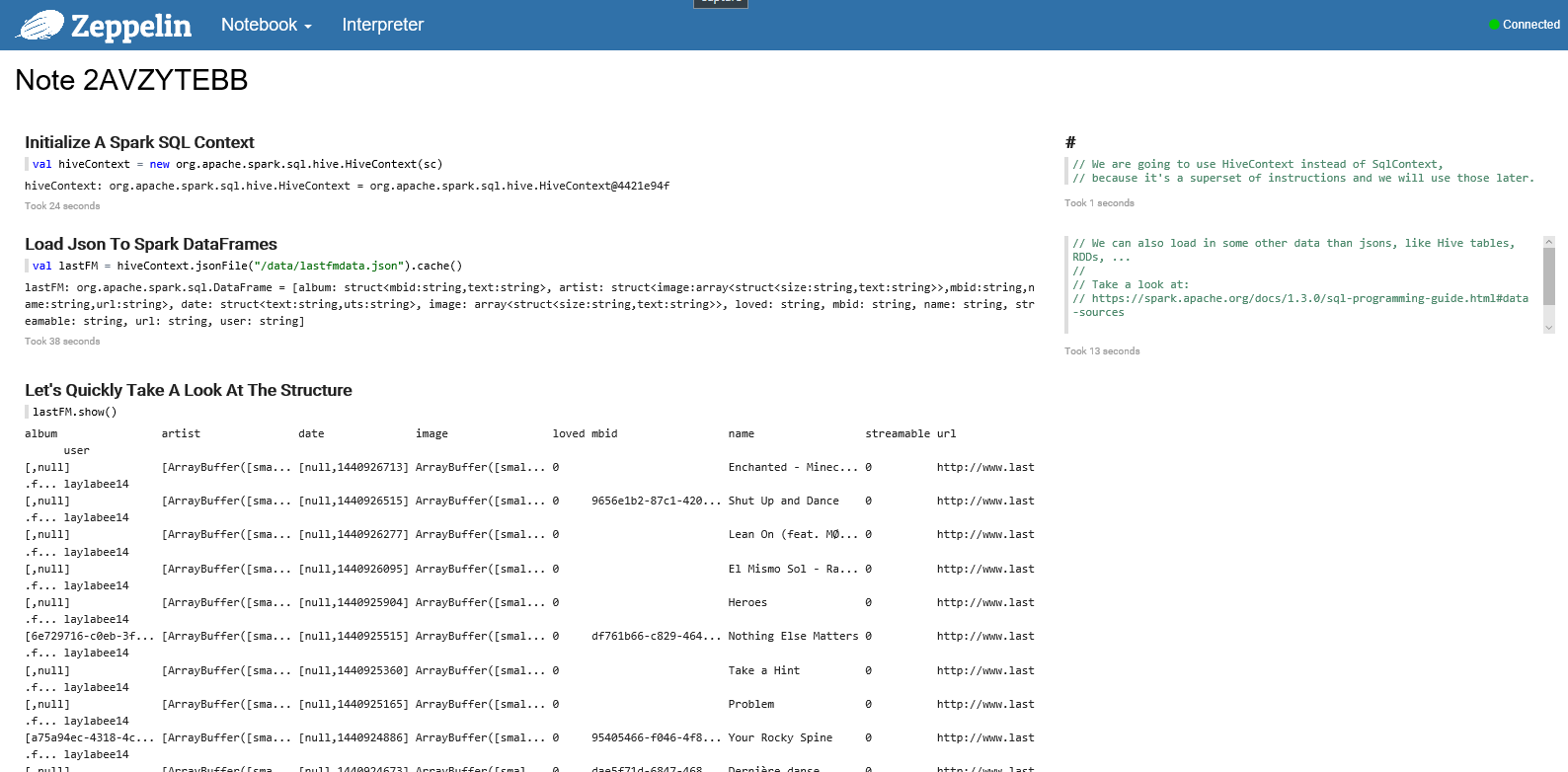
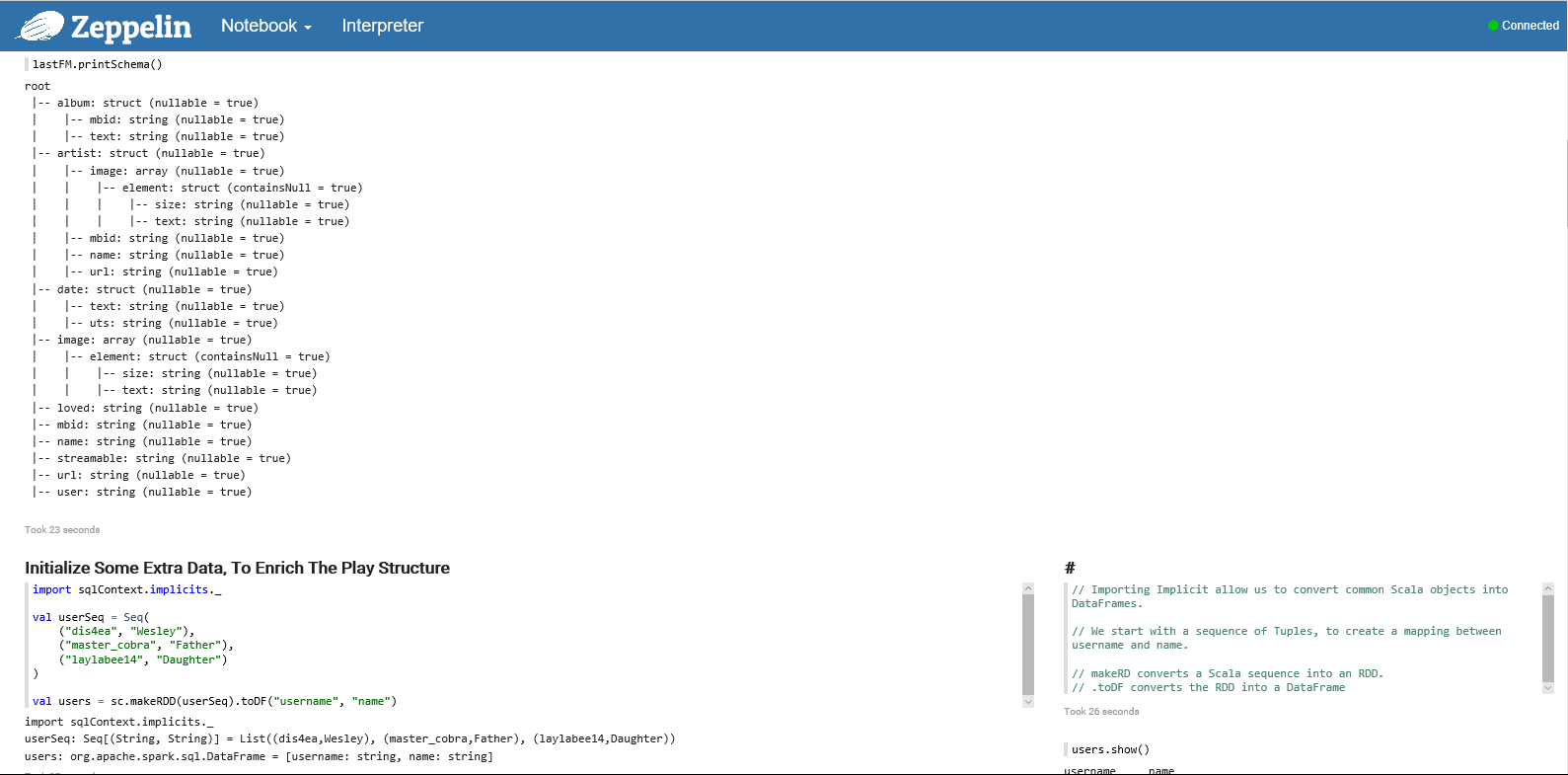
In part 1 we will see how you can take this JSON file and prepare it to be used in Power BI (as a Hive table). Attached some screenshots of the Zeppelin Notebook, if you want some of the source code you can find it on my OneDrive @ https://onedrive.live.com/redir?resid=F8448F26F719FCAC!192419&authkey=!AB4ZLro6lU-ysos&ithint=file%2ctxt)