Distributed Availability Groups extended
SQL Server 2016 supports distributed availability groups (AG) as additional HA feature of the engine. Today we want to show how this feature can be used to transfer near-real-time productive data around the globe.
Based on Jürgens Blog about SQL Server 2016 Distributed Availability Groups we set up a Primary AG with the SAP Database (e.g. PRD) as the only database. Furthermore did we setup two additional servers with SQL Server 2016 as a single node cluster (just for demonstration purposes, a two node cluster would work as well). The one cluster will act as a distribution server, that takes the data from the productive system and distributes it to the global locations, our second one-node cluster (target). This picture illustrates how the complete setup will look like:
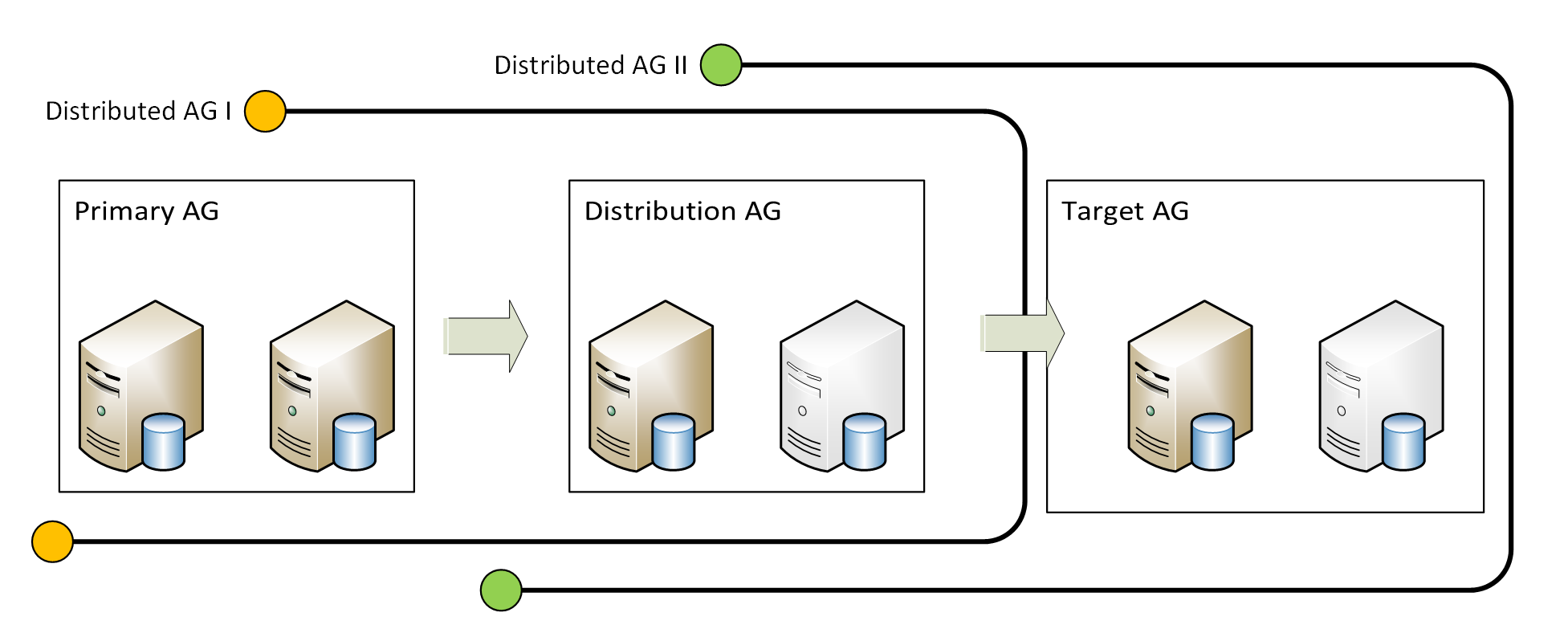
The availability mode is synchronous in the Primary AG and between the Primary and the Distribution AG. From there the data is send to the far-far-away location (Target AG) in the asynchronous mode. The distribution system is either located in the same or a very close data center as the primary AG to be able to use the synchronous mode. With this setup we get an synchronous like replication to the target, even if the complete primary system goes up in flames, the distribution system will still be able to sync the data to the Target AG.
We have three separate AGs (Primary, Distribution, Target) which are connected with two distributed AGs, the first over the Primary and the Distribution AG and the second over the Distribution and the target AG. With this kind of setup one can replicate multiple system over one distributor to the target AG like this picture is showing:
How do we set it up ? As a prerequisite we have the PRD database from the PRIMARY server restored on all other servers (SECONDARY, DISTRIBUTION, TARGET) in recover mode, so that we can easily setup the AGs. As the SQL Server Management Studio 17 is not supporting distributed AGs in all details, we have to set it up with a script. On a high level the script executes these steps:
- connect to the PRIMARY server, create and configure an AlwaysOn endpoint (AO_Endpoint)
- connect to the SECONDARY server, create and configure an AlwaysOn endpoint (AO_Endpoint)
- connect to the DISTRIBUTION server, create and configure an AlwaysOn endpoint (AO_Endpoint)
- connect to the TARGET server, create and configure an AlwaysOn endpoint (AO_Endpoint)
- connect to the DISTRIBUTION server, create and configure a one-node AG (AG_PRD_DISTRIBUTOR) with a TCP/IP listener
- connect to the TARGET server, create and configure a one-node AG (AG_PRD_TARGET) with a TCP/IP listener
- connect to the PRIMARY server, create and configure a two-node AG (AG_PRD_MAIN) with a TCP/IP listener
- still on the PRIMARY create a distributed AG (DAG_PRD_MAIN) over the main AG (AG_PRD_MAIN) and the AG of the DISTRIBUTION server (AG_PRD_DISTRIBUTOR)
- connect to the DISTRIBUTION server and join the distributed AG (DAG_PRD_MAIN) from the PRIMARY
- then create a distributed AG (DAG_DISTRIBUTOR_TARGET) over the AG of the TARGET server (AG_PRD_TARGET) and the AG of the DISTRIBUTION server (AG_PRD_DISTRIBUTOR)
- connect to the TARGET server and join the distributed AG (DAG_DISTRIBUTOR_TARGET) with the DISTRIBUTION server
- change the status of the DB to readable on the target
You will find the full script at the end as an attachment.
To test the scenario we started the SGEN transaction on the underlying PRD SAP System that is connected to the Primary AG. We used just one application server with 20 Dialog work processes to generate all the report loads of the system. SGEN used up to 15 work processes at the same time:
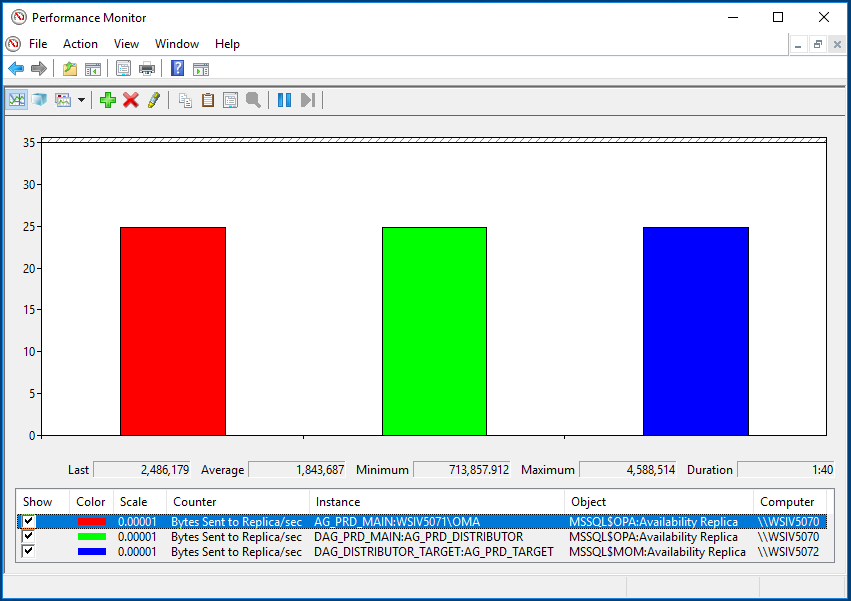
Measuring the throughput that is flowing through the DAGs we used the Windows Performance Monitor tool on one of the systems. One can see that the primary is sending an average of 1.8 MB/Sec to the Secondary (red block). The first DAG to the distributor (green) and the data flow to the target (blue) are showing nearly the same value, so there is throughput penalty by using distributed AGs in a system.
If you want to measure the overall travel time of a change, you can setup an easy test. Prerequisite for this is, that the target database is setup as a readable secondary, so that we can connect against the DB. On the target system we are start the SQL Server Management Studio, open a new query and run the following script:
USE PRD
WHILE NOT EXISTS(SELECT name FROM sys.objects WHERE name = N'DAGTEST')
WAITFOR DELAY N'00:00:01'
PRINT SYSDATETIME()
This script checks if a table named DAGTEST exists in the PRD database and waits a second if it can't be found. Once it can be found it prints out the current time. On the primary AG we now open a query that creates the table:
CREATE TABLE DAGTEST (f1 INT)
PRINT SYSDATETIME()
-- Later we can drop the table again
-- DROP TABLE DAGTEST
This script just creates the table DAGTEST and then prints out the current time. Once the table is created the changes will be transferred over the distributor to the target. On the target the still running script detects the freshly created table and prints out the current time as well. By comparing the time from the primary script and the target script we can determine to overall travel time of changes through the system.
Full Script to setup the DAGs:
DAGScript