Azure Data Factory - using a Stored Procedure as a destination
Azure Data Factory allows data to move from a multitude of sources to a multitude of destinations. A common usage case is to take on premise data and place it into a cloud database such as Azure SQL Database.
Often this is done as a two-stage operation. Firstly, load the data into a data lake or database table then perform a transformation operation on that data.
Today we will look at performing this in one atomic action. This allows a smaller, simpler and faster data move and transformation pipeline. However, this does come at the cost that the data lineage is held in an on premise system and not in the cloud architecture.
To reduce a data move and transformation to one operation we will use a stored procedure instead of a table. This way data can be transformed as it loads.
In this simple example we are using an on premise SQL database as the source of the data. We have already set up a Data Management Gateway to facilitate the communication between the on premise resource and Azure. Now we need to create a simple table as the data source and populate it with some data.
/*Run on the On Prem data source*/
CREATE TABLE TabOnPremSQLSource
( ID INT
, String VARCHAR(250)
)
GO
INSERT INTO TabOnPremSQLSource VALUES (1,'a')
INSERT INTO TabOnPremSQLSource VALUES (2,'b')
GO
SELECT * FROM TabOnPremSQLSource
Once this has been run we need to create a stored procedure at the destination to perform transformations. In this example, we are taking the data, performing an aggregation and storing that aggregation.
/*Run on the Azure SQL Database*/
/*A table to hold the transformed data*/
CREATE TABLE tabCountFromOnPremSQL
(ID INT,
TimeUploaded DateTime2 DEFAULT(GetDate()))
GO
/*A table type that will be used by the stored procedure to receive the data*/
CREATE TYPE tabTypeUploadData AS TABLE
( ID INT
, String VARCHAR(250)
)
GO
/*Stored proc to receive the data, transform and place into a table*/
CREATE PROCEDURE spDFTableProc (@inDataFromOnprem [dbo].tabTypeUploadData READONLY) AS
DECLARE @ID INT
SELECT @ID = COUNT(*) FROM @inDataFromOnprem
INSERT INTO tabCountFromOnPremSQL (ID) VALUES (@ID)
GO
SELECT * FROM tabCountFromOnPremSQL
Now we have the source and destination set up we can create the data factory
Here is a diagram of the finished pipeline
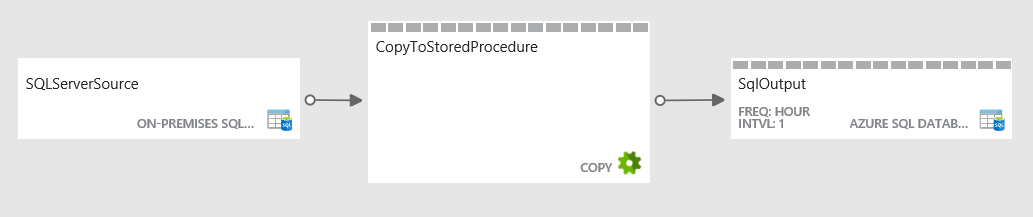
In creating the data factory components first are the linked services
Here we are setting up the on premise SQL Server lined service (data source)
{
"name": "SqlServerOnPrem",
"properties": {
"description": "",
"hubName": "dfral01_hub",
"type": "OnPremisesSqlServer",
"typeProperties": {
"connectionString": "Data Source=onpremSQLBox\\SQL2016;Initial Catalog=SQL2016;Integrated Security=False;User ID=SQL;Password=**********",
"gatewayName": "DataManagementGateway",
"userName": "SQL",
"password": "**********"
}
}
}
Then the linked service for the destination (Azure SQL Database)
{
"name": "AzureSqlLinkedService",
"properties": {
"description": "",
"hubName": "dfral01_hub",
"type": "AzureSqlDatabase",
"typeProperties": {
"connectionString": "Data Source=tcp:AZURESQLSERVERNAME.database.windows.net,1433;Initial Catalog=SQLTest;Integrated Security=False;User ID=Rob@AZURESQLSERVERNAME;Password=**********;Connect Timeout=30;Encrypt=True"
}
}
}
Now we define the dataset for the source data
{
"name": "SQLServerSource",
"properties": {
"published": false,
"type": "SqlServerTable",
"linkedServiceName": "SqlServerOnPrem",
"typeProperties": {
"tableName": "TabOnPremSQLSource"
},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true,
"policy": {}
}
}
And the dataset for the destination. Note the table name is the table variable in the destination stored procedure
{
"name": "SqlOutput",
"properties": {
"published": false,
"type": "AzureSqlTable",
"linkedServiceName": "AzureSQLLinkedService",
"typeProperties": {
"tableName": "inDataFromOnprem"
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Finally we construct the pipeline. We have to define the stored procedure as well as the table type it is expecting
{
"name": "CallStroedProc",
"properties": {
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "SqlSource"
},
"sink": {
"type": "SqlSink",
"sqlWriterStoredProcedureName": "spDFTableProc",
"sqlWriterTableType": "tabTypeUploadData",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
}
},
"inputs": [
{
"name": "SQLServerSource"
}
],
"outputs": [
{
"name": "SqlOutput"
}
],
"policy": {
"timeout": "02:00:00",
"concurrency": 1,
"executionPriorityOrder": "NewestFirst",
"style": "StartOfInterval",
"longRetry": 0,
"longRetryInterval": "00:00:00"
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"name": "CopyToStoredProcedure"
}
],
"start": "2017-03-31T00:09:00.273Z",
"end": "2017-04-02T03:00:00Z",
"isPaused": false,
"hubName": "dfral01_hub",
"pipelineMode": "Scheduled"
}
}
We would now need to consider setting up slices and only moving the data from the source system that corresponded to the relevant slice.