Server Clustering and Storage – Hyper Converged BRK3324
Hello all,
Microsoft Ignite was held in Orlando, Florida from September 25th to the 29th last year. If, like me, you were unable to attend, you will probably, like me, be digging through all the sessions to get all the latest news and information. Like me, your time is probably limited and since the Ignite session videos are anywhere from forty-five minutes to an hour and a half, the number of sessions one can get through are probably few, if any.
I will be putting together a series of posts that summarize the videos and presentations that I hope will help you get the most out of the sessions without having to watch the entire video. If you have the time, I definitely recommend watching the entire video, as every session has lots of great information. I'll be calling out key times for when you will want to catch the speaker's exact wording, or if there is something extra special I want to draw your attention to.
For the first installment, we are going to cover session BRK3324 – Server Clustering and Storage – Hyper Converged. Please leave me comments, questions, and any session you would like to see covered!
This session is presented by Elden Christensen and Mallikarjun Chadalapaka, Program Managers from the High Availability Storage team from the Windows Division of Microsoft.

Hyper converged infrastructure really builds on Storage Spaces Direct (abbreviated as S2D), new technology in Server 2016 that allows users to utilize local attached drives to create highly available, highly scalable software-defined storage at a fraction of the cost of traditional SAN or NAS arrays. As my customer starts rolling out Server 2016, S2D is going to be one of my talking points as I really believe it's going to be big going forward.
2:13 - Stretch clusters are new in Server 2016,and use storage replica to bring an end to end solution around stretch clusters for high availability (HA) and disaster recovery (DR). The SQL PFE that I work with at my customer is hoping to implement stretch clusters with SQL 2016 as we implement Server 2016. About 90% of the clusters that I currently deal with are SQL, so we're really excited about the prospect of implementing stretch clusters.
4:30 – With an S2D cluster, you can create a Scale-out File Server and turn your hardware into a NAS (Network Attached Storage) device!

With Server 2016, you can make a share with NVMe (NVMe is a communications interface/protocol developed specially for SSDs by a consortium of vendors including Intel, Samsung, Sandisk, Dell, and Seagate) on an S2D cluster. This is exciting technology, providing ridiculously fast speeds for access to shares and allows us to get the best performance out of our SSD drives now.
With Storage Spaces Direct, we can have millions of IOPS by creating an NVMe fabric.
And now you can put SQL on top of S2D – drives appear as Cluster Shared Volumes (CSV) -- nothing special or different -- so any current experience with CSV volumes still applies and no new training is required. Again, we're hoping to roll out S2D and stretch clusters for our SQL environment at my customer, and since the drives will appear as CSVs, our Database Admins will likely not notice any difference at all.
S2D can also be used inside a VM. Since there is no concept of shared storage, S2D can take virtual drives - VMs, Azure, AWS, etc. and allow them to be used for an S2D deployment. This is also particularly exciting for me because my customer is a VMWare shop, and if we can enable S2D using their existing virtual infrastructure, I think that'll be an easy jumping off point to start discussions to migrate to Hyper-V, or at least to enable the features in Azure.
 7:22 - The next features discussed in the presentation are available in the Insiders build, which is easy to sign up for and download. If you have the development space for it, I highly recommend signing up for it and testing out all the goodness coming down the road.
7:22 - The next features discussed in the presentation are available in the Insiders build, which is easy to sign up for and download. If you have the development space for it, I highly recommend signing up for it and testing out all the goodness coming down the road.
 Data deduplication, which involves finding and removing duplication within data without compromising its fidelity or integrity, is now supported with ReFS (Resilient File System), which could increase storage efficiency upwards of 95%.
Data deduplication, which involves finding and removing duplication within data without compromising its fidelity or integrity, is now supported with ReFS (Resilient File System), which could increase storage efficiency upwards of 95%.
8:55 – Demo for DeDup of drives with the new Honolulu interface. Honolulu is an exciting new management interface for your Windows servers. If you haven't seen it yet, you should check it out!
11:13 - Another demo, this time of hyper converged cluster manager, again using the new Honolulu interface. I really think hyper converged infrastructure is where the future is at, so be sure to check out the demo.
17:35 – The Health Service is a new feature in Windows Server 2016 that improves the day-to-day monitoring and operational experience for clusters running Storage Spaces Direct. It can detect when drives fail, and it will then automatically remove them or automatically add drives back when they've been replaced and will then add the drives to the cluster they belong to. This is such a great feature as it really removes a lot of the more mundane tasks of managing disks.
Scoped spaces can be resilient to losing two nodes per data set because of the way the volumes are written.

There is self-healing logic in S2D and clusters, and ways to validate improvements for S2D requirements. This is going to make life easier for systems admins!
23:28 – MSDTC (Microsoft Distributed Transaction Coordinator, which tracks all parts of the transactions process, even over multiple resource managers on multiple computers),is now supported on S2D.

All clusters use SMB, and now we can encrypt SMB Communication. BitLocker is supported on 2016 S2D for encryption of data at rest and encrypted SMB for data in motion. This is great for everyone who is security conscious, and these days, that really should be everyone!
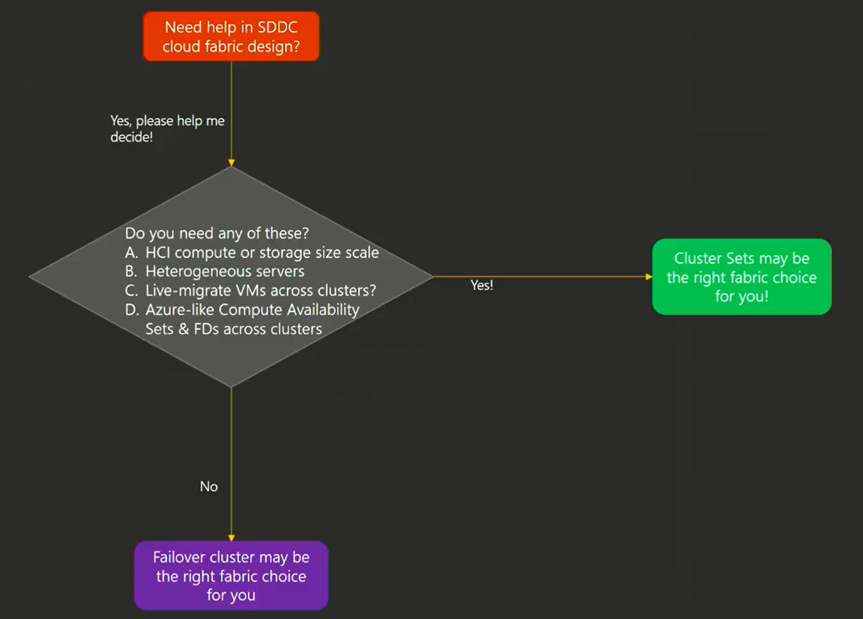
26:14 - Cluster Sets are loosely coupled group of clusters: computer, storage, or hyper-converged.

Software Designed Data Center (SDDC) can now scale out to thousands of nodes, allowing for a large-scale set and limiting the software fault boundary. Like I said earlier, most of the clusters I deal with are SQL clusters, and this customer has many different clusters ranging from 2 nodes to 8 nodes and running Server 2008 R2 and Server 2012 R2. By adding in new 2016 servers, we can start using cluster sets for easier management, and be much less concerned over a cluster running low on resources.
29:30 - Cluster sets can be heterogenous between the clusters but should still be as homogenous as possible inside each cluster. It's easy to add just a compute node to the cluster (or just a storage node), take down nodes, and to patch nodes with zero downtime. by migrating workloads amongst the cluster set. We're really looking forward to implementing rotating upgrades and zero-downtime patching.
33:00 solution view
 34:28 Logical fault domains – use Azure-like semantics allowing for reuse of existing Azure skills. As more and more companies are adopting a hybrid infrastructure, we want to make sure as many of our standard nomenclatures and skills apply to the new technologies as well as technology currently in our environment. Logical fault domains is one of the ways we'll be doing that.
34:28 Logical fault domains – use Azure-like semantics allowing for reuse of existing Azure skills. As more and more companies are adopting a hybrid infrastructure, we want to make sure as many of our standard nomenclatures and skills apply to the new technologies as well as technology currently in our environment. Logical fault domains is one of the ways we'll be doing that.
35:25 Demo of a management cluster with three worker clusters using PowerShell and Failover Cluster Manager.
39:55 When to deploy clusters vs cluster sets? For us, I'm really pushing for the Hyper Converged Infrastructure and the combination of all the heterogenous servers should help push my customer to see the benefits of using Cluster Sets.
 43:25 - High Availability with Enhanced VM Start Ordering is – This new feature allows apps to span over several VM's and allows you to set a delay in restarting VMs. For example, start VM1, with a configured delay, and then start VM2. This is not just a simple timer anymore, it can trigger off OS heartbeat, or other services. The triggers can also be set on apps that are throwing events in an event log. Since my customer is currently a VMWare shop, the Enhanced VM Start Ordering isn't on my personal roadmap yet, but again it might help sway them to make the move to Hyper-V.
43:25 - High Availability with Enhanced VM Start Ordering is – This new feature allows apps to span over several VM's and allows you to set a delay in restarting VMs. For example, start VM1, with a configured delay, and then start VM2. This is not just a simple timer anymore, it can trigger off OS heartbeat, or other services. The triggers can also be set on apps that are throwing events in an event log. Since my customer is currently a VMWare shop, the Enhanced VM Start Ordering isn't on my personal roadmap yet, but again it might help sway them to make the move to Hyper-V.
46:09 - Azure Enlightened Clusters

Clusters can now detect when they are running on Azure (or any public cloud). This is an incredibly helpful new ability for clusters. Being able to use Stretch Clusters to push part of the cluster to Azure and have the cluster know which VMs are in Azure is a huge benefit. The Enlightened Clusters can detect Azure maintenance events, which will help with troubleshooting cluster issues. With an Azure configure setup, there will be modified heartbeats with upped thresholds when dealing with Azure so resources don't fail over as fast due to network latency. For me, this is an easy way to get my customer to start moving workloads into Azure. Stretch a node or two up there and see how easy it is and what the performance is like, and then later start migrating more and more.
50:55 You can now move a cluster to another domain – this is still in the Insider preview! Sign up for the to check it out as this is big. I've had several customers who wanted, and in some cases needed, to set up a cluster without having it joined to a domain. Now you can dynamically change clusters from one domain to another, breaking AD dependencies In the future a cluster can be built in a lab environment then be removed from the lab domain, and finally be reestablished in production by running some PowerShell commands. However, clusters cannot be Azure Active Directory (AAD) joined at this time.

Q&A
58:20 - Q: Is a 2-node cluster supported with S2D?
A: Yes, and it supports a cloud witness (Azure blob) or file server witness. Also, you do not need nVME, it can be mixed with SSD, HDD, etc
59:20 – Q: Can I do stretch cluster sets for DR purposes?
A: From a design perspective, yes. However, it has not been approved yet and has only been tested for a single site.
59:56 – Q: Regarding VM start ordering - if SQL server is restarted, can they be set to then reboot the app and front end?
A: Yes, groupings of groups can be defined, and then polices can be set up inside of the groups. For example, servers can be set in tiers and to wait for three servers to be up in one tier before the next tier are started.
1:01:07 – Q: Will storage replica work across a WAN?
A: Absolutely, either synchronous and asynchronous replication both are both supported in a stretch cluster.
1:01:50 – Q: Are any of these features available in 1709, or just Insider build?
A: Just Insider build.
1:02:18 – Q: What's with 1709 and R2's?
A: Aligning server with client, SAC (Semi Annual Cadence) releases (every 6 months) are only supported for 18 months. There will also be LTSC (Long Term Service Chanel) releases (same as for the last 20 years)- supported for 5 + 5 years, and you can buy premium support afterwards. Server 2016 is LTSC, 1709 is a SAC release, and the branding is changed to just Windows Server MonthYear.
1:04:35 – Q: When will Azure templates for S2D be available?
A: 3-4 templates are available now, here's a blog discussing templates, clustering, and high-availability.
1:04:58 – Q: Are Windows cluster sets available with LTSC or just Insider build?
A: Windows cluster sets are only available with Insider build (not in 1709 either).
1:05:30 – Q: Can we set up a VM cluster and S2D with just 2 nodes?
A: Yes, you can deploy with just 2 nodes. Can you use existing servers? Maybe not. Not all vendors have S2D solutions and it is recommended to get one that does. You would want to use hardware that is validated. Have people used JBOD (Just a Bunch Of Disks) successfully? Yes. Would it be recommended? No.
1:07:34 – Q: Is there any way to manage durability of drives in an all flash cluster?
A: We have a blog discussing drive writes per day and endurance requirements with S2D. Is there a good mechanism? Not really, maybe PowerShell might work. Are SSD's reporting back to PowerShell? Maybe not, no real standard on that yet.
1:09:10 – Q: What kind of performance impact can be expected from enabling deduplication?
A: Depends on the workload being deduplicated. DeDup is done on rotation. ReFS done on rotation, data lands on caching device, then mirrored partition, then rotate data and dedup as data moves between tiers. For a flat design that runs on periodic basis (24hrs by default), that can be tuned as a scheduled task.
1:10:30 – Q: Is dedup supported for more than VDI and VHDX backup
A: Yes.
1:10:45 – Q: Are there any file size limitations?
A: Yes, there are volume and file size limitations. There is an article on it.
1:11:26 – Q: S2D has a limit is 1 PB for storage. Can cluster storage expand the limit?
A: If you want more storage, add another S2D cluster.
So that's my blog on Ignite sessions. What did you think? Leave a comment! Is there a session or technology you'd like me to review? Leave a comment! Like my font? Leave a comment!