WCF scales up slowly with bursts of work
A few customers have noticed an issue with WCF scaling up when handling a burst of requests. Fortunately, there is a very simple workaround for this problem that is covered in KB2538826 (thanks to David Lamb for the investigation and write up). The KB article provides a lot of good information about when this would apply to your application and what to do to fix it. In this post, I want to explore exactly what's happening.
The best part is that there is an easy way to reproduce the problem. To do this, create a new WCF service application with the .NET 4 framework:

Then trim the default service contract down to only the GetData method:
using System.ServiceModel;
[ServiceContract]
public interface IService1
{
[OperationContract]
string GetData(int value);
}
And fill out the GetData method in the service code:
using System;
using System.Threading;
public class Service1 : IService1
{
public string GetData(int value)
{
Thread.Sleep(TimeSpan.FromSeconds(2));
return string.Format("You entered: {0}", value);
}
}
The two second sleep is the most important part of this repro. We'll explore why after we create the client and observe the effects. But first, make sure to set the throttle in the web.config:
<configuration>
<system.web>
<compilation debug="true" targetFramework="4.0" />
</system.web>
<system.serviceModel>
<behaviors>
<serviceBehaviors>
<behavior>
<serviceMetadata httpGetEnabled="true"/>
<serviceDebug includeExceptionDetailInFaults="false"/>
<serviceThrottling maxConcurrentCalls="100"/>
</behavior>
</serviceBehaviors>
</behaviors>
<serviceHostingEnvironment multipleSiteBindingsEnabled="true" />
</system.serviceModel>
<system.webServer>
<modules runAllManagedModulesForAllRequests="true"/>
</system.webServer>
</configuration>
The Visual Studio web server would probably suffice, but I changed my web project to use IIS instead. This makes it more of a realistic situation. To do this go to the project properties, select the Web tab, and switch to IIS.

Be sure to hit the Create Virtual Directory button. In my case, I have SharePoint installed and it's taking up port 80, so I put the default web server on port 8080. Once this is done, build all and browse to the service to make sure it's working correctly.
To create the test client, add a new command prompt executable to the solution and add a service reference to Service1. Change the client code to the following:
using System;
using System.Threading;
using ServiceReference1;
class Program
{
private const int numThreads = 100;
private static CountdownEvent countdown;
private static ManualResetEvent mre = new ManualResetEvent(false);
static void Main(string[] args)
{
string s = null;
Console.WriteLine("Press enter to start test.");
while ((s = Console.ReadLine()) == string.Empty)
{
RunTest();
Console.WriteLine("Allow a few seconds for threads to die.");
Console.WriteLine("Press enter to run again.");
Console.WriteLine();
}
}
static void RunTest()
{
mre.Reset();
Console.WriteLine("Starting {0} threads.", numThreads);
countdown = new CountdownEvent(numThreads);
for (int i = 0; i < numThreads; i++)
{
Thread t = new Thread(ThreadProc);
t.Name = "Thread_" + i;
t.Start();
}
// Wait for all threads to signal.
countdown.Wait();
Console.Write("Press enter to release threads.");
Console.ReadLine();
Console.WriteLine("Releasing threads.");
DateTime startTime = DateTime.Now;
countdown = new CountdownEvent(numThreads);
// Release all the threads.
mre.Set();
// Wait for all the threads to finish.
countdown.Wait();
TimeSpan ts = DateTime.Now - startTime;
Console.WriteLine("Total time to run threads: {0}.{1:0}s.",
ts.Seconds, ts.Milliseconds / 100);
}
private static void ThreadProc()
{
Service1Client client = new Service1Client();
client.Open();
// Signal that this thread is ready.
countdown.Signal();
// Wait for all the other threads before making service call.
mre.WaitOne();
client.GetData(1337);
// Signal that this thread is finished.
countdown.Signal();
client.Close();
}
}
The code above uses a combination of a ManualResetEvent and a CountdownEvent to coordinate the calls to all happen at the same time. It then waits for all the calls to finish and determines how long it took. When I run this on a dual core machine, I get the following:
Press enter to start test.
Starting 100 threads.
Releasing threads.
Total time to run threads: 14.0s.
Allow a few seconds for threads to die.
Press enter to run again.
If each individual request only sleeps for 2 seconds, why would it take 100 simultaneous requests 14 seconds to complete? It should only take 2 seconds if they're all executing at the same time. To understand what's happening, let's look at the thread count in perfmon. First, open Administrative Tools -> Performance Monitor. In the tree view on the left, pick Monitoring Tools -> Performance Monitor. It should have the % Processor counter in there by default. We don't need that counter so select it in the bottom and press the delete key. Now click the add button to add a new counter:
In the Add Counters dialog, expand the Process node:

Under this locate the Thread Count counter and then find the w3wp instance and press the Add >> button.

If you don't see the w3wp instance, it is most likely because it wasn't running when you opened the Add Counters dialog. To correct this, close the dialog, ping the Service1.svc service, and then click the Add button again in perfmon.
Now you can run the test and you should see results similar to the following:
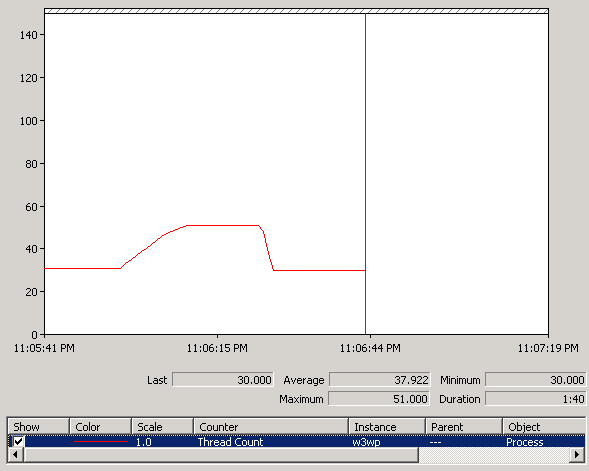
In this test, I had pinged the service to get the metadata to warm everything up. When the test ran, you can see it took several seconds to add another 21 threads. The reason these threads are added is because when WCF runs your service code, it uses a thread from the IO thread pool. Your service code is then expected to do some work that is either quick or CPU intensive or takes up a database connection. But in the case of the test, the Thread.Sleep means that no work is being done and the thread is being held. A real world scenario where this pattern could occur is if you have a WCF middle tier that has to make calls into lower layers and then return the results.
For the most part, server load is assumed to change slowly. This means you would have a fairly constant load and the thread pool manager would pick the appropriate size for the thread pool to keep the CPU load high but without too much context switching. However, in the case of a sudden burst of requests with long-running, non-CPU-intensive work like this, the thread pool adapts too slowly. You can see in the graph above that the number of threads drops back down to 30 after some time. The thread pool has recognized that a thread has not been used for 15 seconds and therefore kills it because it is not needed.
To understand the thread pool a bit more, you can profile this and see what's happening. To get a profile, go to the Performance Explorer, usually pinned on the left side in Visual Studio, and click the button to create a new performance session:

Right click on the new performance session and select properties. In the properties window change the profiling type to Concurrency and uncheck the "Collect resource contention data" option.

Before we start profiling, let's first go to the Tools->Options menu in Visual Studio. Under Debugging, enable the Microsoft public symbol server.

Also, turn off the Just My Code option under Performance Tools:

The next step is to make the test client the startup project. You may need to ping the Service1.svc service again to make sure the w3wp process is running. Now, attach to the w3wp process with the profiler. There is an attach button at the top of the performance explorer window or you can right click on the performance session and choose attach.

Give the profiler a few seconds to warmup and then hit ctrl+F5 to execute the test client. After the test client finishes a single run pause and detach the profiler from the w3wp process. You can also hit the "Stop profiling" option but it will kill the process.
After you've finished profiling, it will take some time to process the data. Once it's up, switch to the thread view. In the figure below, I've rearranged the threads to make it easier to see the relationships:

Blue represents sleep time. This matches what we expect to see, which is a lot of new threads all sleeping for 2 seconds. At the top of the sleeping threads is the gate thread. It checks every 500ms to see if the number of threads in the thread pool is appropriate to handle the outstanding work. If not, it creates a new thread. You can see in the beginning that it creates 2 threads and then 1 thread at a time in 500ms increments. This is why it takes 14 seconds to process all 100 requests. So why are there two threads that look like they're created at the same time? If you look more closely, that's actually not the case. Let's zoom in on that part:

Here again the highlighted thread is the gate thread. Before it finishes its 500ms sleep, a new thread is created to handle one of the WCF service calls which sleeps for 2 seconds. Then when the gate thread does its check, it realizes that there is a lot of work currently backed up and creates another new thread. On a dual core machine like this, the default minimum IO thread pool setting is 2: 1 per core. One of those threads is always taken up by WCF and functions as the timer thread. You can see that there are other threads created up top. This is most likely ASP.Net creating some worker threads to handle the incoming requests. You can see that they don't sleep because they're passing off work to WCF and getting ready to handle the next batch of work.
The most obvious thing to do then would be to increase the minimum number of IO threads. You can do this in two ways: use ThreadPool.SetMinThreads or use the <processModel> tag in the machine.config. Here is how to do the latter:
<system.web>
<!--<processModel autoConfig="true"/>-->
<processModel
autoConfig="false"
minIoThreads="101"
minWorkerThreads="2"
maxIoThreads="200"
maxWorkerThreads="40"
/>
Be sure to turn off the autoConfig setting or the other options will be ignored. If we run this test again, we get a much better result. Compare the previous snapshot of permon with this one:

And the resulting output of the run is:
Starting 100 threads.
Press enter to release threads.
Releasing threads.
Total time to run threads: 2.2s.
Allow a few seconds for threads to die.
Press enter to run again.
This is an excellent result. It is exactly what you would want to happen if a sudden burst of work comes in. But customers were saying that this wasn't happening for them. David Lamb told me that if you run this for a long time, like 2 hours, it would eventually stop quickly adding threads and behave as if the min IO threads was not set.
One of the things we can do is modify the test code to give enough time for the threads to have their 15 second timeout and just take out all the Console.ReadLine calls:
using System;
using System.Threading;
using ServiceReference1;
class Program
{
private const int numThreads = 100;
private static CountdownEvent countdown;
private static ManualResetEvent mre = new ManualResetEvent(false);
static void Main(string[] args)
{
while (true)
{
RunTest();
Thread.Sleep(TimeSpan.FromSeconds(25));
Console.WriteLine();
}
}
static void RunTest()
{
mre.Reset();
Console.WriteLine("Starting {0} threads.", numThreads);
countdown = new CountdownEvent(numThreads);
for (int i = 0; i < numThreads; i++)
{
Thread t = new Thread(ThreadProc);
t.Name = "Thread_" + i;
t.Start();
}
// Wait for all threads to signal.
countdown.Wait();
Console.WriteLine("Releasing threads.");
DateTime startTime = DateTime.Now;
countdown = new CountdownEvent(numThreads);
// Release all the threads.
mre.Set();
// Wait for all the threads to finish.
countdown.Wait();
TimeSpan ts = DateTime.Now - startTime;
Console.WriteLine("Total time to run threads: {0}.{1:0}s.",
ts.Seconds, ts.Milliseconds / 100);
}
private static void ThreadProc()
{
Service1Client client = new Service1Client();
client.Open();
// Signal that this thread is ready.
countdown.Signal();
// Wait for all the other threads before making service call.
mre.WaitOne();
client.GetData(1337);
// Signal that this thread is finished.
countdown.Signal();
client.Close();
}
}
Then just let it run for a couple hours and see what happens. Luckily, it doesn't take 2 hours and we can reproduce the weird behavior pretty quickly. Here is a perfmon graph showing several runs:

You can see that the first two bursts had quick scale up with the thread count. After that, it went back to being slow. After working with the CLR team, they determined that there is a bug in the IO thread pool. This bug causes the internal count of IO threads to get out-of-sync with reality. Some of you may be asking the question as to what min really means in terms of the thread pool. Because if you specify you want a minimum of 100 threads, why wouldn't there just always be 100 threads? For the purposes of the thread pool, the min is supposed to be the threshold that the pool can scale up to before it starts to be metered. The default working set cost for one thread is a half MB. So that is one reason to keep the thread count down.
Some customers have found that Juval Lowy's thread pool doesn't have the same problem and handles these bursts of work much better. Here is a link to his article: https://msdn.microsoft.com/en-us/magazine/cc163321.aspx
Notice that Juval has created a custom thread pool and relies on the SynchronizationContext to switch from the IO thread that WCF uses to the custom thread pool. Using a custom thread pool in your production environment is not advisable. Most developers do not have the resources to properly test a custom thread pool for their applications. Thankfully, there is an alternative and that is the recommendation made in the KB article. The alternative is to use the worker thread pool. Juval has some code for a custom attribute that you can put on your service to set the SynchronizationContext to use his custom thread pool and we can just modify that to put the work into the worker thread pool. The code for this change is all in the KB article, but I'll reiterate here along with with the changes to the service itself.
using System;
using System.Threading;
using System.ServiceModel.Description;
using System.ServiceModel.Channels;
using System.ServiceModel.Dispatcher;
[WorkerThreadPoolBehavior]
public class Service1 : IService1
{
public string GetData(int value)
{
Thread.Sleep(TimeSpan.FromSeconds(2));
return string.Format("You entered: {0}", value);
}
}
public class WorkerThreadPoolSynchronizer : SynchronizationContext
{
public override void Post(SendOrPostCallback d, object state)
{
// WCF almost always uses Post
ThreadPool.QueueUserWorkItem(new WaitCallback(d), state);
}
public override void Send(SendOrPostCallback d, object state)
{
// Only the peer channel in WCF uses Send
d(state);
}
}
[AttributeUsage(AttributeTargets.Class)]
public class WorkerThreadPoolBehaviorAttribute : Attribute, IContractBehavior
{
private static WorkerThreadPoolSynchronizer synchronizer = new WorkerThreadPoolSynchronizer();
void IContractBehavior.AddBindingParameters(
ContractDescription contractDescription,
ServiceEndpoint endpoint,
BindingParameterCollection bindingParameters)
{
}
void IContractBehavior.ApplyClientBehavior(
ContractDescription contractDescription,
ServiceEndpoint endpoint,
ClientRuntime clientRuntime)
{
}
void IContractBehavior.ApplyDispatchBehavior(
ContractDescription contractDescription,
ServiceEndpoint endpoint,
DispatchRuntime dispatchRuntime)
{
dispatchRuntime.SynchronizationContext = synchronizer;
}
void IContractBehavior.Validate(
ContractDescription contractDescription,
ServiceEndpoint endpoint)
{
}
}
The areas highlighted above show the most important bits for this change. There really isn't that much code to this. With this change essentially what is happening is that WCF recognizes that when it's time to execute the service code, there is an ambient SynchronizationContext. That context then pushes the work into the worker thread pool with QueueUserWorkItem. The only other change to make is to the <processModel> node in the machine.config to configure the worker thread pool for a higher min and max.
<system.web>
<!--<processModel autoConfig="true"/>-->
<processModel
autoConfig="false"
minWorkerThreads="100"
maxWorkerThreads="200"
/>
Running the test again, you will see a much better result:

All of the test runs finished in under 2.5 seconds.
We cannot make a recommendation on this alone though. There are other questions like how does this affect performance and does it continue to work this way for hours, days, weeks, etc. Our testing showed that for at least 72 hours, this worked without a problem. The performance runs showed some caveats though. These are also pointed out in the KB article. There is a cost for switching from one thread to another. This would be the same with the worker thread pool or a custom thread pool. That overhead can be negligible for large amounts of work. In the case that applies here with 2 seconds of blocking work, the context switch is definitely not a factor. But if you've got small messages and fast work, then it's likely to hurt your performance.
The test project is included with this post.
Originally posted on Dustin Metzgar's blog
Comments
Anonymous
May 04, 2011
Isn't this just covering up the problem that the service is implemented with excessive blocking on the IOCP threads? Ideally, the IOCP thread should just be performing actual non-blocking work with any potentially blocking calls made async or on a separate worker thread if there is no proper async call available.Anonymous
May 04, 2011
@Karg - You are correct. Ideally the customer should change to an async model but it is not always possible.Anonymous
May 06, 2011
Dustin, If "The test project is included with this post" I can't find the link. Cheers, --rjAnonymous
May 06, 2011
The comment has been removed