PySpark: Appending columns to DataFrame when DataFrame.withColumn cannot be used
The sample Jupyter Python notebook described in this blog can be downloaded from https://github.com/hdinsight/spark-jupyter-notebooks/blob/master/Python/AppendDataFrameColumn.ipynb
In many Spark applications, there are common use cases in which columns derived from one or more existing columns in a DataFrame are appended during the data preparation or data transformation stages. DataFrame provides a convenient method of form DataFrame.withColumn([string] columnName, [udf] userDefinedFunction) to append column to an existing DataFrame. Here the userDefinedFunction is of type pyspark.sql.functions.udf which is of the form udf(userMethod, returnType) . The userMethod is the actual python method the user application implements and the returnType has to be one of the types defined in pyspark.sql.types, the user method can return. Here is an example python notebook that creates a DataFrame of rectangles.

Let us suppose that the application needs to add the length of the diagonals of the rectangle as a new column in the DataFrame. Since the length of the diagonal can be represented as a float DataFrame.withColumn can be used with returnType as FloatType.

Let us now suppose that this is a computer graphics application and for animation purposes the application needs to add the clockwise rotation matrix defined as 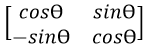 , where Ɵ is the degree of rotation, as another column in the DataFrame for later processing.
, where Ɵ is the degree of rotation, as another column in the DataFrame for later processing.

The issue is DataFrame.withColumn cannot be used here since the matrix needs to be of the type pyspark.mllib.linalg.Matrix which is not a type defined in pyspark.sql.types. We will show two ways of appending the new column, the first one being the naïve way and the second one the Spark way. The naive method uses collect to accumulate a subset of columns at the driver, iterates over each row to apply the user defined method to generate and append the additional column per row, parallelizes the rows as RDD and generates a DataFrame out of it, uses join with the newly created DataFrame to join it with the original DataFrame and then drops the duplicate columns to generate the final DataFrame. This method is bound to hit scalability limits as the data size grows resulting in eventual job failure. In general it is strongly recommended to avoid collect and join in data transformations as much as possible. Collect has the effect of serializing (as opposed to distributing) the job by bringing the entire data to the driver and join has the risk of proliferating the number of rows if applied on non-unique keys.
What NOT to do: 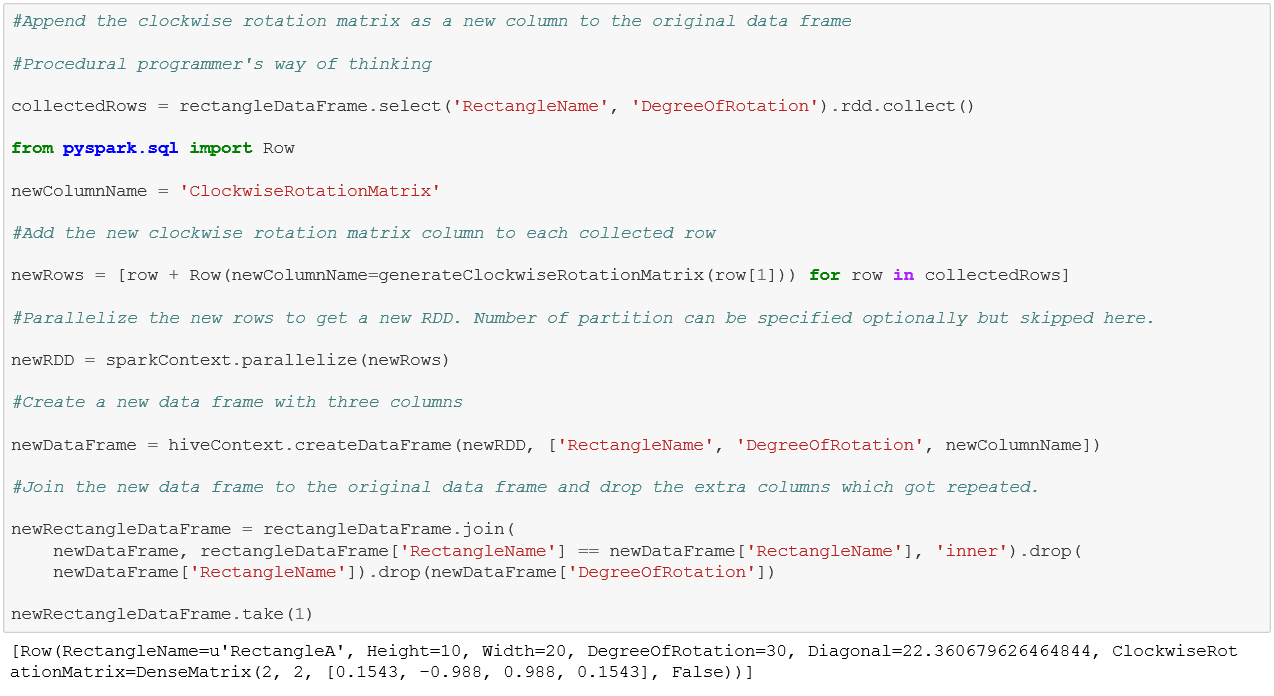
In this specific case collect and join can be completely avoided. The Spark way is to use map on the DataFrame, append each row with a new column applying the clockwise rotation matrix generation method and then converting the resulting pipeline RDD into DataFrame with the column names imposed back as part of the schema.
What to do:
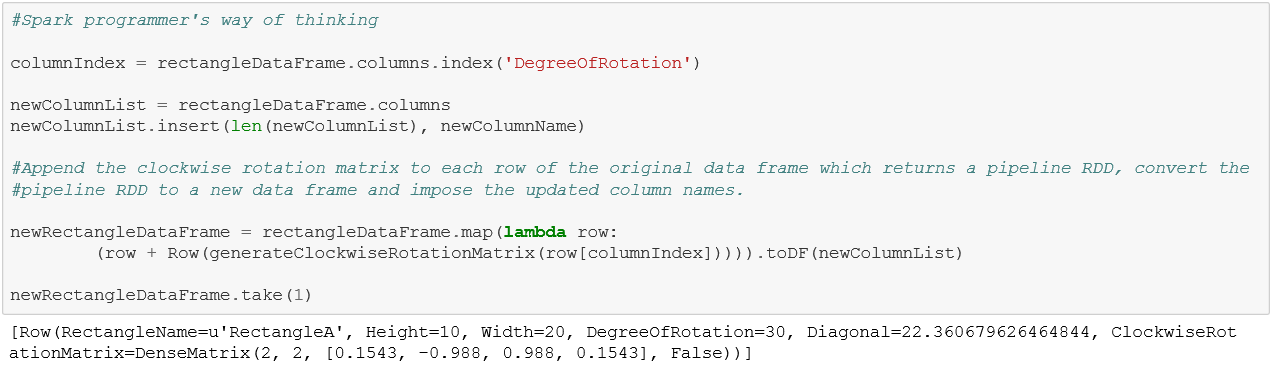
[Contributed by Arijit Tarafdar and Lin Chan]