Extending Spark with Extension Methods in Scala: Fun with Implicits
The sample Jupyter Scala notebook described in this blog can be downloaded from https://github.com/hdinsight/spark-jupyter-notebooks/blob/master/Scala/ScalaExtensionMethod.ipynb
Extension methods are programming language constructs which enable extending an object with additional methods after the original object has already been compiled. They are useful when a developer wants to add capabilities to an existing object when only the compiled object is available or the developer does not want to modify the source code or the source code is not available or accessible to the developer. Scala supports extension methods through implicits which we will use in an example to extend Spark DataFrame with a method to save it in an Azure SQL table. Though this example is presented as a complete Jupyter notebook that can be run on HDInsight clusters, the purpose of this blog is to demonstrate a way to the Spark developers to ship their JARs that extend Spark with new functionalities.
To start with this example we need to configure Jupyter to use an additional Microsoft JDBC Driver JAR available at https://www.microsoft.com/en-us/download/details.aspx?id=11774 and place it in a known folder in the default container of the default storage account of the HDInsight cluster. To learn about how to deploy Azure HDInsight Linux Spark cluster and launch Jupyter notebook refer to the Azure article at https://azure.microsoft.com/en-us/documentation/articles/hdinsight-apache-spark-jupyter-spark-sql/ 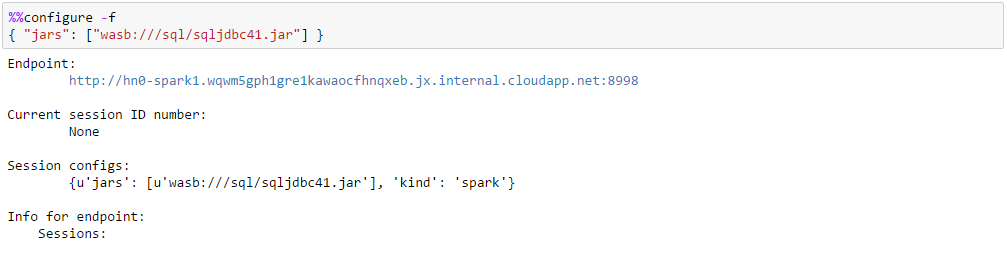
Define a case class Rectangle that will hold the data which will be used to create the DataFrame for this example. In practice the DataFrame data source can be anything that is supported by Spark.

Define a simple utility class to generate the Azure SQL database connection string from Azure SQL server fully qualified domain name, Azure SQL database name, Azure SQL database username and Azure SQL database password.
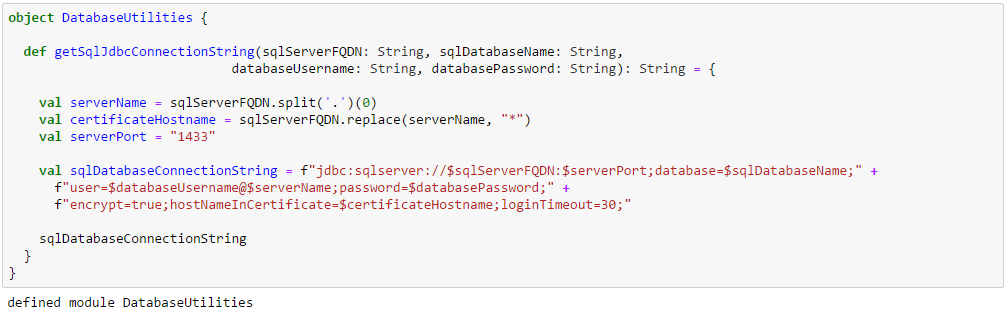
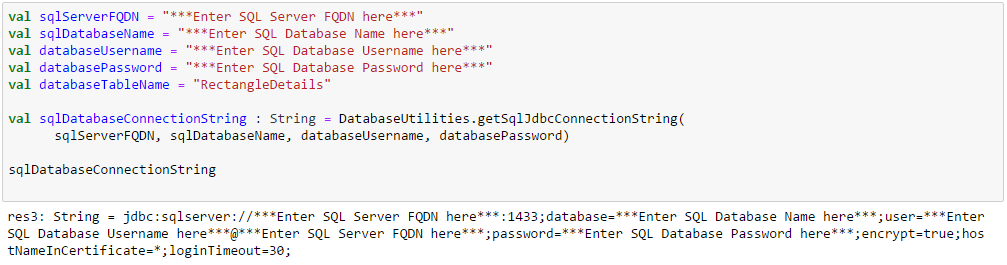
Enter the correct database parameters by replacing the entries marked below and create the Azure SQL database connection string.
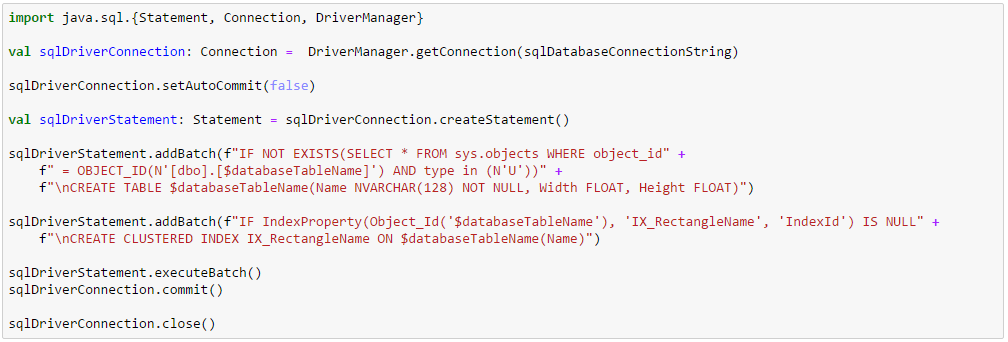
Create the Azure SQL table that corresponds to the case class Rectangle defined earlier. Azure SQL mandates a clustered index needs to be created in absence of a primary key. This part of the code runs once in the driver.
The DataFrameExtension object is the crux of this blog. It defines a class ExtendedDataFrame that takes in the DataFrame object in the constructor and defines a methods saveToAzureSQL that takes in the Azure SQL database connection string and the Azure SQL table name as parameters. This method first creates a comma separated string out of the column names of the DataFrame that will be part of the column identifiers of Azure SQL insert statement. It then creates a format string based on the data types of the DataFrame columns that will hold each row of the DataFrame as part of the values in the same insert statement. Each partition in the DataFrame will then be grouped into batches of 1000 records and added to the insert statement based on the format determined earlier to create a multiple row insert statement. The insert statement is then executed through executeUpdate method of the Azure SQL JDBC connection object to actually land the data in the Azure SQL table. An implicit conversion rule is named with the extendedDataFrame instance to help resolve the saveToAzureSql method when called on the DataFrame object in the application code. For basic details of Scala implicit conversions refer to https://docs.scala-lang.org/tutorials/tour/implicit-conversions.html 
To test the implicit conversion rule declared above create a list of Rectangle objects.

Use the hiveContext already instantiated by the Jupyter Scala notebook to create a DataFrame out of the list of Rectangle objects.

Import the DataFrameExtension object declared above and call the saveToAzureSql method directly on the DataFrame as if the method is actually declared inside of the DataFrame class. This part of the code runs on executors.

Verify that the data is actually saved in the Azure SQL table.
[Contributed by Arijit Tarafdar]