管理工作階段範圍的套件
除了集區層級套件之外,您也可以在筆記本會話的開頭指定會話範圍的連結庫。 會話範圍的連結庫可讓您在筆記本會話內指定及使用 Python、jar 和 R 套件。
使用會話範圍的連結庫時,請務必記住下列幾點:
- 您在安裝工作階段範圍的程式庫時,只有目前的筆記本可存取指定的程式庫。
- 這些連結庫不會影響使用相同 Spark 集區的其他工作階段或作業。
- 這些連結庫會安裝在基底運行時間和集區層級連結庫之上,並採用最高優先順序。
- 會話範圍的連結庫不會跨會話保存。
會話範圍的 Python 套件
透過 environment.yml 檔案管理會話範圍的 Python 套件
若要指定會話範圍的 Python 套件:
- 流覽至選取的 Spark 集區,並確定您已啟用工作階段層級連結庫。 您可以瀏覽至 [管理>Apache Spark 集區>套件] 索引標籤來啟用此設定。
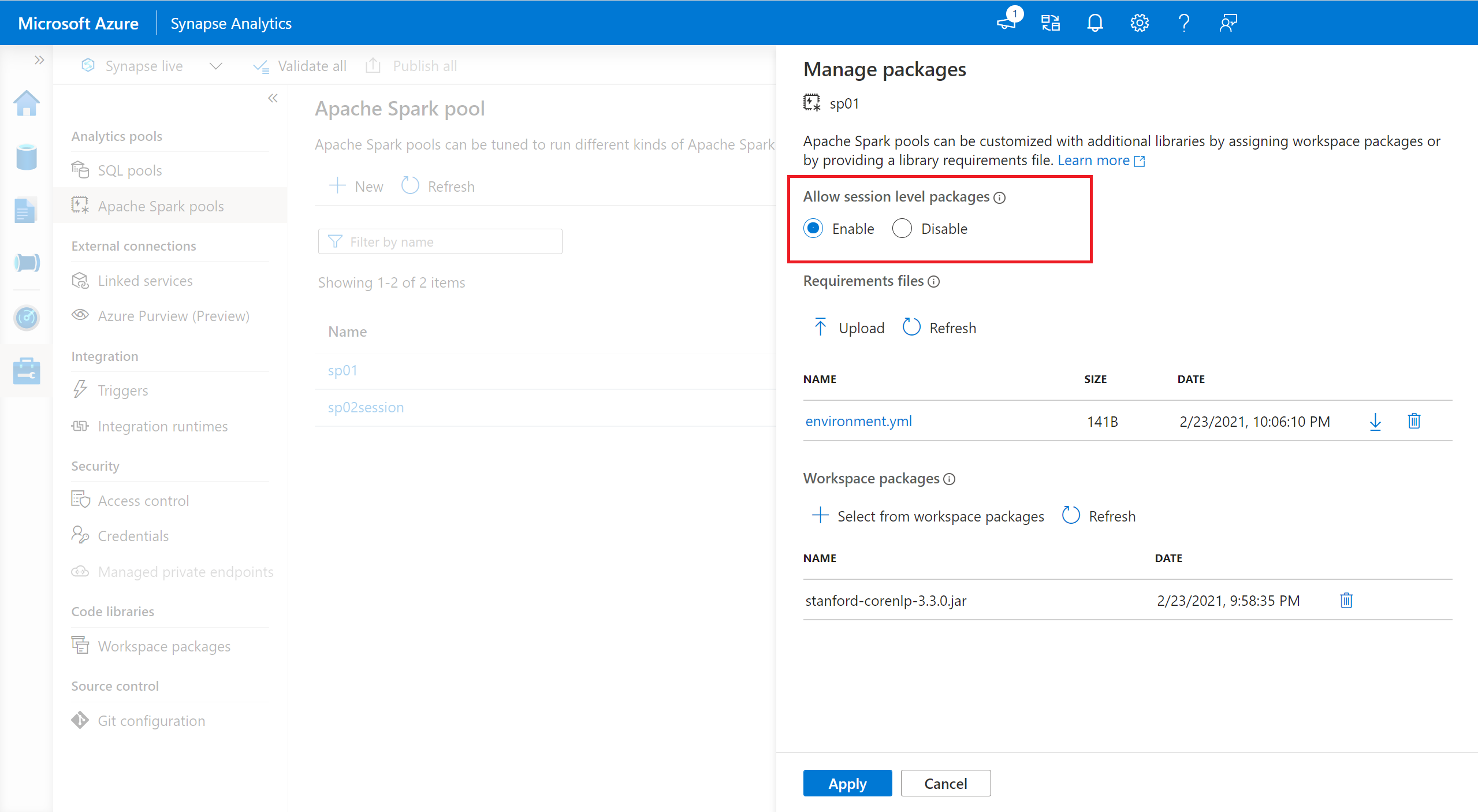
- 套用設定之後,您可以開啟筆記本,然後選取 [設定會話>套件]。

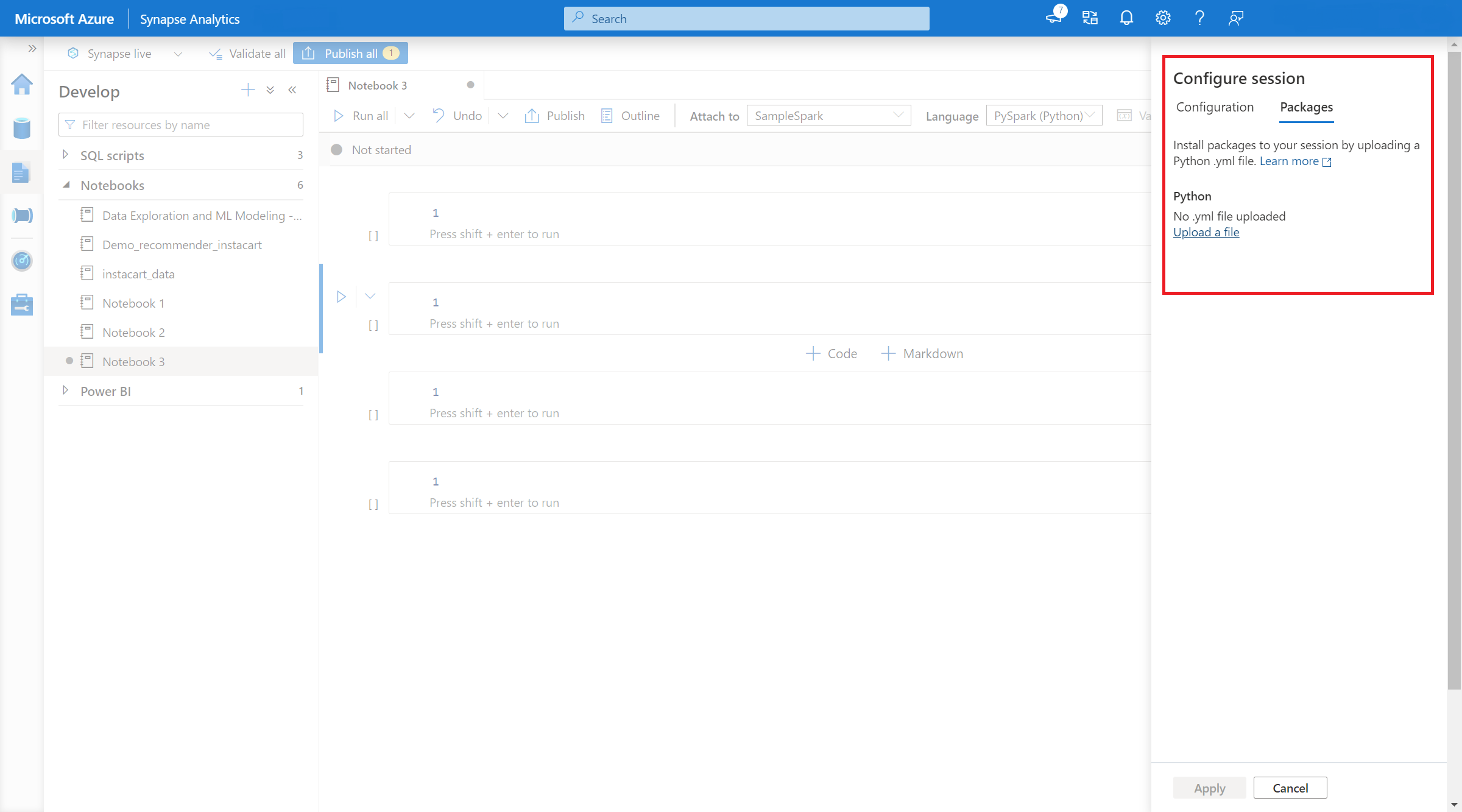
- 在這裡,您可以上傳 Conda environment.yml 檔案,以在工作階段內安裝或升級套件。會話啟動時,就會有指定的連結庫。 會話結束後,這些連結庫將無法再使用。

透過 %pip 和 %conda 命令管理會話範圍的 Python 套件
您可以使用熱門 的 %pip 和 %conda 命令,在 Apache Spark 筆記本會話期間安裝其他第三方連結庫或自定義連結庫。 在本節中,我們使用 %pip 命令來示範數個常見案例。
注意
安裝第三方套件
您可以輕鬆地從 PyPI 安裝 Python 連結庫。
# Install vega_datasets
%pip install altair vega_datasets
若要確認安裝結果,您可以執行下列程式代碼來可視化vega_datasets
# Create a scatter plot
# Plot Miles per gallon against the horsepower across different region
import altair as alt
from vega_datasets import data
cars = data.cars()
alt.Chart(cars).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color='Origin',
).interactive()
從記憶體帳戶安裝轉輪套件
若要從記憶體安裝連結庫,您必須執行下列命令來掛接至記憶體帳戶。
from notebookutils import mssparkutils
mssparkutils.fs.mount(
"abfss://<<file system>>@<<storage account>.dfs.core.windows.net",
"/<<path to wheel file>>",
{"linkedService":"<<storage name>>"}
)
然後,您可以使用 %pip install 命令來安裝必要的 wheel 套件
%pip install /<<path to wheel file>>/<<wheel package name>>.whl
安裝另一個版本的內建連結庫
您可以使用下列命令來查看特定套件的內建版本。 我們使用 pandas 作為範例
%pip show pandas
結果如下:
Name: pandas
Version: **1.2.3**
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
... ...
您可以使用下列命令將 pandas 切換至另一個版本,假設是 1.2.4
%pip install pandas==1.2.4
卸載會話範圍的連結庫
如果您想要卸載此筆記本會話上安裝的套件,您可以參考下列命令。 不過,您無法卸載內建套件。
%pip uninstall altair vega_datasets --yes
使用 %pip 命令從 requirement.txt 檔案安裝連結庫
%pip install -r /<<path to requirement file>>/requirements.txt
會話範圍的 Java 或 Scala 套件
若要指定工作階段範圍的 Java 或 Scala 套件,您可以使用 %%configure 選項:
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<file system>>@<<storage account>.dfs.core.windows.net/<<path to JAR file>>",
}
}
注意
- 建議您在筆記本開頭執行 %%configure。 如需有效參數的完整清單,請參閱本 檔 。
工作階段範圍的 R 套件 (預覽)
Azure Synapse Analytics 集區包含許多現用的 R 連結庫。 您也可以在 Apache Spark 筆記本作業階段期間安裝額外的第三方連結庫。
注意
- 執行管線作業時,將會停用管理 R 連結庫的這些命令。 如果您想要在管線內安裝套件,您必須在集區層級利用連結庫管理功能。
- 工作階段範圍的 R 程式庫會自動安裝在驅動程式和背景工作角色節點。
安裝套件
您可以從 CRAN 輕鬆安裝 R 程式庫。
# Install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
您還可以使用 CRAN 快照做為存放庫,以確保每次下載相同的套件版本。
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
使用 devtools 安裝套件
devtools 程式庫可簡化套件開發,以加速一般工作。 此連結庫會安裝在預設的 Azure Synapse Analytics 運行時間內。
您可以使用 devtools 來指定要安裝的特定程式庫版本。 這些連結庫將會安裝在叢集內的所有節點。
# Install a specific version.
install_version("caesar", version = "1.0.0")
同樣地,您可以直接透過 GitHub 安裝程式庫。
# Install a GitHub library.
install_github("jtilly/matchingR")
Azure Synapse Analytics 目前支援下列 devtools 函式:
| Command | 描述 |
|---|---|
| install_github() | 透過 GitHub 安裝 R 套件 |
| install_gitlab() | 透過 GitLab 安裝 R 套件 |
| install_bitbucket() | 從 Bitbucket 安裝 R 套件 |
| install_url() | 透過任意網址安裝 R 套件 |
| install_git() | 透過任意 Git 存放庫安裝 |
| install_local() | 透過磁碟上的本機檔案安裝 |
| install_version() | 透過 CRAN 上的特定版本安裝 |
檢視安裝的程式庫
您可以使用 命令查詢工作階段 library 內安裝的所有連結庫。
library()
您可以使用 函 packageVersion 式來檢查連結庫的版本:
packageVersion("caesar")
從工作階段中移除 R 套件
您可以使用 detach 函數,從命名空間中移除程式庫。 這些程式庫會保留在磁碟上,直至在此將其載入。
# detach a library
detach("package: caesar")
若要從筆記本中移除工作階段範圍的套件,請使用 remove.packages() 命令。 此程式庫變更不會影響相同叢集上的其他工作階段。 用戶無法卸載或移除預設 Azure Synapse Analytics 運行時間的內建連結庫。
remove.packages("caesar")
注意
您無法移除 SparkR、SparklyR 或 R 等核心套件。
工作階段範圍的 R 程式庫和 SparkR
SparkR 背景工作角色提供筆記本範圍的程式庫。
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
會話範圍的 R 連結庫和 SparklyR
在SparklyR中使用 spark_apply() 時,您可以在Spark內使用任何 R 套件。 根據預設,在sparklyr::spark_apply()中,packages自變數會設定為 FALSE。 這會將目前 libPaths 中的程式庫複製到背景工作角色,讓您在背景工作角色匯入和使用程式庫。 例如,您可以執行下列命令,以使用sparklyr::spark_apply():
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- "3.2"
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
下一步
- 檢視預設程式庫:Apache Spark 版本支援
- 管理 Synapse Studio 入口網站外的套件: 透過 Az 命令和 REST API 管理套件