整合 Azure 串流分析與 Azure Machine Learning
您可以將機器學習模型實作為 Azure 串流分析作業中的使用者定義函式 (UDF),以對串流輸入資料執行即時評分和預測。 Azure Machine Learning 可讓您使用任何熱門的開放原始碼工具 (例如 TensorFlow、scikit-learn 或 PyTorch) 來準備、定型和部署模型。
必要條件
請先完成下列步驟,再將機器學習模型新增為串流分析作業的函式:
使用 Azure Machine Learning 將您的模型部署為 Web 服務。
您的機器學習端點必須具有相關聯的 Swagger,以協助串流分析了解輸入和輸出的結構描述。 您可以使用此範例 Swagger 定義 (英文) 作為參考,以確保您已正確加以設定。
請確定您的 Web 服務接受並傳回 JSON 序列化資料。
將模型部署到 Azure Kubernetes Service 上以進行大規模生產部署。 如果 Web 服務無法處理來自您作業的要求數,串流分析作業的效能會降低,因而影響延遲。 只有當您使用 Azure 入口網站時,才支援在 Azure 容器執行個體上部署的模型。
將機器學習模型新增至您的作業
您可以直接從 Azure 入口網站或 Visual Studio Code,將 Azure Machine Learning 函式新增至串流分析作業。
Azure 入口網站
在 Azure 入口網站中瀏覽至您的串流分析作業,然後選取 [作業拓撲] 底下的 [函式]。 然後,從 [+新增] 下拉式功能表中選取 [Azure Machine Learning 服務]。
以下列屬性值填入 Azure Machine Learning 服務函式表單:
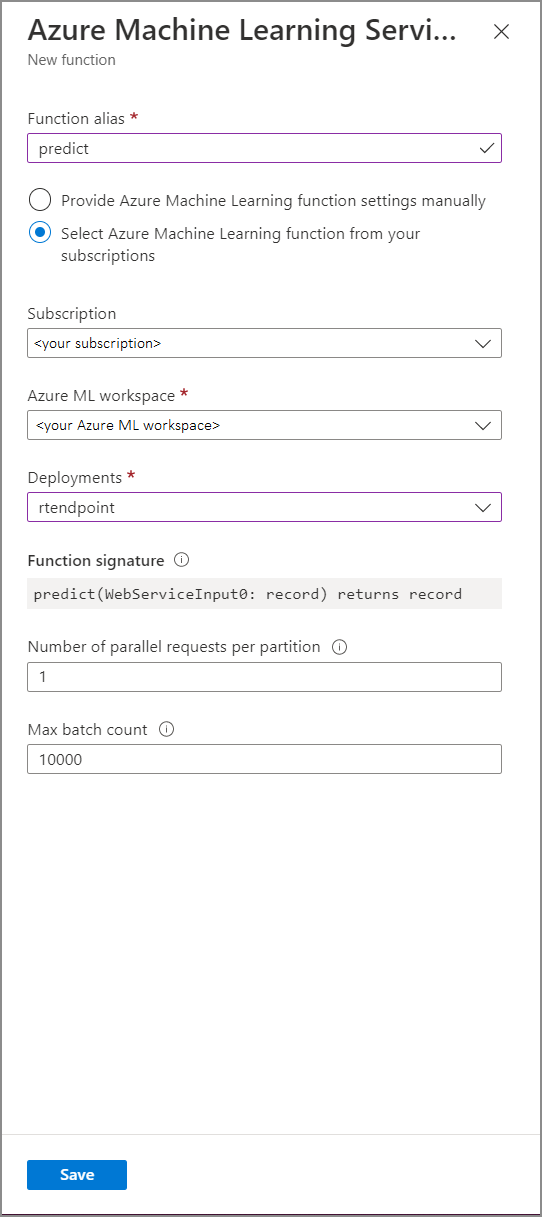
下表描述串流分析中 Azure Machine Learning 服務函式的每個屬性。
| 屬性 | 說明 |
|---|---|
| 函式別名 | 輸入名稱以在查詢中叫用函式。 |
| 訂用帳戶 | 您的 Azure 訂閱。 |
| Azure Machine Learning 工作區 | 您用來將模型部署為 Web 服務的 Azure Machine Learning 工作區。 |
| 端點 | 裝載模型的 Web 服務。 |
| 函式簽章 | 從 API 結構描述規格推斷而來的 Web 服務簽章。 如果您的簽章無法載入,請檢查您是否已在評分指令碼中提供範例輸入和輸出,以自動產生結構描述。 |
| 每個分割的平行要求數目 | 這是最佳化大量輸送量的進階設定。 此數字代表從作業的每個分割傳送到 Web 服務的並行要求。 具有六個串流單位 (SU) 和更低單位的作業有一個分割。 具有 12 個 SU 的作業有兩個分割,具有 18 個 SU 的作業有三個分割,依此類推。 例如,如果您的作業有兩個分割,而且您將此參數設定為 4,則您的作業至 Web 服務將會有八個並行要求。 |
| 批次計數上限 | 這是最佳化大量輸送量的進階設定。 此數字代表在傳送至 Web 服務的單一要求中,將事件一起批次處理的數目上限。 |
從您的查詢呼叫機器學習端點
當您的串流分析查詢叫用 Azure Machine Learning UDF 時,作業會對 Web 服務建立 JSON 序列化要求。 要求的依據為串流分析從端點 Swagger 推斷的模型特定結構描述。
警告
當您使用 Azure 入口網站 查詢編輯器進行測試時,不會呼叫 機器學習 端點,因為作業未執行。 若要從入口網站測試端點呼叫,串流分析作業必須執行。
下列串流分析查詢是如何叫用 Azure Machine Learning UDF 的範例:
SELECT udf.score(<model-specific-data-structure>)
INTO output
FROM input
WHERE <model-specific-data-structure> is not null
如果傳送至 ML UDF 的輸入資料與預期的結構描述不一致,端點將傳回錯誤碼 400 的回應,其將導致串流分析作業進入失敗狀態。 建議您為作業啟用資源記錄,這可讓您輕鬆地對此類問題進行偵錯和疑難排解。 因此,強烈建議您:
- 驗證對您 ML UDF 的輸入不為 null
- 針對每個為您 ML UDF 輸入的欄位,驗證其類型,以確保其符合端點預期的內容
注意
ML UDF 會針對給定查詢步驟的每個資料列進行評估,即使是當透過條件運算式呼叫 (亦即 CASE WHEN [A] IS NOT NULL THEN udf.score(A) ELSE '' END)。 如有需要,請使用 WITH 子句來建立發散路徑,僅在必要時,並於再次使用 UNION 時才呼叫 ML UDF,以將路徑合併在一起。
將多個輸入參數傳遞至 UDF
最常見的機器學習模型輸入範例是 numpy 陣列和資料框架。 您可以使用 JavaScript UDF 建立陣列,以及使用 WITH 子句建立 JSON 序列化資料框架。
建立輸入陣列
您可以建立會接受 N 個輸入數目的 JavaScript UDF,以及建立可用來作為 Azure Machine Learning UDF 輸入的陣列。
function createArray(vendorid, weekday, pickuphour, passenger, distance) {
'use strict';
var array = [vendorid, weekday, pickuphour, passenger, distance]
return array;
}
將 JavaScript UDF 新增至作業之後,您可以使用下列查詢來叫用您的 Azure Machine Learning UDF:
WITH
ModelInput AS (
#use JavaScript UDF to construct array that will be used as input to ML UDF
SELECT udf.createArray(vendorid, weekday, pickuphour, passenger, distance) as inputArray
FROM input
)
SELECT udf.score(inputArray)
INTO output
FROM ModelInput
#validate inputArray is not null before passing it to ML UDF to prevent job from failing
WHERE inputArray is not null
下列 JSON 是範例要求:
{
"Inputs": {
"WebServiceInput0": [
["1","Mon","12","1","5.8"],
["2","Wed","10","2","10"]
]
}
}
建立 Pandas 或 PySpark 資料框架
您可以使用 WITH 子句來建立 JSON 序列化資料框架,此資料框架可以作為輸入傳遞至您的 Azure Machine Learning UDF,如下所示。
下列查詢會藉由選取必要欄位來建立資料框架,並使用資料框架作為 Azure Machine Learning UDF 的輸入。
WITH
Dataframe AS (
SELECT vendorid, weekday, pickuphour, passenger, distance
FROM input
)
SELECT udf.score(Dataframe)
INTO output
FROM Dataframe
WHERE Dataframe is not null
下列 JSON 是前一個查詢的範例要求:
{
"Inputs": {
"WebServiceInput0": [
{
"vendorid": "1",
"weekday": "Mon",
"pickuphour": "12",
"passenger": "1",
"distance": "5.8"
},
{
"vendorid": "2",
"weekday": "Tue",
"pickuphour": "10",
"passenger": "2",
"distance": "10"
}]
}
}
將 Azure Machine Learning UDF 的效能最佳化
當您將模型部署到 Azure Kubernetes Service 時,您可以分析模型以判斷資源使用率。 您也可以為您的部署啟用 App Insights,以了解要求速率、回應時間和失敗率。
如果您有高事件輸送量的案例,您可能需要變更串流分析中的下列參數,才能以較低的端對端延遲來達到最佳效能:
- 最大批次計數。
- 每個分割的平行要求數目。
決定正確的批次大小
在您部署 Web 服務之後,您會以不同的批次大小 (從 50 個開始) 傳送範例要求,並以百為單位來增加。 例如,200、500、1000、2000 等等。 您會注意到在特定批次大小之後,回應的延遲會增加。 回應延遲增加的時間點應該是作業的批次計數上限。
判斷每個分割的平行要求數目
在最佳調整的情況下,您的串流分析作業應該能夠將多個平行要求傳送至您的 Web 服務,並且在幾毫秒內取得回應。 Web 服務回應的延遲會直接影響串流分析作業的延遲和效能。 如果從您的作業到 Web 服務的呼叫需要很長的時間,您可能會發現浮水印延遲增加,而且可能也會看到待處理的輸入事件數目增加。
您可以透過確定 Azure Kubernetes Service (AKS) 叢集已佈建正確數目的節點和複本,來實現低延遲。 您的 Web 服務具有高可用性且會傳回成功的回應非常重要。 如果您的作業收到可重試的錯誤,例如服務無法使用的回應 (503),其將透過指數輪詢自動重試。 如果您的作業收到這其中一個錯誤作為端點的回應,則該作業將進入失敗狀態。
- 不正確的要求 (400)
- 衝突 (409)
- 找不到 (404)
- 未經授權 (401)
限制
如果您使用 Azure ML 受控端點服務,串流分析目前只能存取已啟用公用網路存取的端點。 在關於 Azure ML 私人端點的頁面上深入了解。