在電腦上安裝 Jupyter Notebook,並連線至 HDInsight 上的 Apache Spark
本文中,您會了解如何搭配具有 Spark magic 的自訂 PySpark (適用於 Python) 與 Apache Spark (適用於 Scala) 核心來安裝 Jupyter Notebook。 然後,將該筆記本連線至 HDInsight 叢集。
安裝 Jupyter 並連線至 HDInsight 上的 Apache Spark 涉及四個主要步驟。
- 設定 Spark 叢集。
- 安裝 Jupyter Notebook。
- 安裝含有 Spark magic 的 PySpark 和 Spark 核心。
- 設定 Spark magic 以存取 HDInsight 上的 Spark 叢集。
如需自訂核心與 Spark magic 的詳細資訊,請參閱 HDInsight 上的 Apache Spark Linux 叢集可供 Jupyter Notebook 使用的核心。
必要條件
HDInsight 上的 Apache Spark 叢集。 如需指示,請參閱在 Azure HDInsight 中建立 Apache Spark 叢集。 本機筆記本會連線至 HDInsight 叢集。
熟悉如何搭配使用 Jupyter Notebook 和 HDInsight 上的 Spark。
在電腦上安裝 Jupyter Notebook
安裝 Jupyter Notebook 之前要先安裝 Python。 Anaconda 散發會同時安裝 Python 與 Jupyter Notebook。
下載您平台適用的 Anaconda 安裝程式 ,然後執行安裝程式。 執行安裝精靈時,請確定您選取將 Anaconda 新增至 PATH 變數的選項。 另請參閱使用 Anaconda 安裝 Jupyter。
安裝 Spark magic
輸入命令
pip install sparkmagic==0.13.1以安裝 HDInsight 叢集 3.6 版與 4.0 版的 Spark magic。 另請參閱 sparkmagic 文件。執行下列命令來確定
ipywidgets已正確安裝:jupyter nbextension enable --py --sys-prefix widgetsnbextension
安裝 PySpark 與 Spark 核心
輸入下列命令來識別安裝
sparkmagic的位置:pip show sparkmagic然後將您的工作目錄變更為使用上述命令進行識別的位置。
從新的工作目錄中,輸入以下一或多個命令,以安裝想要的核心:
核心 Command Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernel選擇性。 輸入以下命令以啟用伺服器延伸模組:
jupyter serverextension enable --py sparkmagic
設定 Spark magic 以連線到 HDInsight Spark 叢集
在本節中,您會設定稍早安裝的 Spark magic,以連線至 Apache Spark 叢集。
使用下列命令啟動 Python 殼層:
pythonJupyter 組態資訊通常儲存在使用者主目錄中。 輸入下列命令來識別主目錄,並建立稱為 .sparkmagic 的資料夾。 將會輸出該完整路徑。
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()在資料夾
.sparkmagic中,建立一個名為 config.json 的檔案,並在其中新增下列 JSON 程式碼片段。{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }對該檔案進行下列編輯:
範本值 新值 {USERNAME} 叢集登入,預設值為 admin。{CLUSTERDNSNAME} 叢集名稱 {BASE64ENCODEDPASSWORD} 您實際密碼的 base64 編碼密碼。 您可以在 https://www.url-encode-decode.com/base64-encode-decode/ 產生 base64 密碼。 "livy_server_heartbeat_timeout_seconds": 60若使用 sparkmagic 0.12.7(叢集 v3.5 與 v3.6),請保留。 若使用sparkmagic 0.2.3(叢集 v3.4),請取代為"should_heartbeat": true。您可以在範例 config.json 中查看完整的範例檔案。
提示
傳送活動訊號可確保不會流失工作階段。 當電腦進入睡眠或已關機時,則不會傳送活動訊號,導致工作階段被清除。 若為叢集 3.4 版,如果想要停用此行為,您可以從 Ambari UI 將 Livy 組態
livy.server.interactive.heartbeat.timeout設定為0。 若為叢集 3.5 版,如果您未設定上述的 3.5 組態,則不會刪除工作階段。啟動 Jupyter。 從命令提示字元使用下列命令。
jupyter notebook確認您可以搭配核心一起使用 Spark magic。 完成下列步驟。
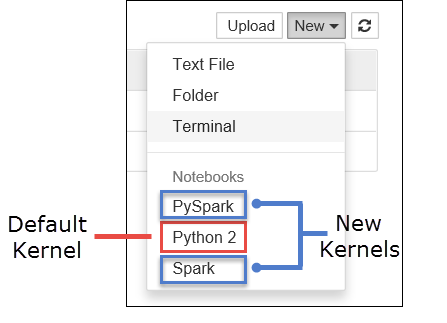
a. 建立新的 Notebook。 從右下角選取 [新增]。 您應該會看到預設核心 Python 2 或 Python 3,以及您已安裝的核心。 實際值可能會依據您的安裝選擇而有所不同。 選取 [PySpark]。
重要
選取 [新增] 之後,檢閱殼層中的任何錯誤。 若您看到錯誤
TypeError: __init__() got an unexpected keyword argument 'io_loop',可能遇到 Tornado 特定版本的已知問題。 若是如此,請停止核心,然後使用下列命令將 Tornado 安裝降級:pip install tornado==4.5.3。b. 執行下列程式碼片段。
%%sql SELECT * FROM hivesampletable LIMIT 5如果您可以順利擷取輸出,即表示已測試您對 HDInsight 叢集的連線。
若您想要更新筆記本設定以連線至不同的叢集,請以一組新的值更新 config.json,如上述步驟 3 所示。
為什麼我應該在我的電腦上安裝 Jupyter?
在您的電腦上安裝 Jupyter,然後將其連線至 HDInsight 上 Apache Spark 叢集的原因:
- 提供在本機建立筆記本的選項、對正在執行的叢集測試應用程式,以及將筆記本上傳至叢集。 若要將筆記本上傳至叢集,您可以使用正在執行的 Jupyter Notebook 或叢集來加以上傳,或將其儲存至與叢集建立關聯之儲存體帳戶的
/HdiNotebooks資料夾。 如需如何在叢集上儲存筆記本的詳細資訊,請參閱 Jupyter Notebook 會儲存在哪裡? - 使用本機可用的 Notebook,您可以根據您的應用程式需求,連接至不同的 Spark 叢集。
- 您可以使用 GitHub 實作來源控制系統,並且具有 Notebook 的版本控制。 您也可以有共同作業環境,其中多個使用者可以使用相同的 Notebook。
- 您甚至不需要啟用叢集,即可在本機使用 Notebook。 您只需要叢集針對 Notebook 進行測試,不必以手動方式管理您的 Notebook 或開發環境。
- 設定自己的本機開發環境比設定叢集上的 Jupyter 安裝更容易。 您可以利用您已經在本機安裝的所有軟體,而不需要設定一或多個遠端叢集。
警告
將 Jupyter 安裝在本機電腦上,多個使用者可以同時在相同的 Spark 叢集上執行相同的 Notebook。 在這種情況下,會建立多個 Livy 工作階段。 如果您遇到問題,而且想要偵錯,則追蹤哪個 Livy 工作階段屬於哪個使用者會是複雜的工作。