使用 Apache Spark 歷程記錄伺服器的擴充功能來偵錯和診斷 Spark 應用程式
本文說明如何使用 Apache Spark 歷程記錄伺服器的擴充功能來偵錯及診斷已完成或執行中的 Spark 應用程式。 此延伸模組包含 [數據] 索引標籤、[圖形] 索引標籤和 [診斷] 索引標籤。在 [數據] 索引標籤上,您可以檢查 Spark 作業的輸入和輸出資料。 在 [ 圖形 ] 索引標籤上,您可以檢查數據流並重新執行作業圖形。 在 [ 診斷] 索引 標籤上,您可以參考 資料扭曲、 時間扭曲和 執行程式使用分析 功能。
取得 Spark 歷程記錄伺服器的存取權
Spark 歷程記錄伺服器是已完成和執行 Spark 應用程式的 Web UI。 您可以從 Azure 入口網站 或 URL 開啟它。
從 Azure 入口網站 開啟 Spark 歷程記錄伺服器 Web UI
從 Azure 入口網站,開啟 Spark 叢集。 如需詳細資訊,請參閱列出和顯示叢集。
從 [叢集儀錶板] 中,選取 [Spark 記錄伺服器]。 出現提示時,輸入 Spark 叢集的系統管理員認證。
 Azure 入口網站.“ border=”true“::
Azure 入口網站.“ border=”true“::
依 URL 開啟 Spark 歷程記錄伺服器 Web UI
流覽至 https://CLUSTERNAME.azurehdinsight.net/sparkhistory以開啟 Spark 歷程記錄伺服器,其中 CLUSTERNAME 是 Spark 叢集的名稱。
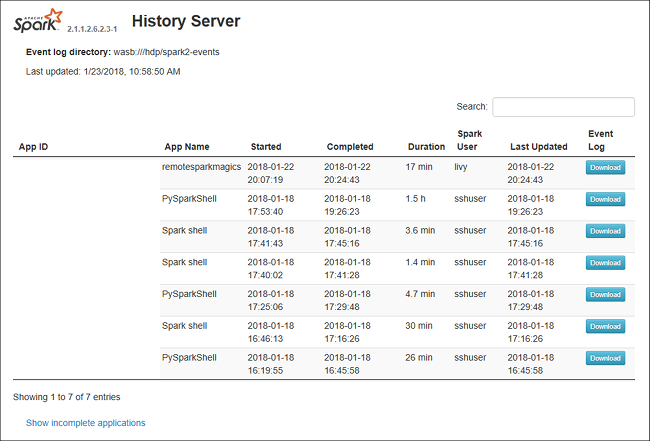
Spark 歷程記錄伺服器 Web UI 看起來可能類似下圖:
在 Spark 歷程記錄伺服器中使用 [資料] 索引標籤
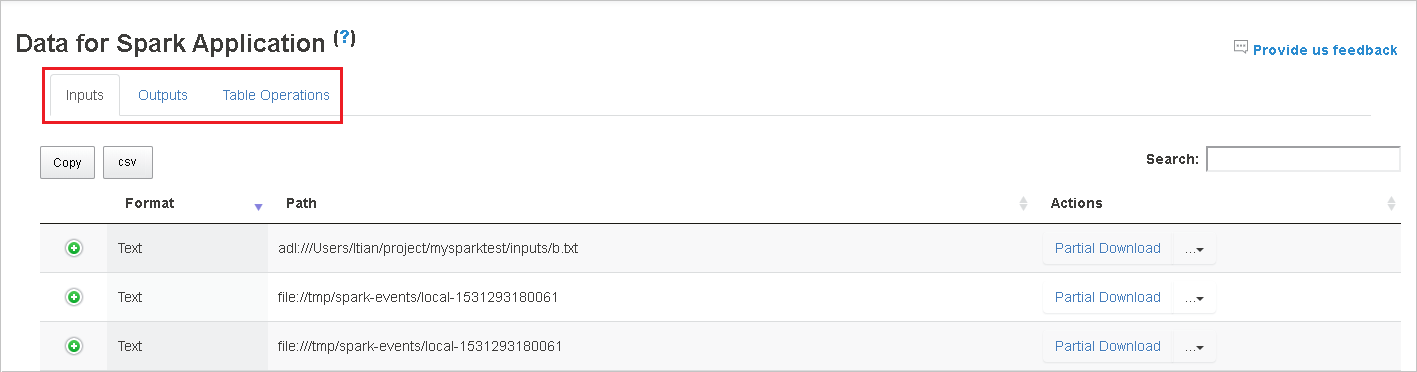
選取作業標識碼,然後選取 工具功能表上的 [資料 ] 以查看數據檢視。
選取個別索引標籤,以檢閱輸入、輸出和數據表作業。
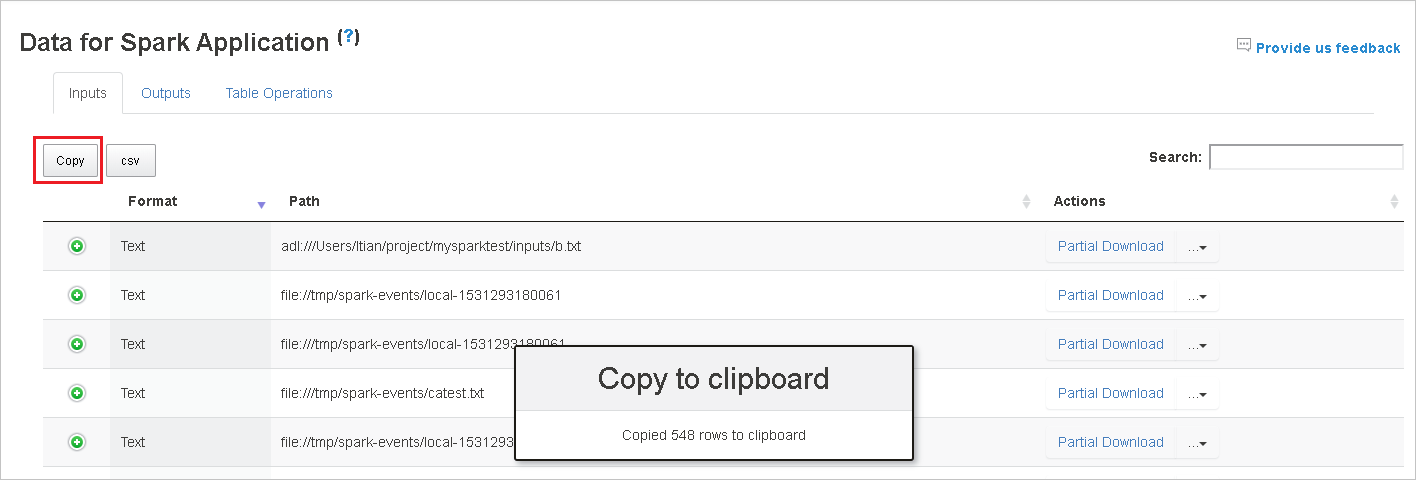
選取 [ 複製] 按鈕來複製所有資料列。
將所有資料儲存為 。選取 csv 按鈕以 CSV 檔案。
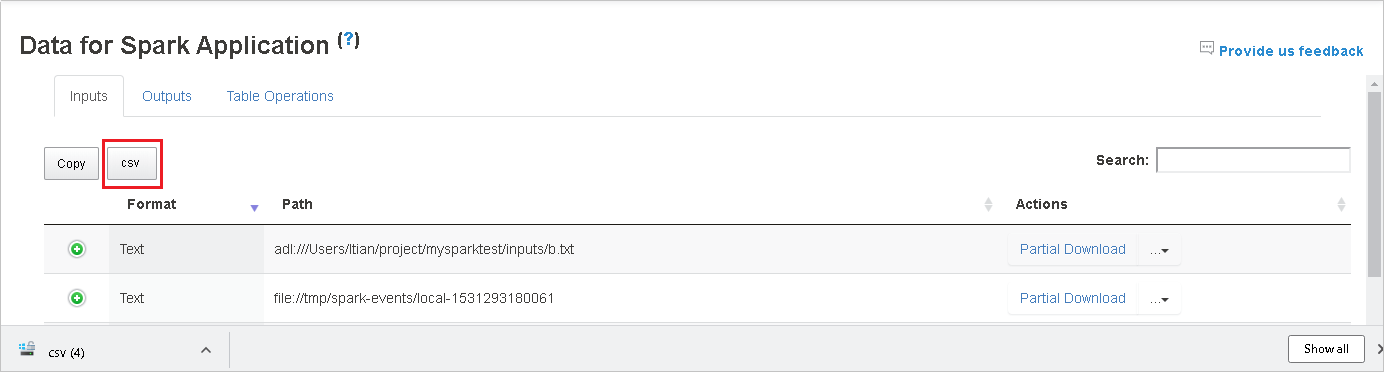
在 [搜尋] 欄位中輸入關鍵字來搜尋數據。 搜尋結果會立即顯示。
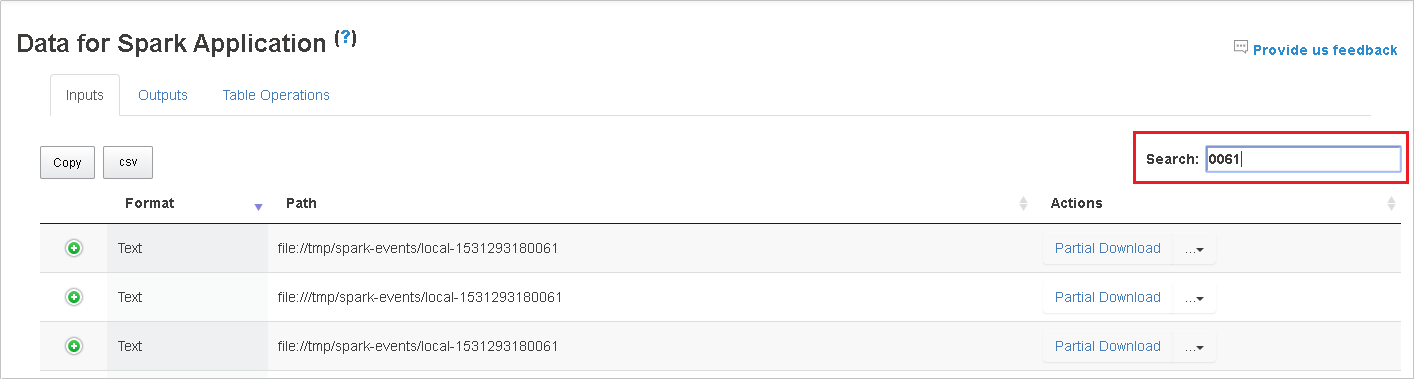
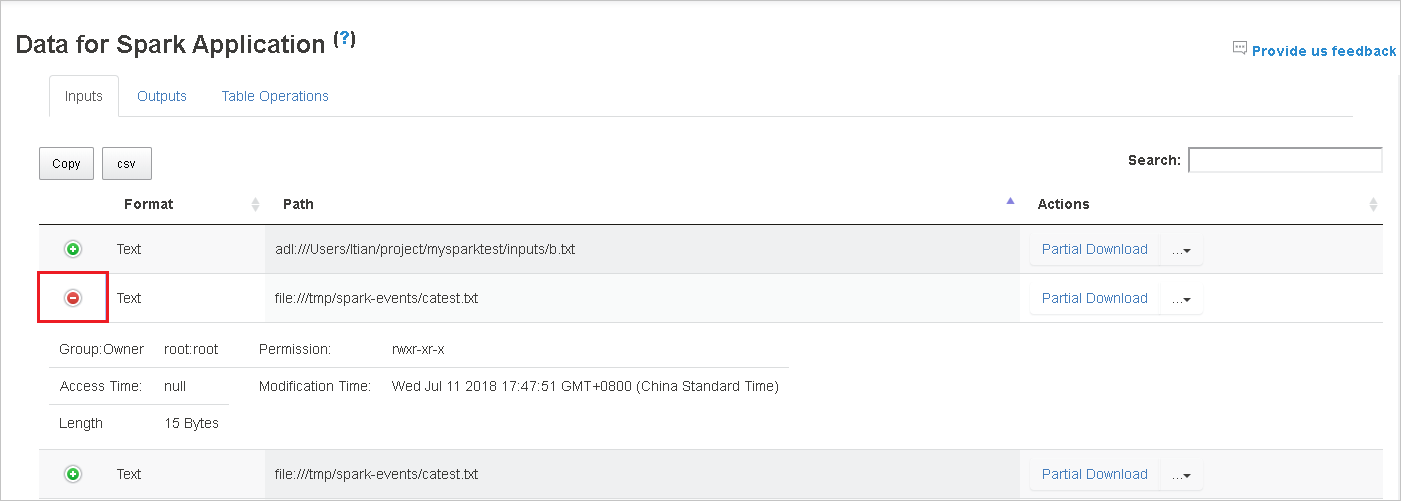
選取資料行標頭來排序數據表。 選取加號展開數據列以顯示更多詳細數據。 選取減號以折疊數據列。
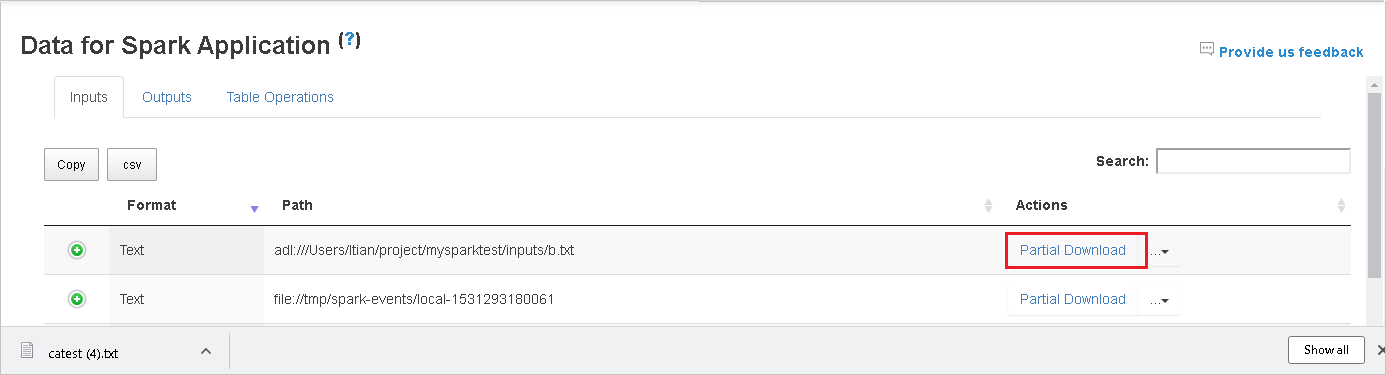
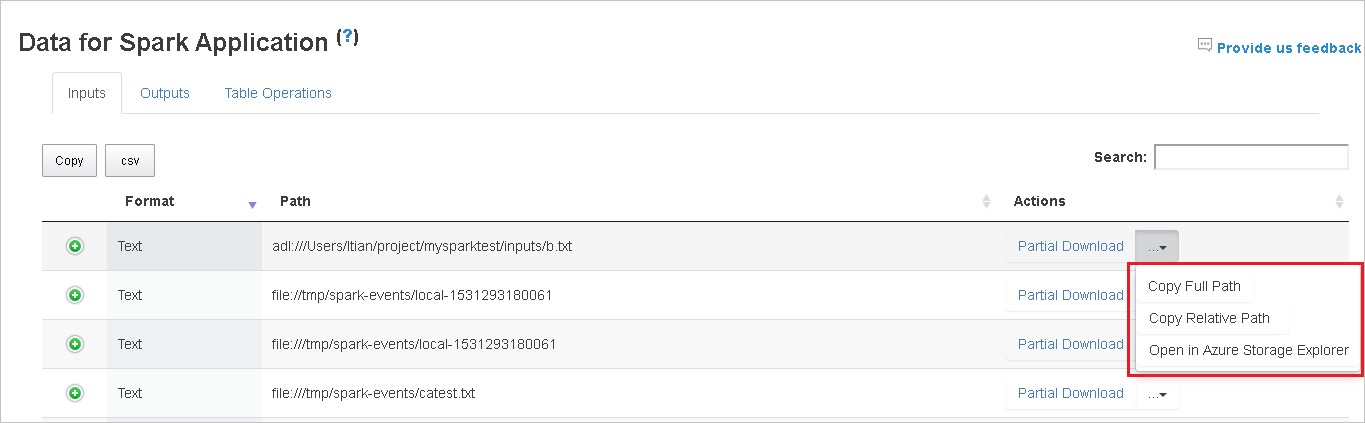
選取右側的 [ 部分下載] 按鈕,以 下載單一檔案。 選取的檔案將會在本機下載。 如果檔案已不存在,這會開啟新的索引標籤以顯示錯誤訊息。
選取 [複製完整路徑] 或 [複製相對路徑] 選項,從下載功能表展開,以複製完整路徑 或 相對路徑 。 針對 Azure Data Lake 儲存體 檔案,選取 [在 Azure 儲存體 Explorer 中開啟],以啟動 Azure 儲存體 Explorer,並在登入後找出資料夾。
如果單一頁面上顯示的數據列太多,請選取數據表底部要巡覽的頁碼。

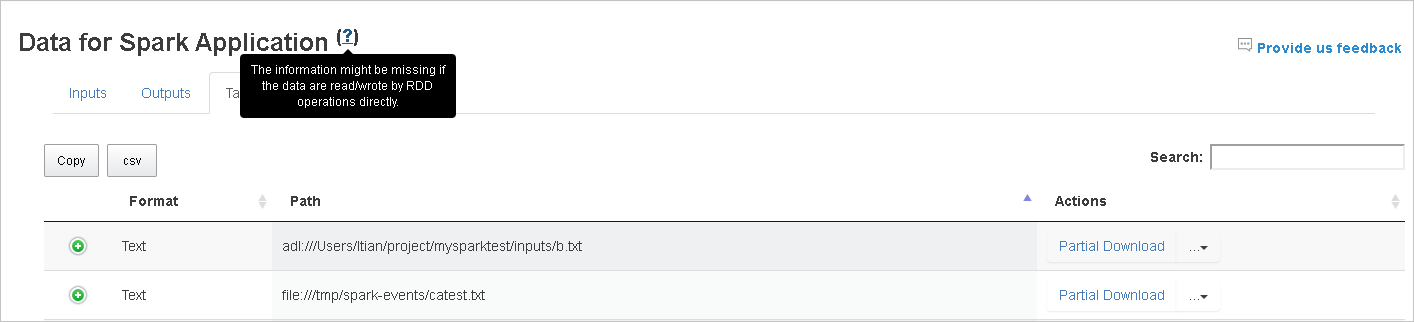
如需詳細資訊,請將滑鼠停留在Spark應用程式的數據旁或選取問號,以顯示工具提示。
若要傳送問題的意見反應,請選取 [ 提供意見反應]。
使用 Spark 歷程記錄伺服器中的 [圖形] 索引標籤
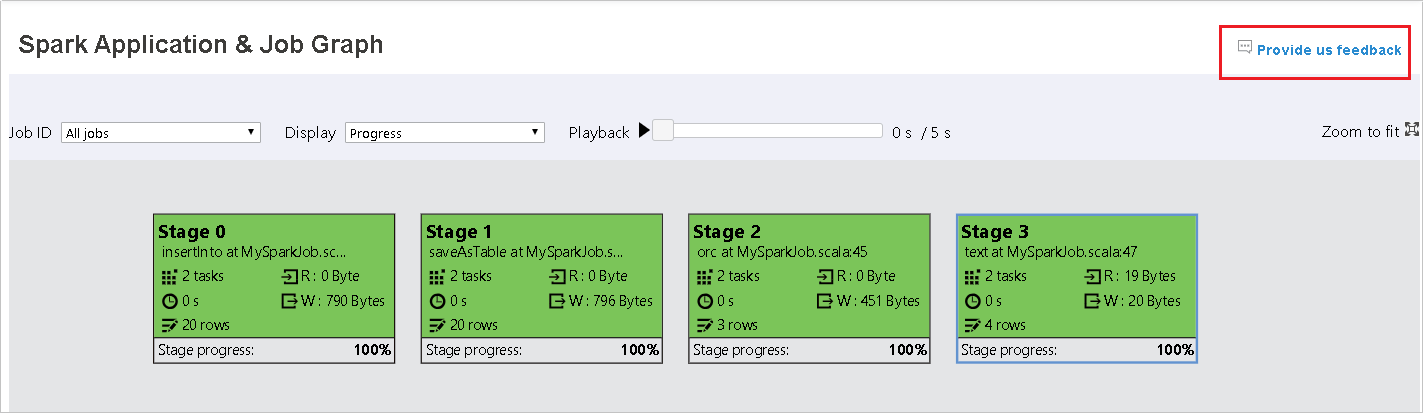
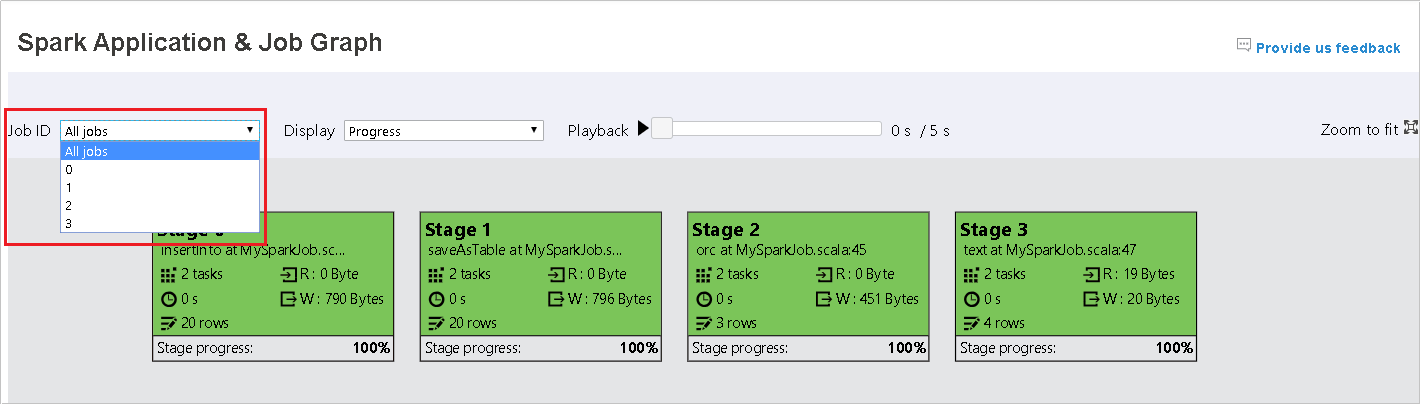
選取作業標識碼,然後選取 工具功能表上的 [圖形 ],以查看作業圖形。 根據預設,圖表會顯示所有作業。 使用 [作業標識符 ] 下拉功能表來篩選結果。
默認會選取 [進度 ]。 選取 [顯示] 下拉功能表中的 [讀取] 或 [寫入] 來檢查數據流。
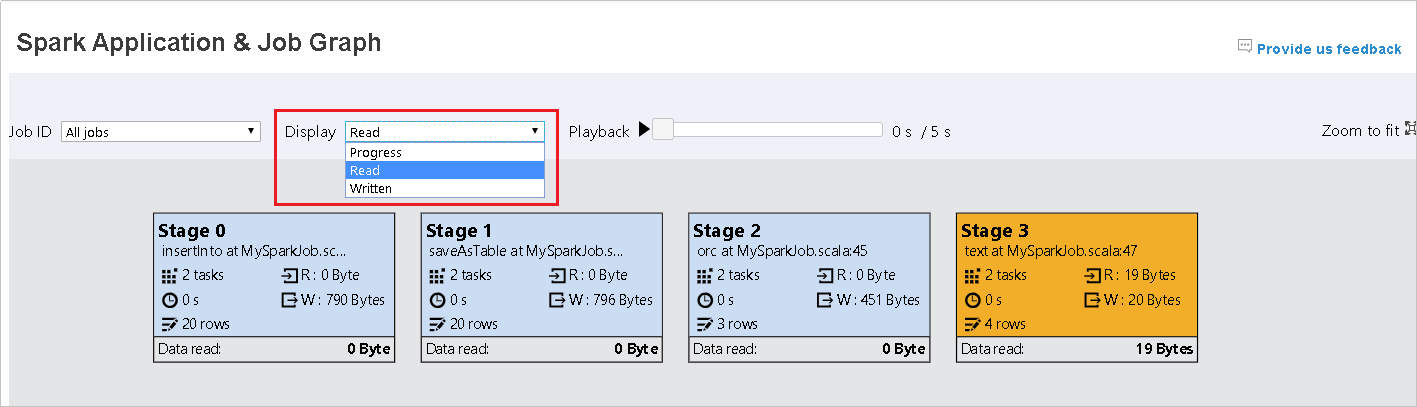
每個工作的背景色彩都會對應到熱度圖。

Color 描述 綠色 作業已順利完成。 Orange 工作失敗,但這不會影響作業的最終結果。 這些工作有重複或重試實例,稍後可能會成功。 藍色 工作正在執行。 白色 工作正在等候執行,或已略過階段。 紅色 工作失敗。 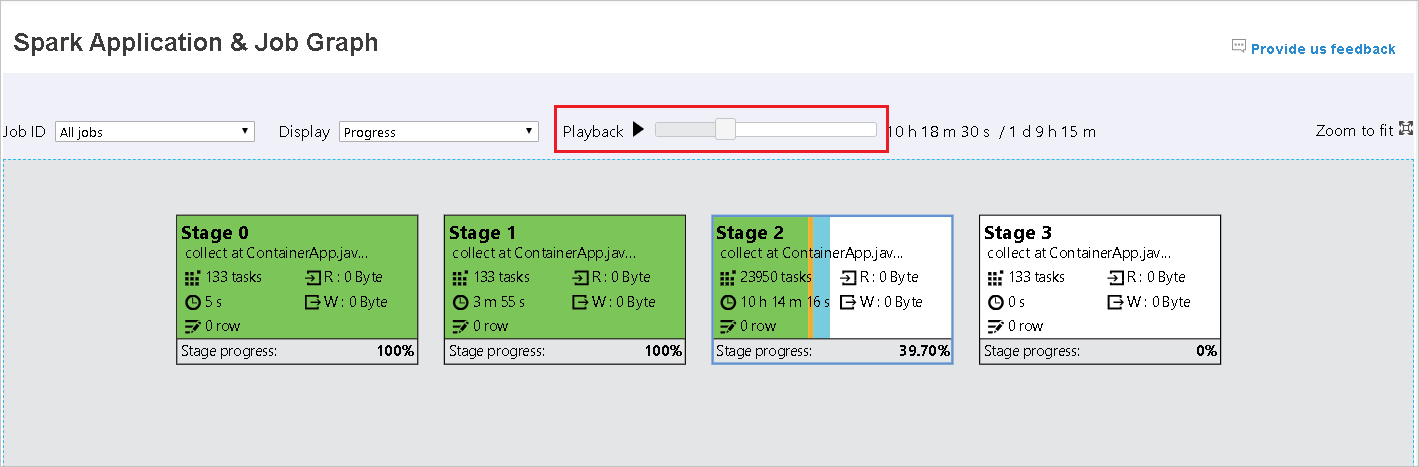
略過的階段會以白色顯示。
注意
播放適用於已完成的工作。 選取 [ 播放] 按鈕以播放作業。 選取 [停止] 按鈕,隨時停止作業。 當作業播放時,每個工作都會依色彩顯示其狀態。 不完整的工作不支援播放。
捲動以放大或縮小作業圖形,或選取 [ 縮放] 以符合 螢幕大小。
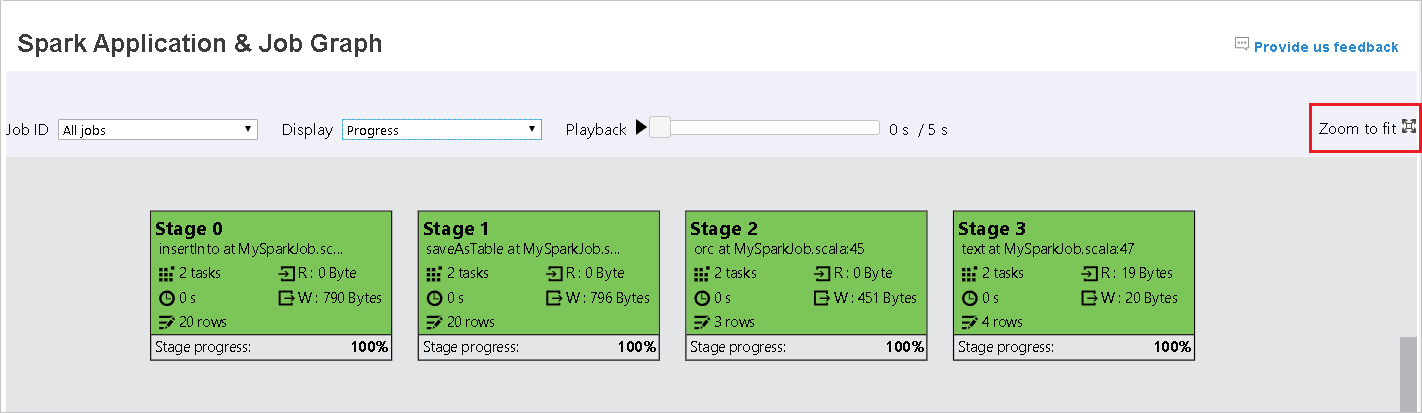
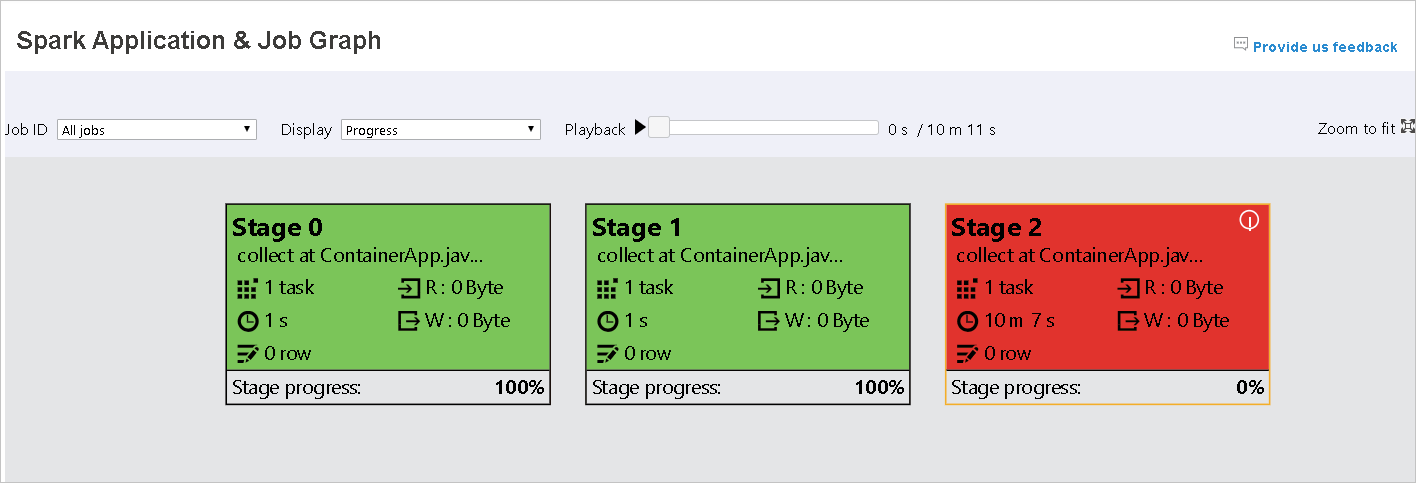
當工作失敗時,將滑鼠停留在圖形節點上以查看工具提示,然後選取階段以在新頁面中開啟。
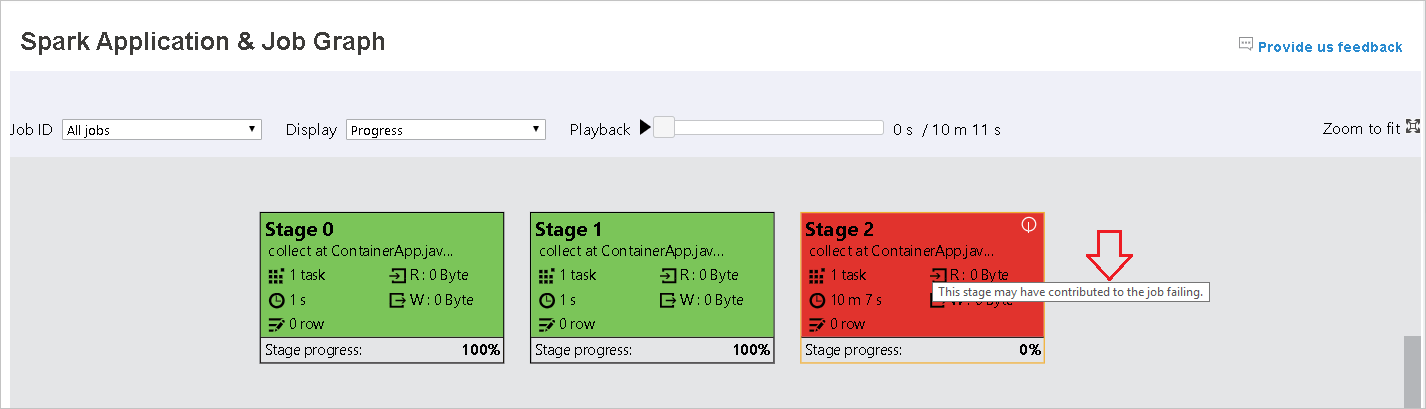
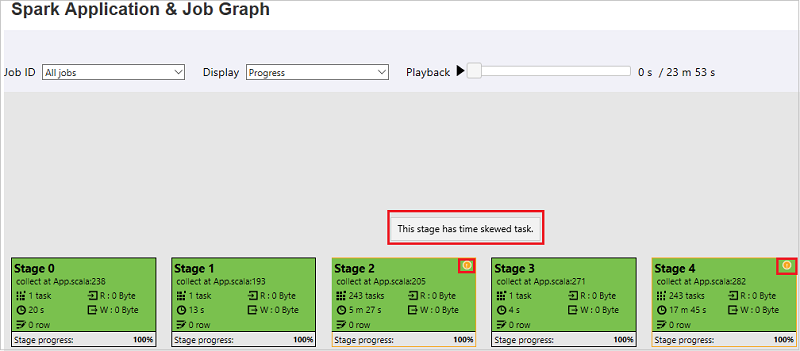
在 [Spark 應用程式與作業圖形] 頁面上,如果工作符合下列條件,階段會顯示工具提示和小型圖示:
數據扭曲:此階段內所有工作的數據讀取大小平均數據讀取大小 > * 2 和數據 讀取大小 > 10 MB。
時間扭曲:此階段內所有工作的運行時間平均運行時間 > * 2,運行時間 > 2 分鐘。
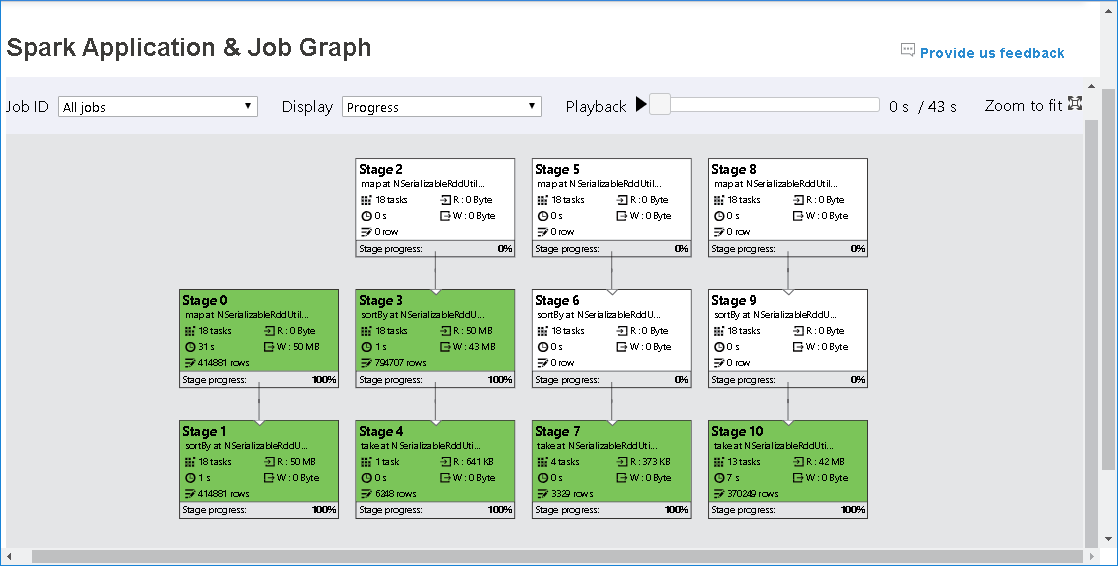
工作圖形節點會顯示每個階段的下列資訊:
識別碼
名稱或描述
任務總數
讀取的資料:輸入大小和隨機讀取大小的總和
數據寫入:輸出大小和隨機寫入大小的總和
運行時間:第一次嘗試開始時間與上次嘗試完成時間之間的時間
數據列計數:輸入記錄、輸出記錄、隨機讀取記錄和隨機寫入記錄的總和
進度
注意
根據預設,作業圖形節點會顯示每個階段上次嘗試的信息(階段運行時間除外)。 但在播放期間,作業圖形節點會顯示每個嘗試的相關信息。
注意
針對數據讀取和數據寫入大小,我們使用 1MB = 1000 KB = 1000 * 1000 個字節。
選取 [提供意見反應] 以傳送問題的意見反應。
使用 Spark 歷程記錄伺服器中的 [診斷] 索引標籤
選取作業標識碼,然後選取 工具功能表上的 [診斷 ],以查看作業診斷檢視。 [診斷] 索引標籤包含 [資料扭曲]、[時間扭曲] 和 [執行程式使用分析]。
選取索引標籤,以檢閱數據扭曲、時間扭曲和執行程式使用分析。
資料扭曲
選取 [ 資料扭曲 ] 索引標籤。對應的扭曲工作會根據指定的參數顯示。
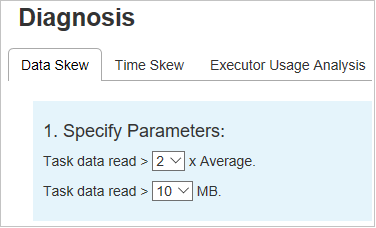
指定參數
[指定參數] 區段會顯示用來偵測數據扭曲的參數。 默認規則為:工作數據讀取大於平均工作數據讀取的三倍,而工作數據讀取超過 10 MB。 如果您想要為扭曲的工作定義自己的規則,您可以選擇參數。 扭曲階段和扭曲圖表區段將會隨之更新。
扭曲階段
[扭曲階段] 區段會顯示已扭曲工作符合指定準則的階段。 如果某個階段中有多個扭曲的任務, [扭曲階段 ] 區段只會顯示最扭曲的工作(也就是數據扭曲的最大數據)。
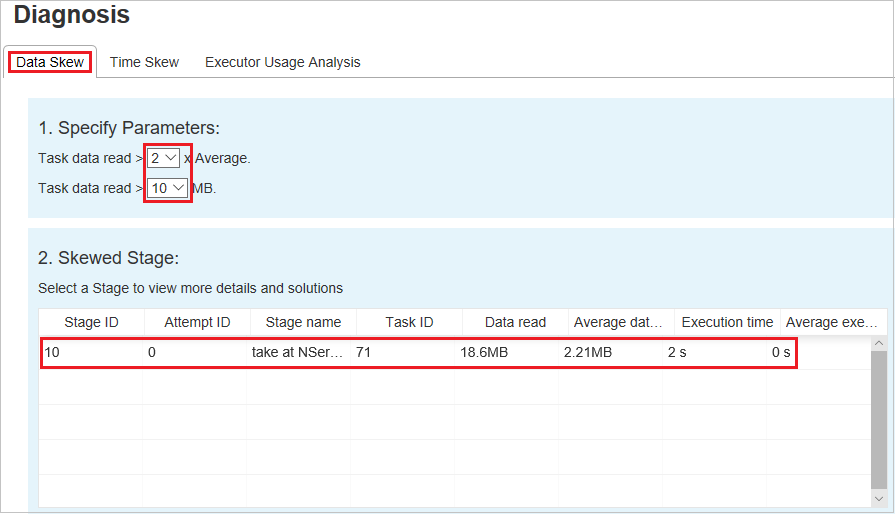
扭曲圖表
當您在 扭曲階段 數據表中選取數據列時, 扭曲圖表 會根據數據讀取和運行時間顯示更多工作分佈詳細數據。 扭曲的工作會以紅色標示,而一般工作會以藍色標示。 為了考慮效能,圖表最多會顯示100個範例工作。 工作詳細數據會顯示在右下方面板中。
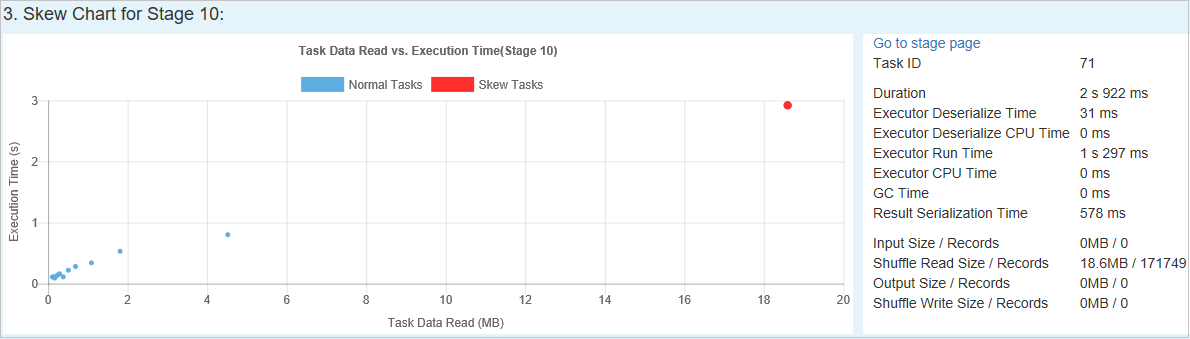
時間扭曲
[時間扭曲] 索引標籤會根據工作執行時間顯示扭曲的工作。
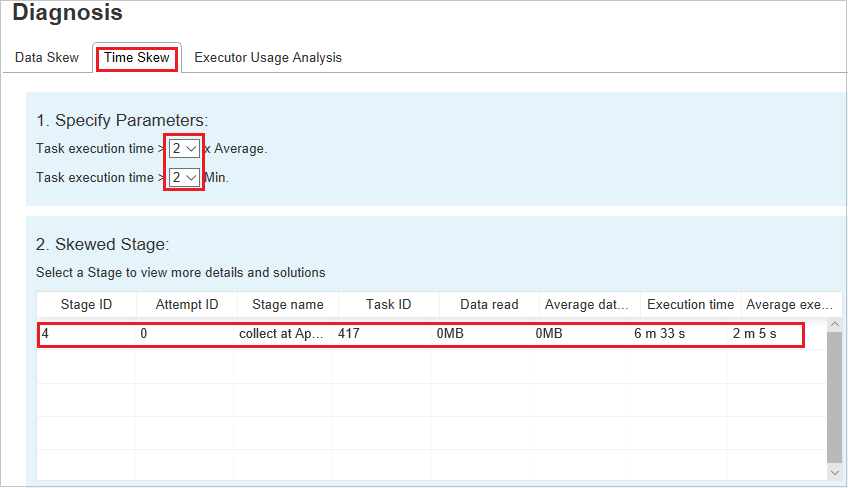
指定參數
[ 指定參數] 區段會顯示用來偵測時間扭曲的參數。 默認規則為:工作運行時間大於平均運行時間的三倍,而工作運行時間大於 30 秒。 您可以根據您的需求變更參數。 扭曲階段和扭曲圖表會顯示對應的階段和工作資訊,就像在 [數據扭曲] 索引標籤中一樣。
當您選取 [時間扭曲] 時,篩選的結果會顯示在 [扭曲階段 ] 區段中,根據 [ 指定參數 ] 區段中所設定的參數。 當您在 [扭曲階段 ] 區段中選取一個專案時,對應的圖表會在第三個區段中草擬,而工作詳細數據會顯示在右下方面板中。
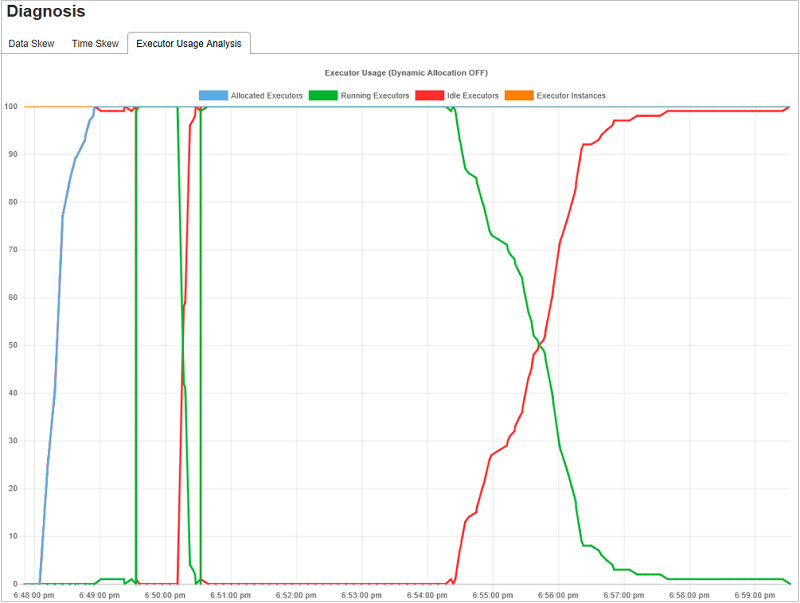
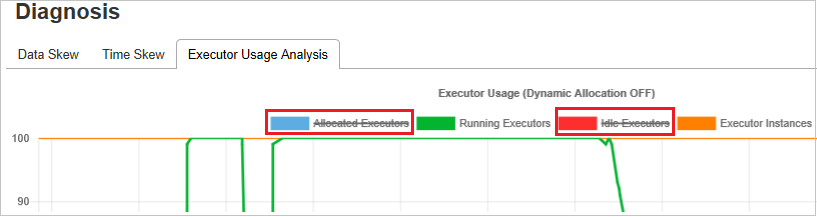
執行程式使用分析圖表
執行 程式使用狀況圖表 會顯示作業的實際執行程式配置和執行狀態。
當您選取 [執行程式使用分析] 時,會起草四種不同的執行程式使用方式曲線:已配置的執行程式、執行執行程式、閑置執行程式,以及最大執行程序實例。 每個 新增 的執行程式或 已移除 的執行程式事件都會增加或減少配置的執行程式。 您可以在 [作業] 索引標籤中檢查 [事件時程表] 以取得更多比較。
選取色彩圖示以選取或取消選取所有草稿中的對應內容。
常見問題集
如何? 還原為社群版本?
若要還原為社群版本,請執行下列步驟。
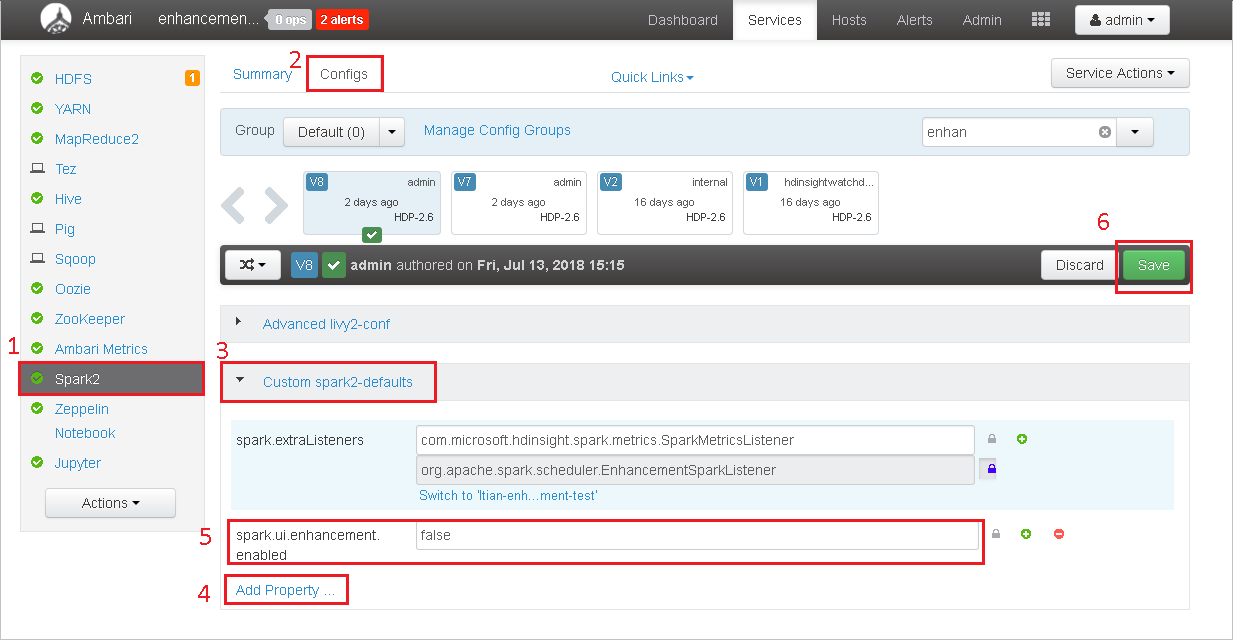
在Ambari中開啟叢集。
流覽至 Spark2> 組態。
選取 [自定義 spark2-defaults]。
選取 [ 新增屬性...]。
新增 spark.ui.enhancement.enabled=false,然後儲存它。
屬性現在會設定為 false 。
選取儲存 以儲存設定。
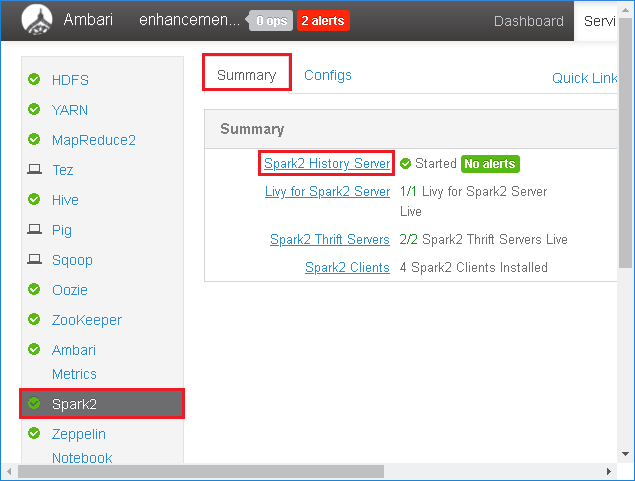
選取 左側面板中的 [Spark2 ]。 然後,在 [ 摘要] 索引標籤上,選取 [Spark2 記錄伺服器]。
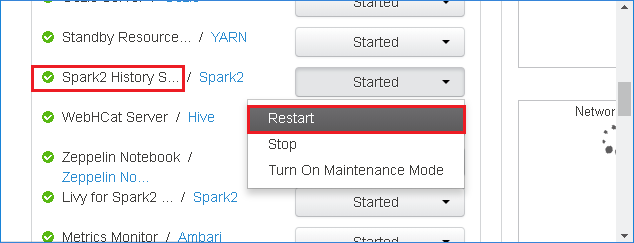
若要重新啟動 Spark 歷程記錄伺服器,請選取 Spark2 記錄伺服器右邊的 [已啟動] 按鈕,然後從下拉功能表中選取 [重新啟動]。
重新整理 Spark 歷程記錄伺服器 Web UI。 它會還原為社群版本。
如何? 上傳 Spark 記錄伺服器事件以將其回報為問題?
如果您在 Spark 歷程記錄伺服器中遇到錯誤,請執行下列步驟來報告事件。
選取 [Spark 歷程記錄伺服器 Web UI] 中的 [下載],以 下載事件。
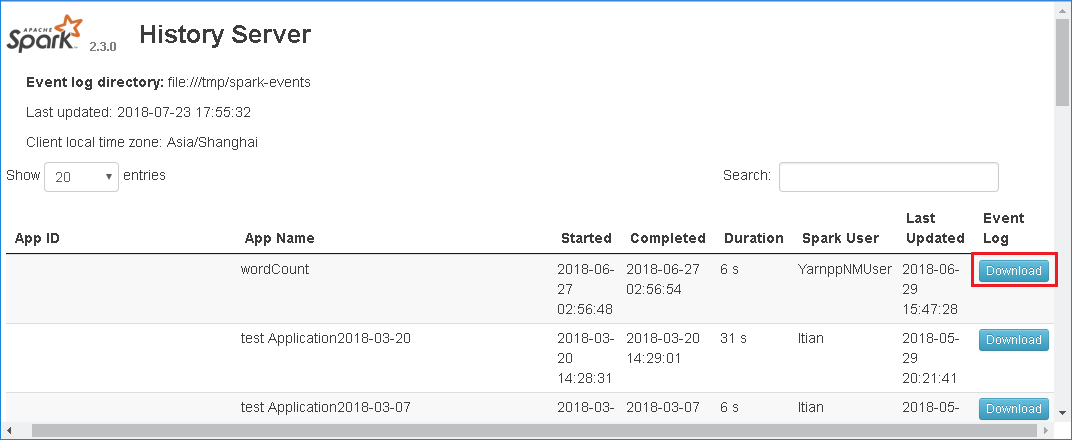
從 [Spark 應用程式與作業圖表] 頁面選取 [提供意見反應]。
提供錯誤的標題和描述。 然後,將.zip檔案拖曳至編輯欄位,然後選取 [ 提交新問題]。
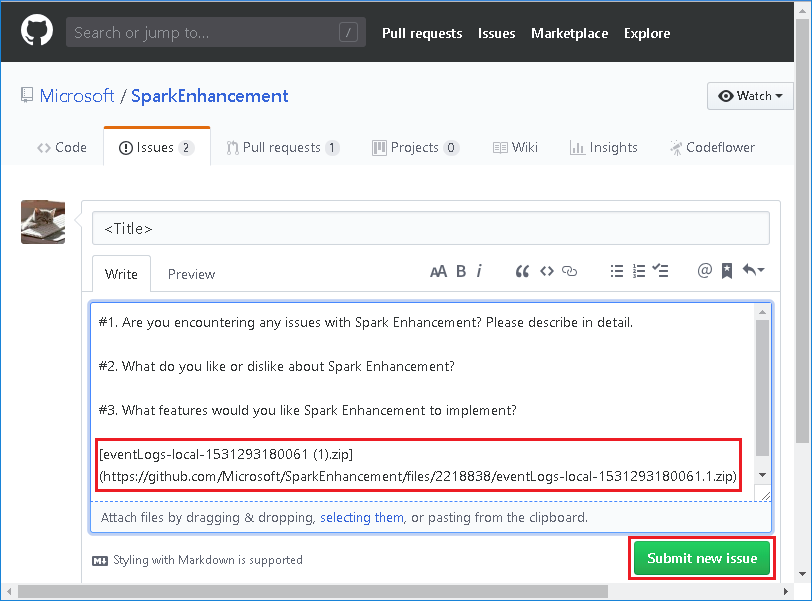
如何? 在 Hotfix 案例中升級.jar檔案?
如果您要使用 Hotfix 升級,請使用下列腳本來升級 spark-enhancement.jar*。
upgrade_spark_enhancement.sh:
#!/usr/bin/env bash
# Copyright (C) Microsoft Corporation. All rights reserved.
# Arguments:
# $1 Enhancement jar path
if [ "$#" -ne 1 ]; then
>&2 echo "Please provide the upgrade jar path."
exit 1
fi
install_jar() {
tmp_jar_path="/tmp/spark-enhancement-hotfix-$( date +%s )"
if wget -O "$tmp_jar_path" "$2"; then
for FILE in "$1"/spark-enhancement*.jar
do
back_up_path="$FILE.original.$( date +%s )"
echo "Back up $FILE to $back_up_path"
mv "$FILE" "$back_up_path"
echo "Copy the hotfix jar file from $tmp_jar_path to $FILE"
cp "$tmp_jar_path" "$FILE"
"Hotfix done."
break
done
else
>&2 echo "Download jar file failed."
exit 1
fi
}
jars_folder="/usr/hdp/current/spark2-client/jars"
jar_path=$1
if ls ${jars_folder}/spark-enhancement*.jar 1>/dev/null 2>&1; then
install_jar "$jars_folder" "$jar_path"
else
>&2 echo "There is no target jar on this node. Exit with no action."
exit 0
fi
使用方式
upgrade_spark_enhancement.sh https://${jar_path}
範例
upgrade_spark_enhancement.sh https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar
使用來自 Azure 入口網站 的bash檔案
啟動 Azure 入口網站,然後選取您的叢集。
-
屬性 值 指令碼類型 -自 定義 名稱 UpgradeJar Bash 指令碼 URI https://hdinsighttoolingstorage.blob.core.windows.net/shsscriptactions/upgrade_spark_enhancement.sh節點類型 主管、背景工作 參數 https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar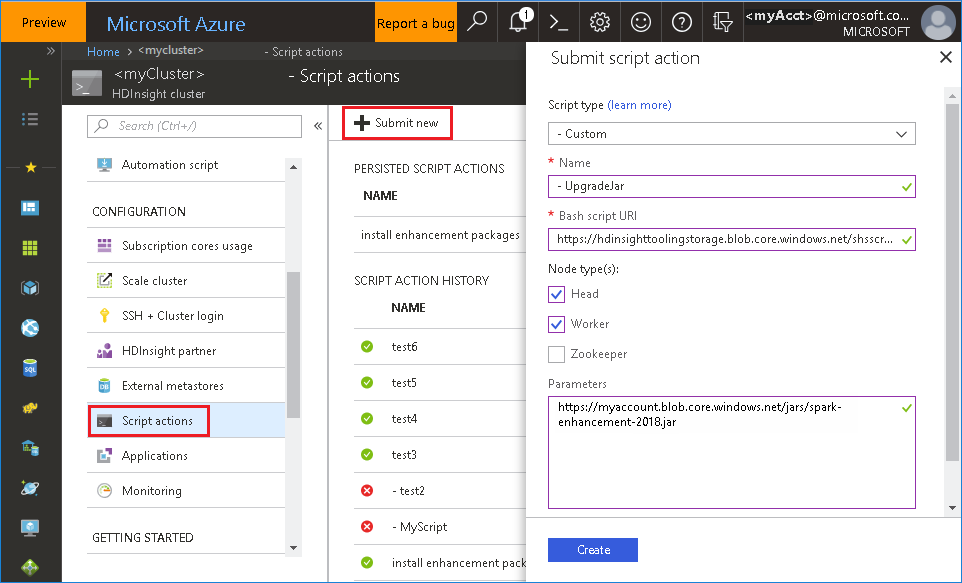
已知問題
目前,Spark 歷程記錄伺服器僅適用於 Spark 2.3 和 2.4。
使用 RDD 的輸入和輸出資料不會顯示在 [ 資料 ] 索引標籤中。
下一步
建議
如果您在使用此工具時有任何意見反應或遇到任何問題,請傳送電子郵件給 (hdivstool@microsoft.com)。