修正 Azure HDInsight 中的 Apache Hive 記憶體不足錯誤
了解如何透過設定 Hive 記憶體設定,修正處理大型資料表時的 Apache Hive 記憶體不足 (OOM) 錯誤。
針對大型資料表執行 Apache Hive 查詢
某個客戶執行了 Hive 查詢:
SELECT
COUNT (T1.COLUMN1) as DisplayColumn1,
…
…
….
FROM
TABLE1 T1,
TABLE2 T2,
TABLE3 T3,
TABLE5 T4,
TABLE6 T5,
TABLE7 T6
where (T1.KEY1 = T2.KEY1….
…
…
此查詢的一些細微差異:
- T1 是大型資料表 TABLE1 的別名,其中包含多個 STRING 資料行類型。
- 其他資料表的規模沒有那麼大,但還是有許多資料行。
- 所有資料表都會彼此聯結,在某些情況下,是透過 TABLE1 和其他資料表中的多個資料行來聯結。
此 Hive 查詢在一個有 24 個節點的 A3 HDInsight 叢集上花費 26 分鐘完成執行。 該客戶注意到下列警告訊息:
Warning: Map Join MAPJOIN[428][bigTable=?] in task 'Stage-21:MAPRED' is a cross product
Warning: Shuffle Join JOIN[8][tables = [t1933775, t1932766]] in Stage 'Stage-4:MAPRED' is a cross product
在使用 Apache Tez 執行引擎的情況下, 相同查詢執行了 15 分鐘,然後擲回下列錯誤:
Status: Failed
Vertex failed, vertexName=Map 5, vertexId=vertex_1443634917922_0008_1_05, diagnostics=[Task failed, taskId=task_1443634917922_0008_1_05_000006, diagnostics=[TaskAttempt 0 failed, info=[Error: Failure while running task:java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
at
org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:172)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at
org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Java heap space
當使用較大的虛擬機器 (例如 D12) 時,該錯誤仍然存在。
針對記憶體不足錯誤進行偵錯
我們的支援小組和工程小組一起發現造成記憶體不足錯誤的其中一個問題是一個 Apache JIRA 中所述的已知問題:
「當 hive.auto.convert.join.noconditionaltask = true 時,我們會檢查 noconditionaltask.size,而如果對應聯結中的資料表大小總和小於 noconditionaltask.size,則計畫會產生對應聯結,其問題在於如果輸入大小的總和小於小邊界查詢的 noconditionaltask 大小,將會遇到 OOM,則計算不會考慮不同 HashTable 實作所產生的額外負荷。」
hive-site.xml 檔案中的 hive.auto.convert.join.noconditionaltask 已設定為 true:
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
<description>
Whether Hive enables the optimization about converting common join into mapjoin based on the input file size.
If this parameter is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the
specified size, the join is directly converted to a mapjoin (there is no conditional task).
</description>
</property>
對應聯結有可能是「Java 堆積空間」記憶體不足錯誤的原因。 如 HDInsight 中的部落格文章 Hadoop Yarn 記憶體設定中所述,當 Tez 執行引擎使用實際屬於 Tez 容器的堆積空間時, 查看下面說明 Tez 容器記憶體的影像。
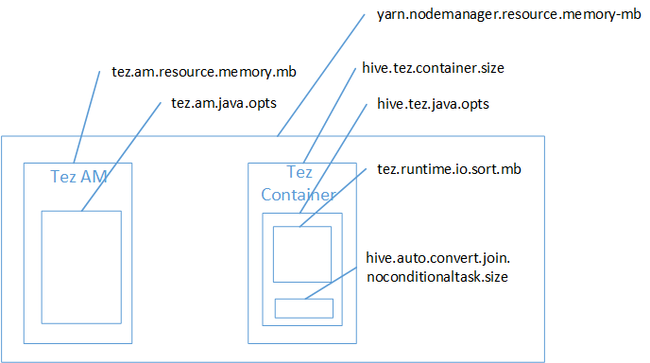
如部落格文章所建議,下列兩個記憶體設定會定義堆積的容器記憶體:hive.tez.container.size 和 hive.tez.java.opts。 從我們的經驗來看,記憶體不足例外狀況並不代表容器大小太小。 它表示 Java 堆積大小 (hive.tez.java.opts) 太小。 因此,每當您看到記憶體不足時,可嘗試增加 hive.tez.java.opts。 必要時,您可能需要增加 hive.tez.container.size。 Java.opts 設定應該大約為 container.size 的 80%。
注意
hive.tez.java.opts 設定必須一律小於 hive.tez.container.size。
由於 D12 機器具有 28 GB 記憶體,因此我們決定使用 10 GB (10240 MB) 的容器大小並指派 80% 給 java.opts:
SET hive.tez.container.size=10240
SET hive.tez.java.opts=-Xmx8192m
使用新設定之後,查詢順利在 10 分鐘內完成執行。
下一步
遇到 OOM 錯誤不一定表示容器大小太小。 相反地,您應該設定記憶體設定,以增加堆積大小,至少是容器記憶體大小的 80%。 若要了解如何將 Hive 查詢最佳化,請參閱將 HDInsight 中 Apache Hadoop 的 Apache Hive 查詢最佳化。